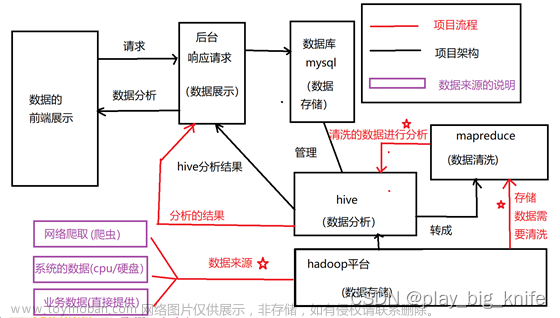
一.Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop的核心是yarn、HDFS和Mapreduce。yarn是资源管理系统,实现资源调度,yarn是Hadoop2.0中的资源管理系统,总体上是master/slave结构。对于yarn可以粗浅将其理解为进行资源分配的。 Hdfs是分布式文件存储系统,用于存储海量数据;mapreduce是并行处理框架,实现任务分解和调度。Hadoop可用于搭建大型数据仓库,对海量数据进行存储、分析、处理和统计。
二.Hive
想要使用HDFS分布式文件存储系统,必须通过Hive进行。Hive也是产品经理经常能听到的词。也可以浅显地将Hive理解为数据仓库。
Hive 是构建在Hadoop HDFS上的数据仓库,可以将结构化的数据文件映射成一张数据库表,并提供类SQL查询功能,主要完成海量数据的分析和计算。本质用于将HQL(Hive SQL)转化成MapReduce任务来执行。
优点:简化数据开发流程及提高了效率。
Hive表其实是HDFS的目录/文件
Hive中的元数据包括:表的名字、表的列、分区及属性、表的数据所在目录等
三.Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。
四.Flink
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算
Flink可以同时进行批处理和流处理。
批处理和流处理是两种截然不同的数据处理方式,Flink更适合流处理。
核心特点:
- 高吞吐、低延迟
- 结果的准确性
- 精确一次(exactly-once)的状态一致性保证
- 可以与众多常用存储系统连接
- 高可用,支持动态扩展
Flink经常会和kafka结合使用,能一条条地处理数据。
五.Spark
Spark streaming是spark体系中的一个面向流数据的流式实时计算框架;可以实现高吞吐量的,具备容错机制的实时流数据的处理;
Spark streaming接收kafka、Flume、HDFS、套接字等各种来源实时输入数据,进行处理,处理后结构数据可存储到文件系统、数据库,或显示在可视化图像中;Dashboards:类似图形接收界面
Spark和hive结合的比较好,spark和Flink都是分布式流数据流引擎,能对集群资源进行分配使用,确保大计算快速准确完成。
六.Hbase
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBASE 技术可在廉价 PC Server 上搭建起大规模结构化存储集群.
HDFS是文件系统,能存储1G以上大量数据,HBase在HDFS之上提供了高并发的随机写和支持实时查询,这是HDFS不具备的。
HDFS是列式存储,查询更快。
一般Hbase会配合HDFS作为大数据架构。
七.ES
Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;通过倒排索引进行查询数据的,极大的提高了查询效率;
ES提供全文检索,大数据架构中用ES作为向前端提供接口计算的数据库。文章来源:https://www.toymoban.com/news/detail-828023.html
测试可以配合使用Kibana工具进行索引查询ES数据,验证其数据的正确性。文章来源地址https://www.toymoban.com/news/detail-828023.html
到了这里,关于大数据系统常用组件理解(Hadoop/hive/kafka/Flink/Spark/Hbase/ES)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!