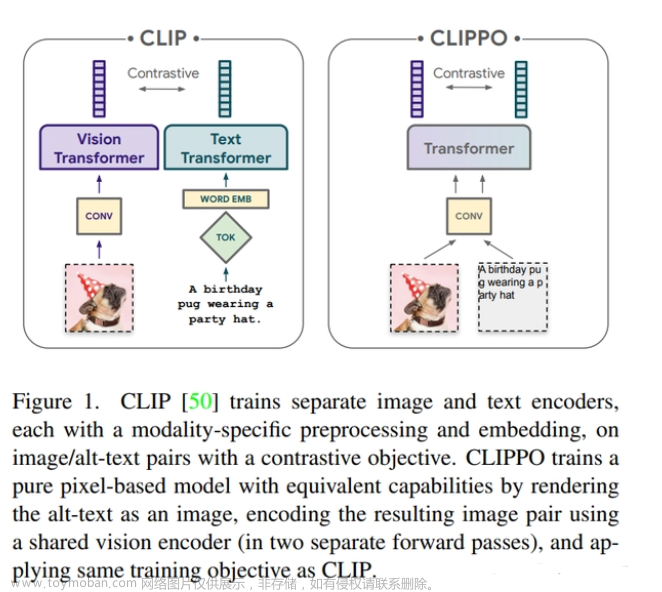
人工智能大模型的技术框架主要有以下几种:
-
TensorFlow:这是一个由Google Brain团队开发的开源库,用于进行高性能数值计算,特别是用于训练和运行深度学习模型。TensorFlow提供了一种称为计算图的编程模型,它允许用户定义复杂的计算并自动计算梯度。此外,TensorFlow还提供了一组丰富的工具,用于可视化模型的结构和性能。
-
PyTorch:这是一个由Facebook的AI研究团队开发的开源库,用于进行深度学习和其他形式的机器学习。与TensorFlow相比,PyTorch的设计更加灵活和直观,它允许用户在运行时更改计算图。此外,PyTorch还提供了一种简洁的编程模型,使得代码更容易理解和调试。
-
Keras:这是一个用于深度学习的高级API,可以运行在TensorFlow、Theano和CNTK等底层引擎之上。Keras的设计理念是提供一种简单和快速的方式来创建和训练深度学习模型,而不需要了解底层的详细实现。
-
Theano:这是一个用于深度学习的开源库,由蒙特利尔大学的MILA实验室开发。Theano可以自动计算梯度,并提供了一种优化计算图的方式,以提高运行效率。然而,由于TensorFlow和PyTorch的流行,Theano的开发已经在2017年停止。
-
MXNet:这是一个用于深度学习的开源库,由亚马逊Web服务(AWS)支持。MXNet提供了一种灵活的编程模型,允许用户在运行时更改计算图。此外,MXNet还提供了一种高效的分布式训练方法,可以在多台机器上并行训练模型。
-
ONNX (Open Neural Network Exchange):这是一个开放的模型交换格式,允许用户在不同的深度学习框架之间转换模型。ONNX支持大量的深度学习框架,包括PyTorch、TensorFlow、MXNet等。
-
OpenAI’s GPT Models:OpenAI GPT模型是一种基于Transformer的大型语言模型,用于生成自然语言文本。目前,我使用的是OpenAI的GPT-4模型。
TensorFlow如何使用?
TensorFlow是一个强大的深度学习框架,可以用来创建各种各样的神经网络模型。以下是一个简单的TensorFlow使用示例,该示例显示了如何创建和训练一个用于识别手写数字的简单神经网络(使用MNIST数据集):
首先,需要导入TensorFlow和其他必要的库:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
然后,我们加载MNIST数据集,并对数据进行预处理:
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 将图像数据从 (28, 28) 的数组转换为 (28, 28, 1) 的三维张量
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
# 将像素值从整数转换为浮点数,并将其归一化到 0-1 的范围
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# 将目标(标签)转换为 one-hot 编码
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
接下来,我们创建一个神经网络模型:
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
然后,我们编译模型,并指定损失函数和优化器:
model.compile(loss=tf.keras.losses.categorical_crossentropy,
optimizer=tf.keras.optimizers.Adadelta(),
metrics=['accuracy'])
最后,我们训练模型,并在测试数据上评估其性能:
model.fit(x_train, y_train,
batch_size=128,
epochs=10,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
以上就是一个简单的TensorFlow使用示例。实际上,TensorFlow的功能远不止这些,它还支持分布式计算、自动梯度计算、GPU加速等高级功能。
PyTorch是一个用于深度学习的开源库,它的设计理念是灵活和直观,提供了一种简洁的编程模型,使得代码更容易理解和调试。以下是一个简单的PyTorch使用示例,该示例显示了如何创建和训练一个用于识别手写数字的简单神经网络(使用MNIST数据集):
首先,需要导入PyTorch和其他必要的库:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.optim import Adam
然后,我们定义一个神经网络模型:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
接下来,我们加载MNIST数据集,并对数据进行预处理:
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('./data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('./data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1, batch_size=64)
test_loader = torch.utils.data.DataLoader(dataset2, batch_size=1000)
然后,我们创建一个模型实例,并指定优化器:
model = Net()
optimizer = Adam(model.parameters())
最后,我们定义一个训练循环,并在每个epoch后在测试数据上评估模型的性能:文章来源:https://www.toymoban.com/news/detail-828135.html
for epoch in range(1, 11):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
以上就是一个简单的PyTorch使用示例。实际上,PyTorch的功能远不止这些,它还支持动态计算图、自动梯度计算、GPU加速等高级功能。文章来源地址https://www.toymoban.com/news/detail-828135.html
到了这里,关于【AIGC扫盲】人工智能大模型快速入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!