1.背景介绍
1. 背景介绍
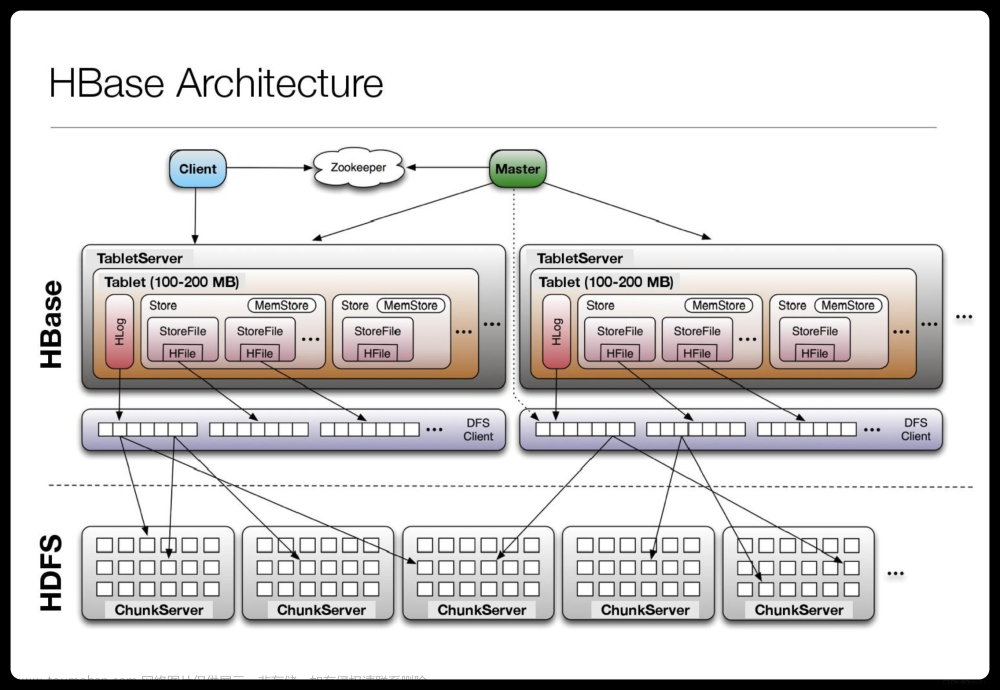
HBase是一个分布式、可扩展、高性能的列式存储系统,基于Google的Bigtable设计。它是Hadoop生态系统的一部分,可以与HDFS、MapReduce、ZooKeeper等组件集成。HBase具有高可靠性、高性能和高可扩展性,适用于大规模数据存储和实时数据访问场景。
在HBase中,数据以行为单位存储,每行数据由一个行键(row key)和一组列族(column family)组成。列族是一组相关列的集合,列族内的列共享同一个存储区域。HBase支持自动分区和负载均衡,可以在集群中添加或删除节点,实现数据的水平扩展。
HBase提供了一套CRUD操作接口,用于对数据进行创建、读取、更新和删除。在本章中,我们将详细介绍HBase的CRUD操作,包括API使用、代码实例和最佳实践。
2. 核心概念与联系
2.1 HBase核心概念
- 行键(row key):唯一标识数据行的字符串,用于在HBase中快速定位数据。
- 列族(column family):一组相关列的集合,列族内的列共享同一个存储区域。
- 列(column):列族内的具体数据项。
- 单元格(cell):列族内的一行数据。
- 版本(version):数据的版本号,用于区分不同时间点的数据。
- 时间戳(timestamp):数据的创建或更新时间。
2.2 HBase与Bigtable的关系
HBase是基于Google Bigtable设计的,它们在架构和功能上有很多相似之处。以下是HBase与Bigtable的主要联系:
- 分布式存储:HBase和Bigtable都采用分布式存储架构,可以在多个节点之间分布数据,实现高可用和高性能。
- 列式存储:HBase和Bigtable都采用列式存储方式,可以有效减少磁盘空间占用和I/O开销。
- 自动分区:HBase和Bigtable都支持自动分区,可以在集群中动态添加或删除节点,实现数据的水平扩展。
- 高可靠性:HBase和Bigtable都提供了高可靠性的数据存储和访问功能,如数据备份、自动故障恢复等。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 HBase数据模型
HBase数据模型包括行键、列族、列和单元格等概念。在HBase中,数据以行为单位存储,每行数据由一个行键(row key)和一组列族(column family)组成。列族是一组相关列的集合,列族内的列共享同一个存储区域。
3.2 HBase数据存储结构
HBase数据存储结构如下:
- Region:HBase中的数据存储单元,包含一定范围的行数据。Region内的数据按照行键顺序存储。
- Store:Region内的存储单元,包含一定范围的列数据。Store内的数据按照列族顺序存储。
- MemStore:Store内的内存缓存,用于暂存新写入的数据。当MemStore满了或者达到一定大小时,会触发刷新操作,将MemStore中的数据写入磁盘。
- HFile:磁盘上的存储文件,包含一定范围的列数据。HFile是HBase数据的基本存储单元。
3.3 HBase数据访问方式
HBase支持两种数据访问方式:顺序访问和随机访问。顺序访问是按照行键顺序读取数据,适用于大量连续行数据的读取场景。随机访问是通过行键直接定位数据,适用于小规模数据或者随机读取场景。
3.4 HBase数据写入和更新策略
HBase数据写入和更新策略如下:
- 写入:新数据写入MemStore,当MemStore满了或者达到一定大小时,触发刷新操作,将MemStore中的数据写入磁盘。
- 更新:更新操作包括删除和插入两种情况。删除操作将数据标记为删除,并在下一次刷新时将其从HFile中移除。插入操作将新数据写入MemStore,当MemStore满了或者达到一定大小时,触发刷新操作,将MemStore中的数据写入磁盘。
3.5 HBase数据读取策略
HBase数据读取策略如下:
- 顺序读取:从MemStore中读取数据,如果MemStore中没有数据,则从HFile中读取数据。顺序读取适用于大量连续行数据的读取场景。
- 随机读取:通过行键直接定位数据,适用于小规模数据或者随机读取场景。
4. 具体最佳实践:代码实例和详细解释说明
4.1 HBase CRUD操作API
HBase提供了一套CRUD操作接口,用于对数据进行创建、读取、更新和删除。以下是HBase CRUD操作API的概述:
-
创建表:
createTable -
插入数据:
put -
读取数据:
get -
更新数据:
increment、delete -
删除数据:
delete
4.2 HBase CRUD操作示例
以下是HBase CRUD操作的示例代码:
```java import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes;
import java.util.ArrayList; import java.util.List;
public class HBaseCRUDExample { public static void main(String[] args) throws Exception { // 1. 获取HBase配置 Configuration conf = HBaseConfiguration.create();
// 2. 获取HBase连接
Connection connection = ConnectionFactory.createConnection(conf);
// 3. 获取HBase表管理器
Admin admin = connection.getAdmin();
// 4. 创建HBase表
TableDescriptor tableDescriptor = new TableDescriptor(Bytes.toBytes("mytable"));
tableDescriptor.addFamily(Bytes.toBytes("cf1"));
admin.createTable(tableDescriptor);
// 5. 获取HBase表实例
Table table = connection.getTable(Bytes.toBytes("mytable"));
// 6. 插入数据
Put put = new Put(Bytes.toBytes("row1"));
put.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
table.put(put);
// 7. 读取数据
Get get = new Get(Bytes.toBytes("row1"));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes("cf1"), Bytes.toBytes("col1"));
System.out.println(Bytes.toString(value));
// 8. 更新数据
put.setRow(Bytes.toBytes("row1"));
put.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value2"));
table.put(put);
// 9. 删除数据
Delete delete = new Delete(Bytes.toBytes("row1"));
delete.addColumns(Bytes.toBytes("cf1"), Bytes.toBytes("col1"));
table.delete(delete);
// 10. 关闭连接
table.close();
connection.close();
}} ```
在上述示例中,我们分别演示了HBase表的创建、数据的插入、读取、更新和删除等CRUD操作。
5. 实际应用场景
HBase适用于大规模数据存储和实时数据访问场景,如:
- 日志存储:用于存储用户行为、访问日志等大量实时数据。
- 时间序列数据:用于存储设备传感器、IoT设备等时间序列数据。
- 实时数据分析:用于实时计算、聚合、分析等场景。
6. 工具和资源推荐
- HBase官方文档:https://hbase.apache.org/book.html
- HBase中文文档:https://hbase.apache.org/cn/book.html
- HBase源码:https://github.com/apache/hbase
- HBase社区:https://groups.google.com/forum/#!forum/hbase-user
7. 总结:未来发展趋势与挑战
HBase是一个高性能、高可扩展的列式存储系统,已经广泛应用于大规模数据存储和实时数据访问场景。未来,HBase将继续发展,提高性能、扩展性和可用性,以满足更多复杂场景的需求。
挑战:
- 性能优化:在大规模数据存储和实时数据访问场景下,HBase需要不断优化性能,以满足业务需求。
- 数据迁移:随着数据量的增加,HBase需要实现数据迁移、备份和恢复等操作,以保证数据的安全性和可用性。
- 多集群管理:HBase需要支持多集群管理,以满足不同业务需求的分布式存储和访问。
8. 附录:常见问题与解答
8.1 问题1:HBase如何实现数据的自动分区?
HBase通过Region分区实现数据的自动分区。Region是HBase数据存储单元,包含一定范围的行数据。当Region内的数据量达到一定阈值时,会自动拆分成多个新Region。这样,HBase可以在集群中动态添加或删除节点,实现数据的水平扩展。
8.2 问题2:HBase如何实现数据的高可靠性?
HBase通过多种机制实现数据的高可靠性:
- 数据备份:HBase支持多个RegionServer实例存储同一张表的数据,实现数据的多备份。
- 自动故障恢复:HBase支持RegionServer故障恢复,当RegionServer出现故障时,HBase会自动将Region分配给其他RegionServer,保证数据的可用性。
- 数据校验:HBase支持数据校验,可以检测数据的完整性和一致性,及时发现和修复数据错误。
8.3 问题3:HBase如何实现数据的高性能?
HBase通过多种机制实现数据的高性能:文章来源:https://www.toymoban.com/news/detail-828348.html
- 列式存储:HBase采用列式存储方式,可以有效减少磁盘空间占用和I/O开销。
- 缓存:HBase支持内存缓存,将新写入的数据暂存在MemStore中,当MemStore满了或者达到一定大小时,触发刷新操作,将MemStore中的数据写入磁盘。
- 顺序访问:HBase支持顺序访问,适用于大量连续行数据的读取场景。
8.4 问题4:HBase如何实现数据的水平扩展?
HBase通过多种机制实现数据的水平扩展:文章来源地址https://www.toymoban.com/news/detail-828348.html
- 自动分区:HBase通过Region分区实现数据的自动分区,当Region内的数据量达到一定阈值时,会自动拆分成多个新Region。
- 动态添加节点:HBase支持动态添加和删除RegionServer节点,实现数据的水平扩展。
- 负载均衡:HBase支持负载均衡,可以在集群中动态分配Region,实现数据的均匀分布和负载均衡。
到了这里,关于第二十二章:HBase的CRUD操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!