Maxwell+RabbitMq实现数据同步
一、概述
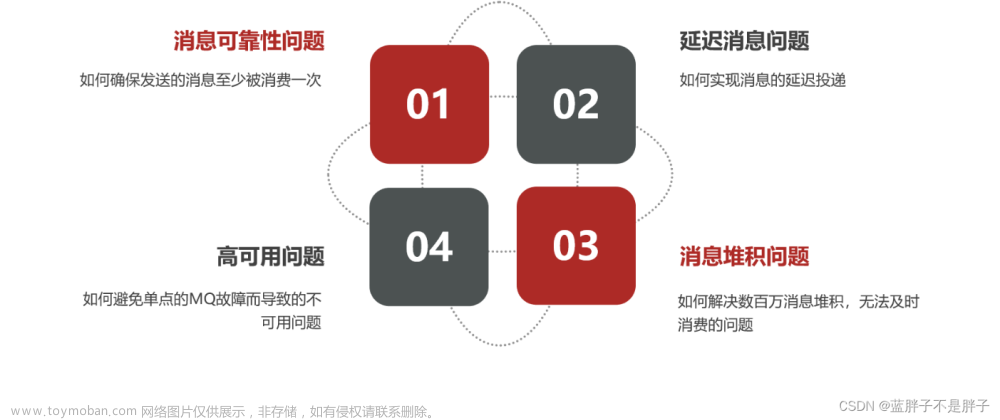
Maxwell是由美国Zendesk开源,用Java编写的MySQL等关系型数据库的实时抓取软件,能够实时抓取MySQL二进制日志binlog,并生成JSON格式的消息,作为生产者发送给kafaka、RabbitMQ、Redis等系统的应用程序。常用的场景有:ETL、维护缓存、收集表级别的DML指标、增量数据同步到搜索引擎、切库binlog回滚方案等。
Maxwell的特点包括:
- **实时数据捕获:**Maxwell可以实时的捕获数据库中的更改,包括插入、删除、更新等操作
- **支持多种数据库:**它可以与多种关系型数据库系统(如 MySQL、PostgreSQL)集成
- **JSON格式输出:**Maxwell通常以JSON格式输出变更的数据,易于处理和解析
- 可配置性: 用户可以根据自己的需求配置Maxwell,包括选择要捕获的数据表,输出目标等
Maxwell主要提供了以下功能:
- 支持 select * from table 的方式,进行全量数据初始化
- 支持在主库发生failover(宕机)后,自动恢复binlog位置
- 支持断点续传,Maxwell会记录上一次读取binlog的位点信息,下一次继续从该位点读取数据
- 工作方式为:伪装Salve,接收binlog events,然后根据schemas信息拼装,可接收DDL、DML等各种事件
二、背景
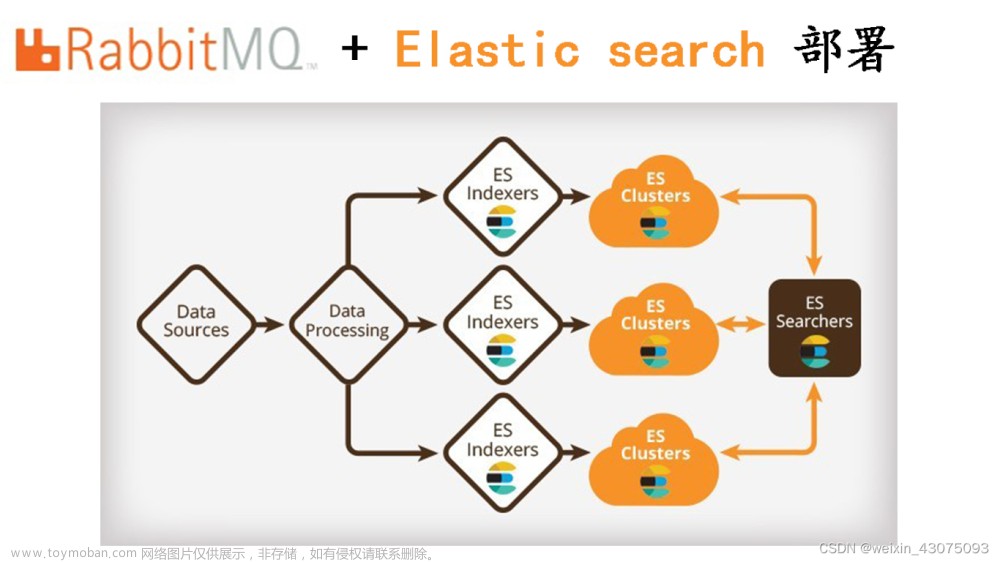
由于我们所开发的物流系统A所使用的数据库是MySQL,另一个系统B 使用的数据库是Oracle,但是B系统需要获取A系统的数据去完成一些必要的业务,所以就需要将A系统的数据同步到B数据中,最开始用的是OGG 工具同步的,但是会存在一些性能问题,而且一旦MySQL库发生故障或者触发了主从切换,那么同步相关的数据表都需要进行相关的初始化操作。最开始考虑使用Canal进行同步的,但是Canal不能断点续传,所以最终使用Maxwell框架进行,于是使用下述架构图对系统间的数据同步进行改造:

三、工作原理
Maxwell的操作开销很低,只需要有一个MySQL和一个可写的后续地方即可,当该应用程序伪装为MySQL的从机,读取到MySQL主机的binlog日志后,以JSON格式写入到Kafaka、Rabbit MQ等消息中间件,特点就是简单易用,不需要编写额外的客户端,大大降低了开发成本。

- Master主库将改变记录,写到二进制日志(binary log)
- Slave从库向MySQL master发送dump协议,将Master主库的binary log events拷贝到它的中继日志(relay log)
- Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库
四、Maxwell的下载与使用
4.1下载Maxwell
Maxwell官网地址: http://maxwells-daemon.io/
Github网址: https://github.com/zendesk/maxwell
本文使用的是Maxwell-1.29.2版本讲述
下载地址: https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz
#使用weget命令下载
cd /usr/local
mkdir software
cd /usr/local/softewre
wget https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz
如果是通过下载地址链接下载的,完成后 通过XFTP工具上传到/usr/local/softewre目录下

4.2 解压
#使用下述命令解压压缩包
tar zxvf maxwell-1.29.2.tar.gz
 文章来源:https://www.toymoban.com/news/detail-828404.html
文章来源:https://www.toymoban.com/news/detail-828404.html
4.3 配置MySQL的binlog日志
#先使用这个命令查看MySQL是否开启了binlog日志,如果Value列是OFF,代表未开启binlog日志
SHOW VARIABLES LIKE 'log_bin';
#查看MySQL的binlog日志的格式,关注binlog_format
show global variables like "binlog%";
#使用下述命令开启MySQL的 binlog日志
# 每个人安装的MySQL的配置文件目录不一样,根据自己的MySQL安装情况,找到自己的配置文件修改,我的是放在etc目录下的
vi /etc/my.cnf
[mysqld]
log-bin=mysql-bin #添加这一行就
binlog-format=ROW #选择row模式
server_id=1 #随机指定一个不能和其他集群中机器重名的字符串,如果只有一台机器,那就可以随便指定了
binlog-do-db=数据库名称 #启用binlog的数据库,需根据实际情况作出修改 默认全部开启
#然后退出,保存
以下是我的MySQL配置文件,可供参考文章来源地址https://www.toymoban.com/news/detail-828404.html
[mysqld]
bind-address=0.0.0.0
port=3306
user=mysql
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data/mysql
socket=/tmp/mysql.sock
log-error=/usr/local/mysql/data/mysql/mysql.err
pid-file=/usr/local/mysql/data/mysql/mysql.pid
#character config
character_set_server=utf8mb4
symbolic-links=0
explicit_defaults_for_timestamp=true
#skip-grant-tables
#开启binlog日志相关配置
#服务ID
server-id=1
#binlog配置 只要配置了log_bin地址就会开启
log_bin=mysql-bin
#规定binlog的格式,binlog有三种格式statement、row、mixad,默认使用statement,建议使用row格式
binlog_format=ROW
# 启用binlog的数据库,需根据实际情况作出修改 默认全部开启
binlog-do-db=gzmpcli_db
到了这里,关于Maxwell+RabbitMq实现数据同步的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!