1.背景介绍
随着大数据时代的到来,流处理技术变得越来越重要。流处理系统可以实时地处理大量数据,为实时应用提供有价值的信息。Apache Flink是一个流处理框架,它可以处理大规模的流数据,并提供丰富的功能,如窗口操作、时间操作等。在本文中,我们将深入探讨Flink流数据窗口与时间的相关概念、算法原理和实例代码。
2.核心概念与联系
在Flink中,流数据窗口和时间是两个核心概念。流数据窗口用于对流数据进行聚合操作,时间用于对流数据进行时间戳操作。这两个概念之间有密切的联系,因为窗口操作需要依赖时间戳来进行分区和排序。
2.1 流数据窗口
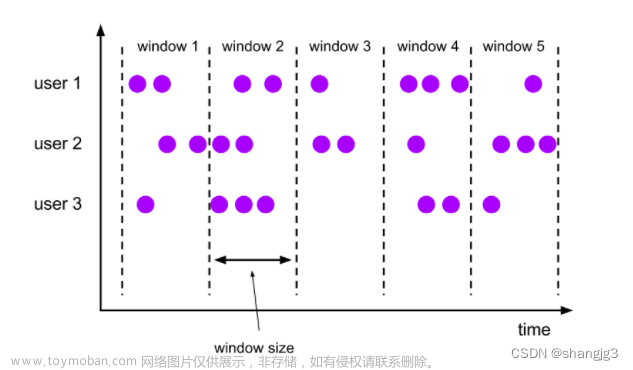
流数据窗口是一种用于对流数据进行聚合操作的数据结构。它可以将流数据分组,并对每个组进行操作。流数据窗口可以是时间窗口、滑动窗口等不同类型。
2.1.1 时间窗口
时间窗口是一种流数据窗口,它根据时间戳对流数据进行分组。时间窗口可以是固定大小的窗口,如每5秒的窗口;也可以是固定时间的窗口,如每天的窗口。
2.1.2 滑动窗口
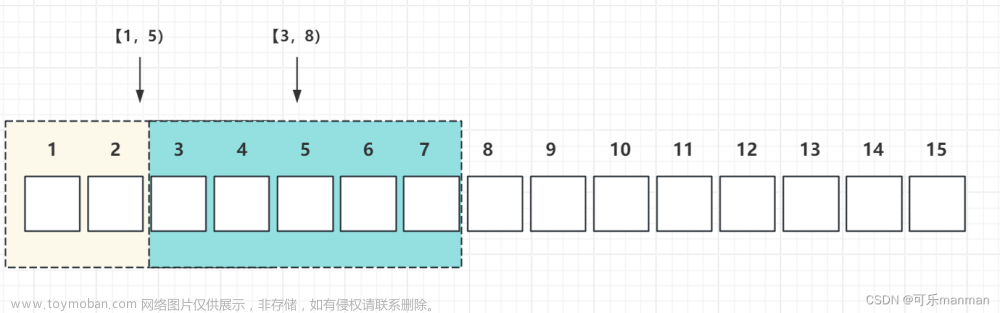
滑动窗口是一种流数据窗口,它根据时间戳对流数据进行分组,并允许窗口在时间轴上滑动。滑动窗口可以是固定大小的滑动窗口,如每5秒的滑动窗口;也可以是固定时间的滑动窗口,如每天的滑动窗口。
2.2 时间
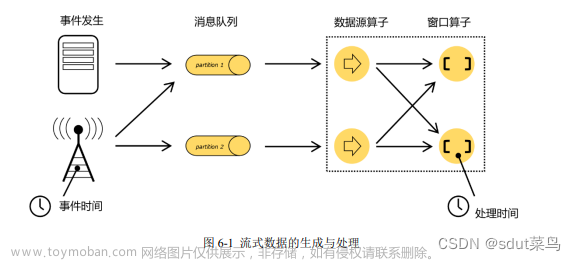
时间在Flink中是一个重要的概念,它用于对流数据进行时间戳操作。时间可以是事件时间、处理时间、摄取时间等不同类型。
2.2.1 事件时间
事件时间是流数据中的时间戳,它表示数据产生的时间。事件时间是不可变的,它在数据生成时就确定了。
2.2.2 处理时间
处理时间是流数据在Flink中的时间戳,它表示数据被处理的时间。处理时间可以是事件时间的延迟,它可能会因为网络延迟、计算延迟等原因而发生变化。
2.2.3 摄取时间
摄取时间是流数据在Flink中的时间戳,它表示数据被摄取的时间。摄取时间可以是事件时间的延迟,它可能会因为网络延迟、计算延迟等原因而发生变化。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
在Flink中,流数据窗口和时间的算法原理和操作步骤如下:
3.1 时间窗口算法原理
时间窗口算法的原理是根据时间戳对流数据进行分组。时间窗口算法的具体操作步骤如下:
- 根据时间戳对流数据进行分组。
- 对每个时间窗口进行聚合操作。
- 输出聚合结果。
时间窗口算法的数学模型公式为:
$$ W(t) = {e \in E | T(e) \in [t, t + w]} $$
其中,$W(t)$ 表示时间窗口,$t$ 表示时间戳,$w$ 表示窗口大小,$E$ 表示流数据集,$T(e)$ 表示数据$e$的时间戳。文章来源地址https://www.toymoban.com/news/detail-828765.html
3.2 滑动窗口算法原理
滑动窗口算法的原理是根据时间戳对流数据进行分组,并允许窗口在时间轴上滑动。滑动窗口算法的具体操作步骤如下:
- 根据时间戳对流数据进行分组。
- 对每个滑动窗口进行聚合操作。
- 滑动窗口在时间轴上滑动,输出聚合结果。
滑动窗口算法的数学模型公式为:
$$ W(t, w) = {e \in E | T(e) \in [t, t + w]} $$文章来源:https://www.toymoban.com/news/detail-828765.html
其中,$W(t, w)$ 表示滑动窗口,$t$ 表示时间戳,$w$ 表示窗口大小,$E$ 表示流数据集,$T(e)$ 表示数据$e$的时间戳。
4.具体代码实例和详细解释说明
在Flink中,流数据窗口和时间的具体代码实例如下:
4.1 时间窗口实例
```java import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class TimeWindowExample { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.fromElements("a", "b", "c", "d", "e");
DataStream<String> windowedStream = dataStream.keyBy(value -> value)
.window(Time.seconds(5))
.aggregate(new MyAggregateFunction());
windowedStream.print();
env.execute("Time Window Example");
}} `` 在上述代码中,我们创建了一个Flink流数据流,并使用keyBy方法对数据进行分组。然后,我们使用window方法创建一个时间窗口,窗口大小为5秒。最后,我们使用aggregate`方法对窗口内的数据进行聚合操作。
4.2 滑动窗口实例
```java import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.SlidingWindow;
public class SlidingWindowExample { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> dataStream = env.fromElements("a", "b", "c", "d", "e");
DataStream<String> windowedStream = dataStream.keyBy(value -> value)
.window(SlidingWindow.of(Time.seconds(5), Time.seconds(2)))
.aggregate(new MyAggregateFunction());
windowedStream.print();
env.execute("Sliding Window Example");
}} `` 在上述代码中,我们创建了一个Flink流数据流,并使用keyBy方法对数据进行分组。然后,我们使用window方法创建一个滑动窗口,窗口大小为5秒,滑动步长为2秒。最后,我们使用aggregate`方法对窗口内的数据进行聚合操作。
5.未来发展趋势与挑战
在未来,Flink流数据窗口和时间的发展趋势和挑战如下:
- 更高效的算法:随着数据规模的增加,Flink需要开发更高效的算法,以提高流数据窗口和时间的处理能力。
- 更好的并发:Flink需要优化并发控制,以提高流数据窗口和时间的并发性能。
- 更强的扩展性:Flink需要开发更强大的扩展性,以支持更大规模的流数据处理。
- 更好的容错性:Flink需要提高流数据窗口和时间的容错性,以便在异常情况下能够正常工作。
- 更丰富的功能:Flink需要开发更丰富的功能,以满足不同应用的需求。
6.附录常见问题与解答
在Flink流数据窗口和时间中,常见问题与解答如下:
- Q:Flink流数据窗口和时间的区别是什么? A:Flink流数据窗口是一种用于对流数据进行聚合操作的数据结构,而Flink流数据时间是一种用于对流数据进行时间戳操作的概念。
- Q:Flink流数据窗口有哪些类型? A:Flink流数据窗口有时间窗口和滑动窗口等类型。
- Q:Flink流数据时间有哪些类型? A:Flink流数据时间有事件时间、处理时间和摄取时间等类型。
- Q:Flink流数据窗口和时间的算法原理是什么? A:Flink流数据窗口和时间的算法原理是根据时间戳对流数据进行分组,并对每个窗口进行聚合操作。
- Q:Flink流数据窗口和时间的数学模型公式是什么? A:Flink流数据窗口和时间的数学模型公式分别为:
$$ W(t) = {e \in E | T(e) \in [t, t + w]} $$
$$ W(t, w) = {e \in E | T(e) \in [t, t + w]} $$
其中,$W(t)$ 表示时间窗口,$t$ 表示时间戳,$w$ 表示窗口大小,$E$ 表示流数据集,$T(e)$ 表示数据$e$的时间戳。
到了这里,关于Flink流数据窗口与时间的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!