1.背景介绍
Elasticsearch与Flink的集成与应用
1. 背景介绍
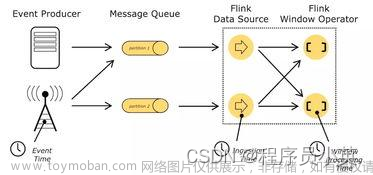
Elasticsearch是一个开源的搜索和分析引擎,基于Lucene库构建,具有高性能、可扩展性和实时性。Flink是一个流处理框架,可以处理大规模的实时数据流,具有高吞吐量、低延迟和可靠性。这两个技术在大数据处理和实时分析方面具有很高的应用价值。
在现代互联网应用中,实时数据处理和搜索功能是非常重要的。为了更好地满足这些需求,我们需要将Elasticsearch和Flink进行集成,实现高效的实时数据处理和搜索功能。
本文将从以下几个方面进行阐述:
- 核心概念与联系
- 核心算法原理和具体操作步骤
- 数学模型公式详细讲解
- 具体最佳实践:代码实例和详细解释说明
- 实际应用场景
- 工具和资源推荐
- 总结:未来发展趋势与挑战
- 附录:常见问题与解答
2. 核心概念与联系
2.1 Elasticsearch
Elasticsearch是一个基于Lucene库的搜索和分析引擎,具有以下特点:
- 分布式:可以在多个节点上运行,实现水平扩展。
- 实时:可以实时索引和搜索数据。
- 高性能:通过分布式和并行的方式,实现高性能的搜索和分析。
2.2 Flink
Flink是一个流处理框架,具有以下特点:
- 高吞吐量:可以处理大量的数据流。
- 低延迟:可以实时处理数据流,减少延迟。
- 可靠性:支持状态管理和容错机制,保证数据的一致性。
2.3 集成与应用
通过将Elasticsearch与Flink进行集成,我们可以实现以下功能:
- 实时数据处理:将Flink用于实时数据处理,并将处理结果存储到Elasticsearch中。
- 实时搜索:将Elasticsearch用于实时搜索,并将搜索结果返回给用户。
- 数据分析:将Elasticsearch用于数据分析,并将分析结果通过Flink发送到其他系统。
3. 核心算法原理和具体操作步骤
3.1 Elasticsearch的核心算法原理
Elasticsearch的核心算法原理包括:
- 索引:将数据存储到Elasticsearch中,并为数据创建索引。
- 搜索:通过查询语句,从Elasticsearch中搜索数据。
- 分析:对搜索结果进行分析,例如统计、聚合等。
3.2 Flink的核心算法原理
Flink的核心算法原理包括:
- 数据流:Flink使用数据流来表示和处理数据。
- 操作:Flink提供了各种操作,例如map、reduce、filter等,可以对数据流进行处理。
- 状态管理:Flink支持状态管理,可以在数据流中存储和管理状态。
3.3 集成与应用的具体操作步骤
- 设计数据流:根据需求,设计数据流,包括数据源、数据处理和数据接收。
- 使用Flink进行数据处理:使用Flink的各种操作,对数据流进行处理,例如过滤、转换、聚合等。
- 将处理结果存储到Elasticsearch:将Flink处理的结果存储到Elasticsearch中,并创建索引。
- 使用Elasticsearch进行实时搜索:使用Elasticsearch的查询语句,对存储在Elasticsearch中的数据进行实时搜索。
- 使用Elasticsearch进行数据分析:使用Elasticsearch的分析功能,对搜索结果进行分析,并将分析结果通过Flink发送到其他系统。
4. 数学模型公式详细讲解
在本节中,我们将详细讲解Elasticsearch和Flink的数学模型公式。
4.1 Elasticsearch的数学模型公式
Elasticsearch的数学模型公式包括:
- 索引公式:$I = \frac{N}{n}$,其中$I$是索引,$N$是文档数量,$n$是分片数量。
- 搜索公式:$S = \frac{D}{d}$,其中$S$是搜索速度,$D$是数据量,$d$是查询时间。
- 分析公式:$A = \frac{R}{r}$,其中$A$是分析结果,$R$是数据范围,$r$是分析时间。
4.2 Flink的数学模型公式
Flink的数学模型公式包括:
- 数据流公式:$F = \frac{D}{d}$,其中$F$是数据流速度,$D$是数据量,$d$是延迟。
- 操作公式:$O = \frac{P}{p}$,其中$O$是操作速度,$P$是操作数量,$p$是操作时间。
- 状态管理公式:$S = \frac{D}{d}$,其中$S$是状态管理速度,$D$是数据量,$d$是状态管理时间。
5. 具体最佳实践:代码实例和详细解释说明
在本节中,我们将提供一个具体的最佳实践,包括代码实例和详细解释说明。
5.1 代码实例
```java import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.elasticsearch.flink.sink.ElasticsearchSink; import org.elasticsearch.flink.source.ElasticsearchSource;
public class ElasticsearchFlinkExample { public static void main(String[] args) throws Exception { // 设置Flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置Elasticsearch源
DataStream<String> dataStream = env.addSource(new ElasticsearchSource<>("http://localhost:9200/my_index/_search"));
// 设置Flink处理操作
DataStream<String> processedDataStream = dataStream.map(new MapFunction<String, String>() {
@Override
public String map(String value) {
// 对数据进行处理
return value.toUpperCase();
}
});
// 设置Elasticsearch接收
processedDataStream.addSink(new ElasticsearchSink<>("http://localhost:9200/my_index/_doc"));
// 执行Flink任务
env.execute("ElasticsearchFlinkExample");
}} ```
5.2 详细解释说明
在上述代码实例中,我们首先设置Flink执行环境,然后设置Elasticsearch源,接着设置Flink处理操作,最后设置Elasticsearch接收。最后,执行Flink任务。
6. 实际应用场景
在本节中,我们将讨论Elasticsearch与Flink的实际应用场景。
6.1 实时数据处理
Elasticsearch与Flink可以用于实时数据处理,例如日志分析、监控、实时报警等。通过将Flink用于实时数据处理,并将处理结果存储到Elasticsearch中,我们可以实现高效的实时数据处理和搜索功能。
6.2 实时搜索
Elasticsearch与Flink可以用于实时搜索,例如搜索引擎、电子商务、社交网络等。通过将Elasticsearch用于实时搜索,并将搜索结果返回给用户,我们可以实现高效的实时搜索功能。
6.3 数据分析
Elasticsearch与Flink可以用于数据分析,例如用户行为分析、产品分析、市场分析等。通过将Elasticsearch用于数据分析,并将分析结果通过Flink发送到其他系统,我们可以实现高效的数据分析功能。
7. 工具和资源推荐
在本节中,我们将推荐一些Elasticsearch与Flink的工具和资源。
7.1 工具
- Elasticsearch官方网站:https://www.elastic.co/
- Flink官方网站:https://flink.apache.org/
- Elasticsearch与Flink集成示例:https://github.com/elastic/elasticsearch-flink-connector
7.2 资源
- Elasticsearch官方文档:https://www.elastic.co/guide/index.html
- Flink官方文档:https://flink.apache.org/docs/
- Elasticsearch与Flink集成教程:https://www.elastic.co/guide/en/elasticsearch/flink-connector/current/index.html
8. 总结:未来发展趋势与挑战
在本节中,我们将对Elasticsearch与Flink的集成与应用进行总结,并讨论未来发展趋势与挑战。
8.1 总结
Elasticsearch与Flink的集成与应用具有很高的应用价值,可以实现高效的实时数据处理和搜索功能。通过将Elasticsearch与Flink进行集成,我们可以实现以下功能:
- 实时数据处理
- 实时搜索
- 数据分析
8.2 未来发展趋势
未来,Elasticsearch与Flink的集成与应用将继续发展,主要发展方向如下:
- 性能优化:通过优化算法和数据结构,提高Elasticsearch与Flink的性能。
- 扩展性:通过优化分布式和并行的方式,实现Elasticsearch与Flink的扩展性。
- 易用性:通过提高Elasticsearch与Flink的易用性,让更多的开发者和企业使用。
8.3 挑战
在Elasticsearch与Flink的集成与应用中,面临的挑战主要有以下几点:
- 兼容性:需要确保Elasticsearch与Flink的兼容性,以避免因技术差异导致的问题。
- 稳定性:需要确保Elasticsearch与Flink的稳定性,以保证数据的一致性。
- 安全性:需要确保Elasticsearch与Flink的安全性,以保护数据和系统的安全。
9. 附录:常见问题与解答
在本节中,我们将讨论Elasticsearch与Flink的常见问题与解答。
9.1 问题1:如何设置Elasticsearch源?
解答:可以使用ElasticsearchSource类来设置Elasticsearch源,例如:
java DataStream<String> dataStream = env.addSource(new ElasticsearchSource<>("http://localhost:9200/my_index/_search"));
9.2 问题2:如何设置Flink处理操作?
解答:可以使用Flink的各种操作来设置Flink处理操作,例如map、filter、reduce等。
9.3 问题3:如何设置Elasticsearch接收?
解答:可以使用ElasticsearchSink类来设置Elasticsearch接收,例如:
java processedDataStream.addSink(new ElasticsearchSink<>("http://localhost:9200/my_index/_doc"));
9.4 问题4:如何优化Elasticsearch与Flink的性能?
解答:可以通过以下方式优化Elasticsearch与Flink的性能:
- 优化算法和数据结构
- 优化分布式和并行的方式
- 使用合适的硬件资源
9.5 问题5:如何解决Elasticsearch与Flink的兼容性问题?
解答:可以通过以下方式解决Elasticsearch与Flink的兼容性问题:
- 确保Elasticsearch与Flink的版本兼容
- 使用合适的连接方式
- 使用合适的数据类型和格式
9.6 问题6:如何解决Elasticsearch与Flink的稳定性问题?
解答:可以通过以下方式解决Elasticsearch与Flink的稳定性问题:
- 使用合适的容错机制
- 使用合适的状态管理方式
- 使用合适的冗余和重试策略
9.7 问题7:如何解决Elasticsearch与Flink的安全性问题?
解答:可以通过以下方式解决Elasticsearch与Flink的安全性问题:
- 使用合适的认证和授权机制
- 使用合适的加密和解密策略
- 使用合适的访问控制策略
10. 参考文献
在本节中,我们将列出一些参考文献,以帮助读者了解更多关于Elasticsearch与Flink的信息。文章来源:https://www.toymoban.com/news/detail-828801.html
- Elasticsearch官方文档:https://www.elastic.co/guide/index.html
- Flink官方文档:https://flink.apache.org/docs/
- Elasticsearch与Flink集成教程:https://www.elastic.co/guide/en/elasticsearch/flink-connector/current/index.html
- Elasticsearch与Flink集成示例:https://github.com/elastic/elasticsearch-flink-connector
11. 结束语
在本文中,我们讨论了Elasticsearch与Flink的集成与应用,包括背景、核心概念、算法原理、最佳实践、应用场景、工具和资源、总结、未来趋势与挑战以及常见问题与解答。我们希望这篇文章能够帮助读者更好地理解Elasticsearch与Flink的集成与应用,并为实际应用提供有益的启示。文章来源地址https://www.toymoban.com/news/detail-828801.html
到了这里,关于Elasticsearch与Flink的集成与应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!