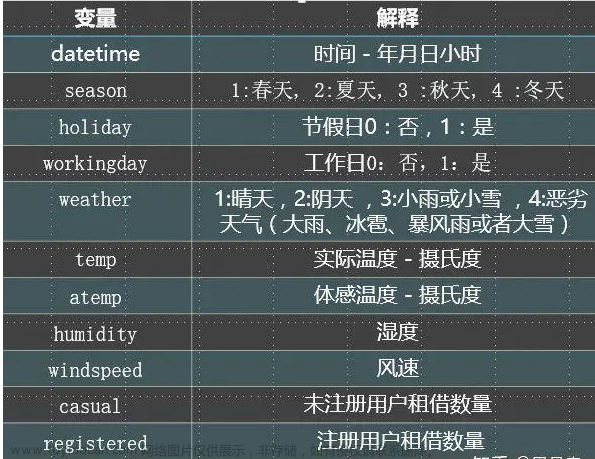
第1关 统计共享单车每天的平均使用时间
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.text.ParseException;
import java.util.Collection;
import java.util.Date;
import java.util.HashMap;
import java.util.Locale;
import java.util.Map;
import java.util.Scanner;
import java.math.RoundingMode;
import java.math.BigDecimal;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/**
* 统计共享单车每天的平均使用时间
*/
public class AveragetTimeMapReduce extends Configured implements Tool {
public static final byte[] family = "info".getBytes();
public static class MyMapper extends TableMapper<Text, BytesWritable> {
protected void map(ImmutableBytesWritable rowKey, Result result, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
long beginTime = Long.parseLong(Bytes.toString(result.getValue(family, "beginTime".getBytes())));
long endTime = Long.parseLong(Bytes.toString(result.getValue(family, "endTime".getBytes())));
String format = DateFormatUtils.format(beginTime, "yyyy-MM-dd", Locale.CHINA);
long useTime = endTime - beginTime;
BytesWritable bytesWritable = new BytesWritable(Bytes.toBytes(format + "_" + useTime));
context.write(new Text("avgTime"), bytesWritable);
/********** End *********/
}
}
public static class MyTableReducer extends TableReducer<Text, BytesWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable<BytesWritable> values, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
double sum = 0;
int length = 0;
Map<String, Long> map = new HashMap<String, Long>();
for (BytesWritable price : values) {
byte[] copyBytes = price.copyBytes();
String string = Bytes.toString(copyBytes);
String[] split = string.split("_");
if (map.containsKey(split[0])) {
Long integer = map.get(split[0]) + Long.parseLong(split[1]);
map.put(split[0], integer);
} else {
map.put(split[0], Long.parseLong(split[1]));
}
}
Collection<Long> values2 = map.values();
for (Long i : values2) {
length++;
sum += i;
}
BigDecimal decimal = new BigDecimal(sum / length /1000);
BigDecimal setScale = decimal.setScale(2, RoundingMode.HALF_DOWN);
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(family, "avgTime".getBytes(), Bytes.toBytes(setScale.toString()));
context.write(null, put);
/********** End *********/
}
}
public int run(String[] args) throws Exception {
// 配置Job
Configuration conf = HBaseUtil.conf;
// Scanner sc = new Scanner(System.in);
// String arg1 = sc.next();
// String arg2 = sc.next();
String arg1 = "t_shared_bicycle";
String arg2 = "t_bicycle_avgtime";
try {
HBaseUtil.createTable(arg2, new String[] { "info" });
} catch (Exception e) {
// 创建表失败
e.printStackTrace();
}
Job job = configureJob(conf, new String[] { arg1, arg2 });
return job.waitForCompletion(true) ? 0 : 1;
}
private Job configureJob(Configuration conf, String[] args) throws IOException {
String tablename = args[0];
String targetTable = args[1];
Job job = new Job(conf, tablename);
Scan scan = new Scan();
scan.setCaching(300);
scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存
// 初始化Mapreduce程序
TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, BytesWritable.class, job);
// 初始化Reduce
TableMapReduceUtil.initTableReducerJob(targetTable, // output table
MyTableReducer.class, // reducer class
job);
job.setNumReduceTasks(1);
return job;
}
}第2关 统计共享单车在指定地点的每天平均次数
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.Locale;
import java.util.Map;
import java.util.Scanner;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.SubstringComparator;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/**
* 共享单车每天在韩庄村的平均空闲时间
*/
public class AverageVehicleMapReduce extends Configured implements Tool {
public static final byte[] family = "info".getBytes();
public static class MyMapper extends TableMapper<Text, BytesWritable> {
protected void map(ImmutableBytesWritable rowKey, Result result, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
String beginTime = Bytes.toString(result.getValue(family, "beginTime".getBytes()));
String format = DateFormatUtils.format(Long.parseLong(beginTime), "yyyy-MM-dd", Locale.CHINA);
BytesWritable bytesWritable = new BytesWritable(Bytes.toBytes(format));
context.write(new Text("河北省保定市雄县-韩庄村"), bytesWritable);
/********** End *********/
}
}
public static class MyTableReducer extends TableReducer<Text, BytesWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable<BytesWritable> values, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
double sum = 0;
int length = 0;
Map<String, Integer> map = new HashMap<String, Integer>();
for (BytesWritable price : values) {
byte[] copyBytes = price.copyBytes();
String string = Bytes.toString(copyBytes);
if (map.containsKey(string)) {
Integer integer = map.get(string) + 1;
map.put(string, integer);
} else {
map.put(string, new Integer(1));
}
}
Collection<Integer> values2 = map.values();
for (Integer i : values2) {
length++;
sum += i;
}
BigDecimal decimal = new BigDecimal(sum / length);
BigDecimal setScale = decimal.setScale(2, RoundingMode. HALF_DOWN);
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(family, "avgNum".getBytes(), Bytes.toBytes(setScale.toString()));
context.write(null, put);
/********** End *********/
}
}
public int run(String[] args) throws Exception {
// 配置Job
Configuration conf = HBaseUtil.conf;
//Scanner sc = new Scanner(System.in);
//String arg1 = sc.next();
//String arg2 = sc.next();
String arg1 = "t_shared_bicycle";
String arg2 = "t_bicycle_avgnum";
try {
HBaseUtil.createTable(arg2, new String[] { "info" });
} catch (Exception e) {
// 创建表失败
e.printStackTrace();
}
Job job = configureJob(conf, new String[] { arg1, arg2 });
return job.waitForCompletion(true) ? 0 : 1;
}
private Job configureJob(Configuration conf, String[] args) throws IOException {
String tablename = args[0];
String targetTable = args[1];
Job job = new Job(conf, tablename);
Scan scan = new Scan();
scan.setCaching(300);
scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存
/********** Begin *********/
//设置过滤
ArrayList<Filter> listForFilters = new ArrayList<Filter>();
Filter destinationFilter =new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("destination"),
CompareOperator.EQUAL, new SubstringComparator("韩庄村"));
Filter departure = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("departure"),
CompareOperator.EQUAL, Bytes.toBytes("河北省保定市雄县"));
listForFilters.add(departure);
listForFilters.add(destinationFilter);
scan.setCaching(300);
scan.setCacheBlocks(false);
Filter filters = new FilterList(listForFilters);
scan.setFilter(filters);
/********** End *********/
// 初始化Mapreduce程序
TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, BytesWritable.class, job);
// 初始化Reduce
TableMapReduceUtil.initTableReducerJob(targetTable, // output table
MyTableReducer.class, // reducer class
job);
job.setNumReduceTasks(1);
return job;
}
}第3关 统计共享单车指定车辆每次使用的空闲平均时间
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.math.BigDecimal;
import java.math.RoundingMode;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/**
*
* 统计5996共享单车每次使用的空闲平均时间
*/
public class FreeTimeMapReduce extends Configured implements Tool {
public static final byte[] family = "info".getBytes();
public static class MyMapper extends TableMapper<Text, BytesWritable> {
protected void map(ImmutableBytesWritable rowKey, Result result, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
long beginTime = Long.parseLong(Bytes.toString(result.getValue(family, "beginTime".getBytes())));
long endTime = Long.parseLong(Bytes.toString(result.getValue(family, "endTime".getBytes())));
BytesWritable bytesWritable = new BytesWritable(Bytes.toBytes(beginTime + "_" + endTime));
context.write(new Text("5996"), bytesWritable);
/********** End *********/
}
}
public static class MyTableReducer extends TableReducer<Text, BytesWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable<BytesWritable> values, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
long freeTime = 0;
long beginTime = 0;
int length = 0;
for (BytesWritable time : values) {
byte[] copyBytes = time.copyBytes();
String timeLong = Bytes.toString(copyBytes);
String[] split = timeLong.split("_");
if(beginTime == 0) {
beginTime = Long.parseLong(split[0]);
continue;
}
else {
freeTime = freeTime + beginTime - Long.parseLong(split[1]);
beginTime = Long.parseLong(split[0]);
length ++;
}
}
Put put = new Put(Bytes.toBytes(key.toString()));
BigDecimal decimal = new BigDecimal(freeTime / length /1000 /60 /60);
BigDecimal setScale = decimal.setScale(2, RoundingMode.HALF_DOWN);
put.addColumn(family, "freeTime".getBytes(), Bytes.toBytes(setScale.toString()));
context.write(null, put);
/********** End *********/
}
}
public int run(String[] args) throws Exception {
// 配置Job
Configuration conf = HBaseUtil.conf;
// Scanner sc = new Scanner(System.in);
// String arg1 = sc.next();
// String arg2 = sc.next();
String arg1 = "t_shared_bicycle";
String arg2 = "t_bicycle_freetime";
try {
HBaseUtil.createTable(arg2, new String[] { "info" });
} catch (Exception e) {
// 创建表失败
e.printStackTrace();
}
Job job = configureJob(conf, new String[] { arg1, arg2 });
return job.waitForCompletion(true) ? 0 : 1;
}
private Job configureJob(Configuration conf, String[] args) throws IOException {
String tablename = args[0];
String targetTable = args[1];
Job job = new Job(conf, tablename);
Scan scan = new Scan();
scan.setCaching(300);
scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存
/********** Begin *********/
//设置过滤条件
Filter filter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("bicycleId"), CompareOperator.EQUAL, Bytes.toBytes("5996"));
scan.setFilter(filter);
/********** End *********/
// 初始化Mapreduce程序
TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, BytesWritable.class, job);
// 初始化Reduce
TableMapReduceUtil.initTableReducerJob(targetTable, // output table
MyTableReducer.class, // reducer class
job);
job.setNumReduceTasks(1);
return job;
}
}第4关 统计指定时间共享单车使用次数文章来源:https://www.toymoban.com/news/detail-829195.html
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/**
* 共享单车使用次数统计
*/
public class UsageRateMapReduce extends Configured implements Tool {
public static final byte[] family = "info".getBytes();
public static class MyMapper extends TableMapper<Text, IntWritable> {
protected void map(ImmutableBytesWritable rowKey, Result result, Context context)throws IOException, InterruptedException {
/********** Begin *********/
IntWritable doubleWritable = new IntWritable(1);
context.write(new Text("departure"), doubleWritable);
/********** End *********/
}
}
public static class MyTableReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
int totalNum = 0;
for (IntWritable num : values) {
int d = num.get();
totalNum += d;
}
Put put = new Put(Bytes.toBytes(key.toString()));
put.addColumn(family, "usageRate".getBytes(), Bytes.toBytes(String.valueOf(totalNum)));
context.write(null, put);
/********** End *********/
}
}
public int run(String[] args) throws Exception {
// 配置Job
Configuration conf = HBaseUtil.conf;
// Scanner sc = new Scanner(System.in);
// String arg1 = sc.next();
// String arg2 = sc.next();
String arg1 = "t_shared_bicycle";
String arg2 = "t_bicycle_usagerate";
try {
HBaseUtil.createTable(arg2, new String[] { "info" });
} catch (Exception e) {
// 创建表失败
e.printStackTrace();
}
Job job = configureJob(conf, new String[] { arg1, arg2 });
return job.waitForCompletion(true) ? 0 : 1;
}
private Job configureJob(Configuration conf, String[] args) throws IOException {
String tablename = args[0];
String targetTable = args[1];
Job job = new Job(conf, tablename);
ArrayList<Filter> listForFilters = new ArrayList<Filter>();
FastDateFormat instance = FastDateFormat.getInstance("yyyy-MM-dd");
Scan scan = new Scan();
scan.setCaching(300);
scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存
/********** Begin *********/
try {
Filter destinationFilter = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("beginTime"), CompareOperator.GREATER_OR_EQUAL, Bytes.toBytes(String.valueOf(instance.parse("2017-08-01").getTime())));
Filter departure = new SingleColumnValueFilter(Bytes.toBytes("info"), Bytes.toBytes("endTime"), CompareOperator.LESS_OR_EQUAL, Bytes.toBytes(String.valueOf(instance.parse("2017-09-01").getTime())));
listForFilters.add(departure);
listForFilters.add(destinationFilter);
}catch (Exception e) {
e.printStackTrace();
return null;
}
Filter filters = new FilterList(listForFilters);
scan.setFilter(filters);
/********** End *********/
// 初始化Mapreduce程序
TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, IntWritable.class, job);
// 初始化Reduce
TableMapReduceUtil.initTableReducerJob(targetTable, // output table
MyTableReducer.class, // reducer class
job);
job.setNumReduceTasks(1);
return job;
}
}
第5关 统计共享单车线路流量文章来源地址https://www.toymoban.com/news/detail-829195.html
package com.educoder.bigData.sharedbicycle;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import com.educoder.bigData.util.HBaseUtil;
/**
* 共享单车线路流量统计
*/
public class LineTotalMapReduce extends Configured implements Tool {
public static final byte[] family = "info".getBytes();
public static class MyMapper extends TableMapper<Text, IntWritable> {
protected void map(ImmutableBytesWritable rowKey, Result result, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
String start_latitude = Bytes.toString(result.getValue(family, "start_latitude".getBytes()));
String start_longitude = Bytes.toString(result.getValue(family, "start_longitude".getBytes()));
String stop_latitude = Bytes.toString(result.getValue(family, "stop_latitude".getBytes()));
String stop_longitude = Bytes.toString(result.getValue(family, "stop_longitude".getBytes()));
String departure = Bytes.toString(result.getValue(family, "departure".getBytes()));
String destination = Bytes.toString(result.getValue(family, "destination".getBytes()));
IntWritable doubleWritable = new IntWritable(1);
context.write(new Text(start_latitude + "-" + start_longitude + "_" + stop_latitude + "-" + stop_longitude + "_" + departure + "-" + destination), doubleWritable);
/********** End *********/
}
}
public static class MyTableReducer extends TableReducer<Text, IntWritable, ImmutableBytesWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
/********** Begin *********/
int totalNum = 0;
for (IntWritable num : values) {
int d = num.get();
totalNum += d;
}
Put put = new Put(Bytes.toBytes(key.toString() + totalNum ));
put.addColumn(family, "lineTotal".getBytes(), Bytes.toBytes(String.valueOf(totalNum)));
context.write(null, put);
/********** End *********/
}
}
public int run(String[] args) throws Exception {
// 配置Job
Configuration conf = HBaseUtil.conf;
// Scanner sc = new Scanner(System.in);
// String arg1 = sc.next();
// String arg2 = sc.next();
String arg1 = "t_shared_bicycle";
String arg2 = "t_bicycle_linetotal";
try {
HBaseUtil.createTable(arg2, new String[] { "info" });
} catch (Exception e) {
// 创建表失败
e.printStackTrace();
}
Job job = configureJob(conf, new String[] { arg1, arg2 });
return job.waitForCompletion(true) ? 0 : 1;
}
private Job configureJob(Configuration conf, String[] args) throws IOException {
String tablename = args[0];
String targetTable = args[1];
Job job = new Job(conf, tablename);
Scan scan = new Scan();
scan.setCaching(300);
scan.setCacheBlocks(false);// 在mapreduce程序中千万不要设置允许缓存
// 初始化Mapreduce程序
TableMapReduceUtil.initTableMapperJob(tablename, scan, MyMapper.class, Text.class, IntWritable.class, job);
// 初始化Reduce
TableMapReduceUtil.initTableReducerJob(targetTable, // output table
MyTableReducer.class, // reducer class
job);
job.setNumReduceTasks(1);
return job;
}
}到了这里,关于头歌:共享单车之数据分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!