本文介绍如何在 mac 下快速构建属于自己的 Flink 应用。
1. 本地安装 flink
在 mac 上使用homebrew安装 flink:
brew install apache-flink
查看安装的位置:
brew info apache-flink
进入安装目录,启动 flink 集群:
cd /usr/local/Cellar/apache-flink/1.18.0
./libexec/bin/start-cluster.sh
进入 web 页面:http://localhost:8081/
2. 构建项目
基于模板直接构建一个项目:
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.18.0
cd quickstart
在项目的 DataStreamJob 类实现如下计数的功能:
package org.myorg.quickstart;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class DataStreamJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.socketTextStream("127.0.0.1", 9000)
.flatMap(new LineSplitter())
.keyBy(0)
.sum(1)
.print();
env.execute("WordCount");
}
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) {
String[] tokens = s.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<>(token, 1));
}
}
}
}
}
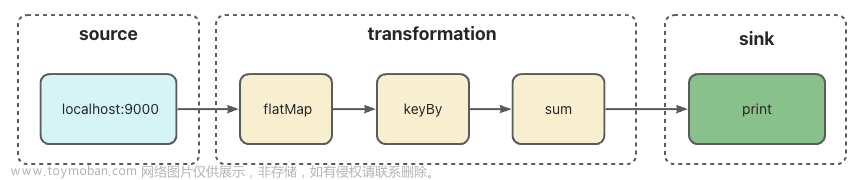
在上面的例子中,我们使用 DataStream API 构建了一个 Flink 应用,数据源(source)为本地的 socket 9000 端口,经过 flatMap、keyBy、sum 三个转换操作之后,最后打印到标准输出流。整体流程如下图:
3. 运行
启动 socket 连接,监听 9000 端口:
nc -l 9000
打包,上传(可以使用 Web UI 界面上传,也可以使用命令行上传)。
上传后,就可以在 WebUI 看到正在运行的 job 了。
此时通过在 socket 输入内容,
就可以在 task manager 的 stdout 看到打印结果了。
 文章来源:https://www.toymoban.com/news/detail-829261.html
文章来源:https://www.toymoban.com/news/detail-829261.html
4. 总结
本文从零开始在本地构建运行了一个 Flink 应用,包括 Flink 集群的安装、Flink 应用的构建,以及 Flink 应用的运行。文章来源地址https://www.toymoban.com/news/detail-829261.html
到了这里,关于从零开始快速构建自己的Flink应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!













