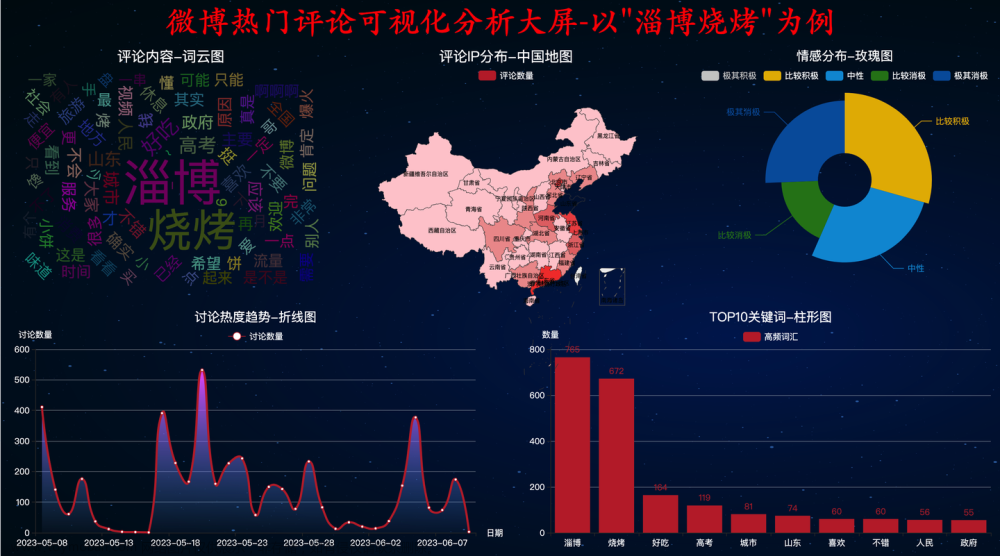
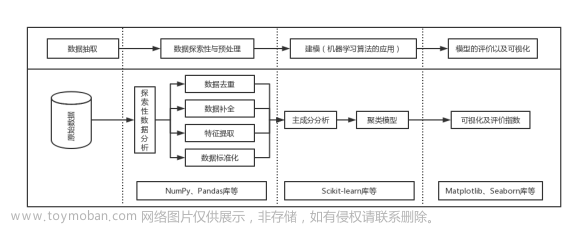
1. 引言
随着社交媒体的迅速发展,微博已成为人们交流观点、表达情感的重要平台之一。微博评论数据蕴含着丰富的信息,通过对这些数据进行分析和可视化,我们可以深入了解用户对特定话题的关注程度和情感倾向。本文将介绍如何利用Python进行微博评论数据的准备、探索、可视化和常见数据分析任务。
2. 数据准备
在进行数据分析之前,我们需要进行数据准备工作,包括数据采集、清洗和分析:
- 数据采集: 使用Python中的第三方库,如weibo-scraper,从微博平台获取指定话题的评论数据。
from weibo_scraper import WeiboScraper
# 实例化微博爬虫
weibo_scraper = WeiboScraper()
# 设置话题关键词
topic_keyword = "热门话题"
# 获取微博评论数据,假设采集10页数据
comments_data = weibo_scraper.get_comments(topic_keyword, pages=10)
- 数据清洗: 对采集到的数据进行清洗,去除重复数据、处理缺失值等,以确保数据质量。
import pandas as pd
# 将评论数据转换为DataFrame
comments_df = pd.DataFrame(comments_data)
# 去除重复数据
comments_df.drop_duplicates(inplace=True)
# 处理缺失值
comments_df.dropna(inplace=True)
- 数据分析: 使用Pandas、NumPy等库对清洗后的数据进行初步分析,了解数据的基本情况和结构。
# 评论数量的时间趋势
comments_df['created_at'] = pd.to_datetime(comments_df['created_at'])
comments_trend = comments_df.resample('D', on='created_at').count()
# 用户情感倾向的统计
sentiment_stats = comments_df['sentiment'].value_counts()
3. 数据探索
在数据准备完成后,我们需要对数据进行探索性分析,以更深入地了解数据的特征和规律:
- 分析评论数量随时间的变化趋势,探索话题的热度变化情况。
- 分析用户情感倾向,了解用户对话题的态度和情感分布。
# 导入必要的库
import matplotlib.pyplot as plt
# 统计每月评论数量
df['created_at'] = pd.to_datetime(df['created_at'])
monthly_comments = df.resample('M', on='created_at').size()
# 绘制评论数量随时间的折线图
plt.plot(monthly_comments.index, monthly_comments.values)
plt.title('Comments Over Time')
plt.xlabel('Month')
plt.ylabel('Number of Comments')
plt.show()
4. 数据可视化
数据可视化是理解数据、发现规律和展示结论的重要手段,我们将利用Python中的可视化工具构建各种图表:文章来源:https://www.toymoban.com/news/detail-829396.html
- 使用Matplotlib和Seaborn绘制评论数量随时间的折线图,展示话题热度的变化趋势。
- 利用饼图或柱状图展示用户情感倾向的分布情况,呈现用户对话题的态度和情感偏向。
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制评论数量时间趋势折线图
plt.figure(figsize=(12, 6))
sns.lineplot(data=comments_trend, x='created_at', y='comment_id')
plt.title('评论数量时间趋势')
plt.xlabel('日期')
plt.ylabel('评论数量')
plt.show()
# 绘制用户情感倾向统计饼图
plt.figure(figsize=(8, 8))
sentiment_stats.plot.pie(autopct='%1.1f%%', startangle=90)
plt.title('用户情感倾向统计')
plt.show()
5. 常见数据分析任务
除了数据的探索和可视化外,还有一些常见的数据分析任务需要进行:文章来源地址https://www.toymoban.com/news/detail-829396.html
- 关键词提取:从评论数据中提取关键词,了解用户关注的核心内容和热点话题。
- 用户互动分析:分析用户之间的互动情况,包括评论数、转发数、点赞数等指标,揭示用户的参与程度和话题影响力。
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 假设有关键词提取工具或模型得到每条评论的关键词(此处省略具体实现)
# 假设关键词存储在列'keywords'中
# 假设有互动数据,包括评论数、转发数、点赞数(此处省略具体实现)
# 数据准备(假设df是评论数据的DataFrame)
# df = ...
# 关键词提取
all_keywords = ' '.join(df['keywords'].dropna())
# 绘制词云
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(all_keywords)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud of Keywords')
plt.show()
# 用户互动分析
interaction_stats = df[['comments_count', 'reposts_count', 'attitudes_count']].sum()
# 绘制柱状图
interaction_stats.plot(kind='bar', rot=0)
plt.title('User Interaction Statistics')
plt.xlabel('Interaction Type')
plt.ylabel('Count')
plt.show()
到了这里,关于微博数据可视化分析:利用Python构建信息图表展示话题热度的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!