论文:https://arxiv.org/abs/2205.03346
代码:https://github.com/cuiziteng/ICCV_MAET
代码:https://github.com/cuiziteng/MAET
参考:https://zhuanlan.zhihu.com/p/572545992
摘要:
由于光子不足和不良的噪声,黑暗环境成为计算机视觉算法的一个挑战。
为了增强黑暗环境中的目标检测,我们提出了一种新的多任务自动编码转换(MAET)模型,该模型能够探索光照转换背后的内在模式。
MAET以一种自监督的方式,通过考虑物理噪声模型和图像信号处理(ISP)的真实照明退化转换进行编码和解码来学习内在的视觉结构。基于这种表示,我们通过解码边界框坐标和类来实现目标检测任务。为了避免两个任务的过度纠缠,我们的MAET通过施加正交切线规则来解开对象和退化特征。这形成了一个参数流形,沿着该流形,可以通过最大化沿着反射任务输出的切线之间的正交性来几何表述多任务预测。
我们的框架可以基于主流目标检测架构来实现,并使用VOC和COCO等常规目标检测数据集进行端到端直接训练。我们已经使用合成和真实世界的数据集实现了最先进的性能。
代码在https://github.com/cuiziteng/MAET
1. introduction
低光照环境对计算机视觉提出了重大挑战。计算摄影社区提出了许多面向人类视觉的算法来恢复正常照明的图像。不幸的是,恢复的图像不一定有利于高级视觉理解任务。由于增强/恢复方法针对人类视觉感知进行了优化,它们可能会产生伪影(例如,见图一),这会误导后续的视觉任务。

另一个研究方向集中在特定高级视觉算法的鲁棒性上。它们要么在大量的真实世界数据上训练模型,要么依赖于精心设计的任务相关特征。
然而,现有方法存在两个主要的不一致性:目标不一致性和数据不一致性(在现有研究中)。目标不一致是指大多数方法都专注于自己的目标,无论是人类视觉还是机器视觉。每条线分别遵循各自的路线,在一般的框架下不会相互受益。
与此同时,数据不一致使训练数据应与用于评估的数据相似的假设变得复杂。例如,预先训练的目标检测模型通常在清晰和正常照明的图像上进行训练。为了适应较差的光照条件,他们依赖于增强的黑暗图像来微调模型,而不探究光照变化下的内在结构。就像幸福的家庭都是一样的;每个不快乐的家庭都以自己的方式不快乐,即使使用现有的数据集,训练集也很难覆盖现实世界条件的不同分布。
在这里,我们的目标是在一个统一的框架下弥合上述两个差距。如图2所示,可以将正常照明的图像参数化转换(tdeg)为其低照度对应图像。基于这种转变。我们提出了一种新的多任务自动编码变换(MAET)来提取变换等变卷积特征,用于暗图像中的目标检测。我们基于两个任务来训练MAET:(1)通过解码基于未标记数据的低照明退化变换来学习内在表示。(2)基于标记数据解码目标位置和类别。如图2所示,我们训练我们的MAET,用siamese编码器E对一对正常照明和低光图像进行编码,并使用解码器Ddeg对其退化参数进行解码,如噪声水平、伽马校正和白平衡增益。这使我们的模型能够捕捉与光照变化等变的内在视觉结构。与进[20,42,20,28,41]相比,我们设计了考虑传感器和图像信号处理(ISP)的物理噪声模型的退化模型。然后,我们基于E编码的表示,使用解码器Dobj解码边界框坐标和类从而执行目标检测任务。

尽管MAET通过预测低光退化参数来规范网络训练,但目标检测和变换解码的联合训练是通过共享的骨干网络过度纠缠的。虽然这提高了使用MAET规则性对暗物体的检测,它也可能有将对象级表示过度拟合到自监督成像信号中的风险。为此,我们建议通过施加正交切角来区分目标检测和变换解码任务。它假设上述两个任务的多变量输出形成一个参数流形,并且通过最大化沿不同任务输出的多变量之间的正交性,可以对沿流形的多任务输出进行几何公式化。该框架可以使用标准目标检测数据集,如COCO和VOC,直接进行端到端训练,并使其检测低光图像。尽管我们考虑YOLOV3进行说明,但所提出的MAET是一个通用框架,可以很容易地应用于其他主流对象检测器。
我们对这项研究的贡献如下:
- 通过探索传感器和ISP管道的物理噪声模型,我们利用一种新的MAET框架来对内在结构进行编码,该结构可以解码低光退化转换。然后,我们通过解码基于这种鲁棒表示的边界框坐标和类别来完成对象检测。我们的MAET框架与主流目标检测架构兼容。
- 此外,我们提出了多任务输出的解纠缠,以避免学习的对象检测特征过拟合到自监督递减参数中。这可以从几何的角度自然地执行,通过最大化与不同任务输出相对应的切线的正交性。
- 基于综合评估,与其他的方法比较,我们的方法在低光物体检测任务中表现出优异的性能。
2. related work
2.1 low illumination datasets
已经提出了几个用于低光物体检测任务的数据集:
- NightOwls dataset: 用于夜间行人检测。
- 无约束人脸检测数据集(UFDD):考虑各种不利条件,例如下雨,雪,薄雾以及低照度。
- DARK FACE:包含10000张图像(包括6000张标记图像和4000张未标记图像)。
- Exdark:包括7363张具有12个类别的图像,用于多类别暗物体检测任务。
2.2 low-light vision
2.2.1 enhancement and restoration methods
低光视觉任务通过恢复细节和校正颜色偏移来关注人类视觉体验。
早期的尝试是基于Retinex理论的方法或基于直方图均衡(HE)的方法。如今,随着深度学习的发展,基于CNN的方法和基于GAN的方法在这项任务中取得了显著的改进。
如Wei等人将Retinex理论与深度网络相结合,用于低光图像增强。Jiang等使用了一个无监督的GAN来解决这个问题。郭等人提出了一种自监督方法,该方法可以在没有正常光图像的情况下学习。
2.2.2 high-level task
为了在黑暗环境中采用高级任务,一种直截了当的策略是将上述增强方法作为后处理步骤。其他人依赖于增强的真实世界数据或一些过于简化的合成数据。最近的真实噪声图像基准测试表明,有时候手工制作的算法甚至可能优于深度学习模型。为了结合计算摄影的优势,我们开发了一个具有转换等变表示学习的框架。
2.3 transformation-equivariant representation learning
已经提出了几种自监督表示学习方法来通过解决Jigsaw谜题或冲击图像的缺失区域来学习图像特征。最近,一系列自动编码转换(AETS),如AET[50]、AVT 371ENAET[45],已经证明了几种自我监督任务的最先进性能。由于AET是灵活的,不局限于任何特定的卷积结构,我们将其扩展到我们的多任务AET中,用于黑暗图像的目标检测。
3.multitask autoencoding transformation(MAET)
在本节中,
- 我们首先简要介绍了自动编码变换AET
- 在此基础上提出了多任务AET(MAET)
- 然后我们讨论了相机中的ISP流水线,以及设计我们的MAET所要的退化变换。
- 最后,我们解释了MAET体系结构以及训练和测试细节。
3.1 background: from AET to MAET
AET学习具有代表性的潜在特征,这些特征根据变换t从原始图像(x)和变换后的对应物(t(x))解码或恢复参数化变换。

AET包括连体表示编码器(E)和变换解码器(D)。
- 编码器E从x及其变换t(x)中提取特征,这应该捕捉内在的视觉结构来解释变换t(例如,下一节中的低照度退化变换)。
- 解码器D使用编码的E(x)和E(t(x))来解码t的估计值。

AET,特别是表示编码器E和变换解码器D,可以通过最小化原始变换t和预测结果的偏差损失来训练

其中表示使用预测变换和真实变换之间的均方误差(MSE)损失计算的k型变换损失。
3.2multi-task AET with orthogonal regularity

在本研究中,我们通过同时解决多个任务,将AET进一步扩展到MAET。如图所示2。所提出的MAET模型由两部分组成:表示编码器(E)和多任务解码器。
- 在光照退化变换的任务中,我们使用解码器对退化参数进行解码。
- 目标检测的任务由解码器来实现,直接从光照退化图像中预测边界框的位置和物体类别。
尽管这两个任务是相关的,但它们的输出反映了输入图像的非常不同的方面:的照明条件以及的目标位置和类别。这表明,可以施加正交正则性来减少不同任务输出之间不必要的相互依赖。
为此,所提出的MAET的正交目标是最小化余弦相似性的绝对值,如下所示:

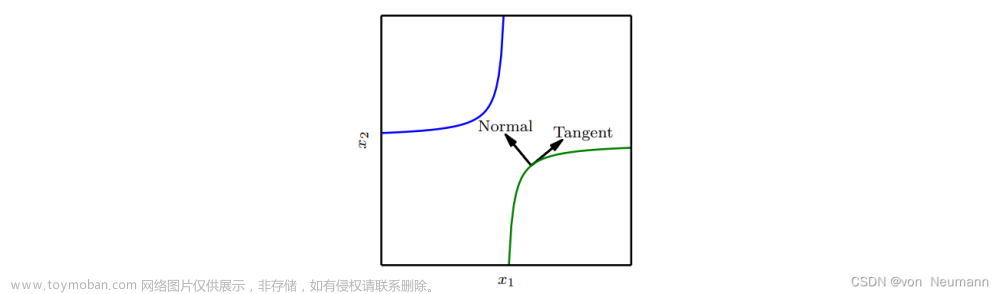
代表编码器E随着k次照明退化变换和第l次目标检测任务的输出坐标的代表流形的切线。换言之,这两条切线分别描绘了表示随解码器输出和的变化而移动的方向。
最小化余弦相似性的绝对值将使两条切线尽可能正交。从几何角度来看,这将把两个任务分开,以便一个任务的预测坐标的变化对另一个任务坐标的影响最小。在第3.3节中,我们将讨论如何定义低照度退化变换的细节。在文献中探讨了在任务之间施加正交性的想法。然而,我们在AET的背景下实现了他,其中正交方向是根据编码器诱导流形上的解码器切线来定义的,这与以前的工作不同。
因此,我们的低光目标检测的总损失由三部分组成:退化变换损失、目标检测损失和正交正则性损失(参见等式(4)),用于训练的总损失可以表示为:
- 目标检测损失对于不同的对象检测器是特定的。在本实验中,是YOLOv3的损失函数,包括位置损失、分类损失和置信度损失。
- 退化变换损失是低照度退化变换的AET损失(参见等式3),w1和w2是固定的平衡超参数
- 正交规则性损失见等式4
3.3 low-illumination degrading transformations
给定一个正常的无噪声图像x。我们的目标是设计一个低照度退化变换,将x变换为低光图像,该低光图像与在低照度条件下捕获的真实照片相匹配,即降低光照。大多数现有的方法都进行过简化的合成,例如,逆伽马校正(有时带有加性混合高斯噪声),基于retinex理论的合成方法。由于忽略了传感器的物理特性和片上图像信号处理(SP),这些方法很难推广到现实世界中的黑暗图像。在这里,我们首先系统地描述了传感器测量系统和最终照片之间的ISP管道。基于这条管道,我们对低光降解转换进行了参数化建模。
3.3.1 image signal processing pipeline
相机的设计目的是根据人类视角使照片尽可能令人愉悦和准确。出于这个原因,相机传感器捕获的RAW数据在成为最终照片之前需要ISP(几个步骤)。已经进行了大量研究来模拟这种ISP过程。例如,Karaimer和Brown逐步详细介绍了ISP项目,并展示了其与计算机视觉有关的高潜力。
我们采用了简化的ISP及其[3]中的解处理过程(图3)。特别地,我们忽略了几个步骤,包括去马赛克过程。尽管这些过程对于精确的ISP算法很重要,但互联网上的大多数图像都是各种来源的,并且没有遵循完全的ISP程序。我们忽略了这些步骤在精确性和通用性之间进行权衡。我们在补充材料附录B2中对去马赛克的影响进行了详细分析。接下来,我们详细介绍我们的ISP过程。

详细的ISP过程
Quantization:量化是模拟电压信号阶跃,使用模数转换器(ADC)将模拟测量x量化为离散代码。量化步骤将一系列模拟电压映射到单个值,并生成均匀分布的量化噪声。为了模拟量化步骤,添加了与B比特相关的量化噪声。在我们的退化模型中,B是从12、14和16位中随机选择的。

White Balace:白平衡模拟人类视觉系统(VS)的颜色恒定性,以将“白色”颜色映射到白色对象。所捕获的图像是光的颜色和材料反射率的乘积。相机管道中的白平衡步骤估计并调整红色通道增益和蓝色通道增益,以使图像在“中性”照明下看起来像是被照亮的。

在[35,3]的基础上,gr从(1.9,2.4)中随机选取,go从(1.5,1.9)中随机抽取;二者均服从均匀分布,且相互独立。转换过程考虑红色增益和蓝色增益的倒数1/g
Color Space Transformation:颜色空间变换将白平衡信号从相机内部颜色空间cRGB转换为sRGB颜色空间。这一步骤在ISP管道中是必不可少的,因为相机颜色空间与sRGB空间不相同。转换后的信号可以通过3 x 3颜色校正矩阵(CCM)获得:
这个过程的反转是:
Gamma Correction:伽马校正也被广泛用于ISP管道中,用于人类对黑暗区域感知的非线性。在这里,我们使用标准伽玛曲线:

伽马曲线参数可以从均匀分布中随机抽取,并且是一个非常小的值(),以防止训练过程中的数值不稳定。
Tone Mapping:色调映射旨在匹配胶片的“特征曲线”。出于计算复杂性的考虑,我们将“平滑步骤”曲线定义为:

3.3.2 degrading transformation model
在定义了ISP管道的每个步骤后,我们可以呈现我们的低光退化转换,它基于其正常光对应物x合成真实的暗光图像。
- 首先,如图所示3,我们必须使用逆处理过程将正常照明的图像x转换为传感器测量或RAW数据。
- 然后,我们线性衰减RAW图像,并用拍摄和读取噪声对其进行破坏。
- 最后,我们继续应用管道ISP,将低光传感器测量值转换为照片。
Unprocessing Procedure(未处理程序):
基于[3],未处理部分旨在将输入的sRGB图像转换为RAW格式的对应图像,这些图像与捕获的光子成线性比例。如图3所示,我们通过(a)反转色调映射(b)反转伽玛校正(c)将图像从SRGB空间转换到CRGB空间以及(d)反转白平衡来处理输入图像,这里我们将(a)(b)(c)(d)一起作为。
基于这部分,我们合成了逼真的RAW格式图像,并且将合成的RAW图像用于低光损坏过程。
Low Light Corrupyion(低光损坏):
当光子通过电容器簇上的透镜投射时,考虑到相同的曝光时间、孔径和自动增益控制,每个电容器都会产生与环境照明照度相对应的电荷。
散粒噪声是由相机中光子的随机到达产生的一种噪声,这是一个基本的限制。由于光子到达的时间由泊松统计量控制,因此在给定时间段内收集的光子数量的不确定性为,其中是散粒噪声,S是传感器信号。
在输出放大器中,电子电荷转换为电压时会出现读取噪声,其可以使用具有零均值和固定方差的高斯随机变量来近似。
镜头和读取噪声在相机成像系统中是常见的;因此,我们在传感器上对噪声的测量进行建模:

其中每个像素的真实强度来自未处理过程。我们用参数k线性衰减它。为了模拟不同的光照条件,光强k的参数是从截断的高斯分布中随机选择的,在(0.01,1.0)的范围内,平均值为0.1,方差为0.08。和参数范围遵循[35],如表1所示。
ISP Pipeline:
RAW图像同城会经过一系列转换,然后才能以RGB格式看到它。因此,我们在低光损坏处理之后应用RAW图像处理。基于[3],我们的变换顺序如下:(e)添加量化噪声(f)白平衡,(g)从CRGB到SRGB,以及(h)伽马校正,我们将(f),(g),(h)一起称为。
最后,我们可以从无噪声的x中获得退化的低光图像,如等式15所示。原始图像、生成图像和地面实况的一些示例如图4所示。我们总结了中涉及的参数及其范围(表1)



3.4 architecture
所提出的MAET的体系结构如图5所示。我们的网络包括表示编码器E和解码器D。为了便于说明,我们实现了基于YOLOv3架构的MAET。此外,这可以被其他主流检测框架所取代。

- E采用具有共享权重的连体结构。在训练过程中,正常光照图像被送到E的左路径(用橙色表示),而其退化的对应物经过右路径或暗路径(用蓝色表示)。这里,编码器采用DarkNet-53 networ作为主干。
- 由于我们解决了两个任务,即退化变换解码和目标检测任务,解码器D可以分为退化变换解码器和目标检测解码器。后者对目标信息解码,即目标类别和位置。
- 退化变换解码:前者侧重于低光退化变换的参数解码,编码的潜在特征E(x)和E((x)被连接在一起并且被传递到解码器以估计相应的退化变换。这种自我监督训练有助于MAET学习在未标记数据的各种照明退化转换下的内在视觉结构。
- 目标检测任务:后者对目标信息解码,即目标类别和位置。目标检测解码器只解码来自暗路径(用蓝色表示)的表示E((x),以预测目标检测的参数。在测试时间,我们直接将低光图像送到MAET编码器的暗路径,以解码检测结果:目标类别和位置。
4.experiments
4.1 training detaols
- 我们基于开源的目标检测工具箱MMDetection来实现我们的工作。
- 等式5中的损失分量w1和w2分别设置为1和10。
- 在本实验中,表示中YOLO Head输出支路的损失函数,表示预测与已知真值之间的变换参数的MSE损失,表1最后一行,每个参数在其相应的类别中被归一化为预处理步骤,其在中设置为5:1:1:1:1。
- 所有输入图像都已裁剪并调整为608 x 608像素大小。
- 主干DarkNet-53采用ImageNet预训练模型进行初始化。
- 采用随机梯度下降(SGD)作为优化器,
- 图像批量大小设置为8。
- 重量衰减设置为5e-4
- 动量设置为0.9。
- 编码器(E)和对象检测解码器()的学习速率最初被设置为5e-4,并且退化变换解码器()的学习率最初被设置成5e-5。
- 对于学习率衰减,这两种速率都采用了MultiStepLR策略。
- 对于VOC数据集,我们使用单个Nvidia GeForce RTX3090 GPU对网络进行了50个epoch的训练,在20和40个时期,学习率降低了10倍。
- 对于COCO数据集,用四个Nvidia GeForce RTX3090 GPUs对我们的网络进行273个epoch的训练,学习率在218和246个时期分别下降了10。
4.2 synthetic evaluation
Pascal VOC是一个著名的数据集,有20个分类。我们训练我们的模型基于VOC 2007和VOC 2012训练和测试集。我们测试我们的模型基于VOC 2007测试集。对于VOC评估,我们报告了IOU阈值为0.5时的平均精密度(mAP)率。
COCO是另一个广泛使用的数据集,具有80个类别和超过100000张图像。我们训练模型基于COCO 2017训练集,测试模型基于COCO 2017验证集。对于COCO评估,我们评估了COCO数据集的每个索引。VOC和COCO数据集的定量结果列于表2中。

在这一部分中,我们基于VOC和COCO数据集对YOLOv3模型进行了训练和测试,以正常照明和合成低照明图像作为参考。然后我们使用针对正常光照训练的YOLOv3模型,来测试通过不同的弱光增强方法恢复的集合,以验证正交损失的有效性。我们将具有/不具有正交损失函数的MAET模式训练为MAET(w/o ort)和MAET(w/o ort),并在不进行预处理的情况下直接在低光图像上测试这些模型。为了保证公平性,训练过程中的所有方法都设置为相同的设置参数。即数据增强方法(扩展、随机裁剪、多尺寸和随机翻转)、输入大小、学习率、学习策略和训练时期。表2中列出了实验配置和结果。
表2中的实验结果表明,基于合成的低光数据集,我们的MAET显著改进了基线检测框架。与增强方法相比,考虑到所有评估指标,我们所提出的MAET表现出优越的性能。
4.3 real-world evaluation
为了评估真实世界场景中的性能,我们已经使用纯暗(Exdark)数据集评估了我们训练的模型(在第4.2节中解释),该数据集包括7363张低光图像,从极暗环境到黄昏,共有12个物体类别。每个图像对局部物体边界框都有注释。由于Exdark是根据不同类别划分的:每个类别的80%样本用于对COCO预训练模型进行25个epoch的微调,学习率为0.001,其余20%用于预测;我们计算了每个类别的平均精度(AP)(详见表3),并计算了总体平均精度(mAP)。此外,我们在附录A中提供了一些例子。如表3所示,我们可以看到,考虑到大多数类别和总体MAP,所提出的MAET方法取得了令人满意的性能。这一结果证实了我们的退化转变符合现实世界的条件。

此外我们已经用UG2+DARK FACE数据集评估了我们的方法;UG2+是一个低光人脸检测数据集,其中包含6000张标记的低光人脸图像,其中5400张图像用于对COCO预训练模型进行20个epoch的微调,学习率为0.001。其他600张图像用于评估实验结果如表4所示。与其他方法相比,所提出的MAET方法取得了更好的结果。

5. conclusion
我们提出了MAET,这是一个新的框架,用于探索与光照变化引起的退化等价的内在表示。
MAET对这种自监督表示进行解码,以检测黑暗环境中的物体。为了避免目标和退化特征的过度纠缠,我们的方法开发了一个参数流形,通过最大化沿各个任务输出的切线之间的正交性,可以沿着该参数流形对多任务预测进行几何公式化。
在整个实验中,所提出的算法优于与真实世界和合成暗图像数据集相关的最先进模型。
笔记
self-supervision 自监督
表示学习
siamese structure
量化文章来源:https://www.toymoban.com/news/detail-829419.html
白平衡文章来源地址https://www.toymoban.com/news/detail-829419.html
到了这里,关于Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection论文笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[23] IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts](https://imgs.yssmx.com/Uploads/2024/02/724253-1.png)