01 基本概念
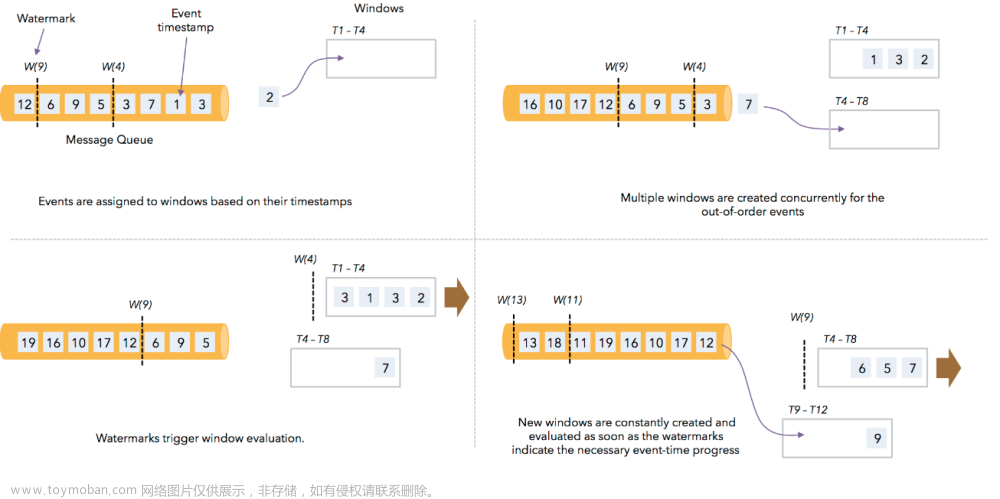
Watermark 是用于处理事件时间的一种机制,用于表示事件时间流的进展。在流处理中,由于事件到达的顺序和延迟,系统需要一种机制来衡量事件时间的进展,以便正确触发窗口操作等。Watermark 就是用来标记事件时间的进展情况的一种特殊数据元素。
02 工作原理
Watermark 的生成方式通常是由系统根据数据流中的事件来自动推断生成的。一般来说,系统会根据事件时间戳和一定的策略来生成 Watermark,以此来表示事件时间的进展。在 Flink 中,通常会有内置的 Watermark 生成器或者用户自定义的生成器来实现这个功能。
当一个 Watermark 被生成后,它会被发送到流处理的所有并行任务中。任务会根据接收到的 Watermark,将小于或等于 Watermark 的事件时间的数据触发相关操作(如窗口计算),以此来确保计算的正确性。
03 优势与劣势
优点:
- Watermark 可以确保流处理系统正确处理事件时间,避免了由于乱序和延迟引起的计算错误。
- 可以根据业务需求和数据特征灵活调整 Watermark 生成的策略,以适应不同的场景。
- Watermark 的引入使得流处理系统更具健壮性,能够处理各种实时数据场景。
缺点:
- Watermark 的生成可能会带来一定的开销,尤其是在数据量庞大、事件频繁的情况下,可能会对系统性能产生一定影响。
- 对于某些特殊的场景,例如极端乱序或者延迟过大的情况,Watermark 可能无法完全解决事件时间处理的问题。
04 核心组件
-
Apache Flink中的水印(Watermark)是事件时间处理的核心组件之一,它用于解决无序事件流中的事件时间问题。水印是一种元数据,用于告知系统事件时间流的进度,从而使系统能够在处理延迟的数据时做出正确的决策。
以下是Flink中水印的核心组件:
-
Watermark生成器(Watermark Generator):
- Watermark生成器负责生成水印,并将其插入到数据流中。
- 水印生成的策略通常与数据源有关。例如,对于有序的数据源,可以根据数据的事件时间直接生成水印;对于无序数据源,则可能需要一些启发式方法来生成水印。
-
AssignerWithPeriodicWatermarks:
- 这是一个Flink提供的接口,用于在数据流中分配水印。
- 实现此接口的类需要实现两个方法:
extractTimestamp()用于提取事件时间戳,getCurrentWatermark()用于生成当前水印。
-
AssignerWithPunctuatedWatermarks:
- 与上述相似,但是这个接口适用于在特定条件下(例如特定的事件)生成水印的场景。
-
Watermark延迟(Watermark Lag):
- 衡量系统中水印到达事件流的延迟程度。通常,水印到达得越快,系统对事件时间处理的准确性就越高。
-
Watermark策略(Watermarking Strategy):
- 这是一个配置项,用于确定水印生成的策略。可以基于固定的时间间隔生成水印,也可以根据事件流的特性进行自适应调整。
-
Watermark传递和处理:
- Flink通过数据流将水印传递给各个操作符(operators),从而确保水印在整个流处理拓扑中传递。
- 在处理过程中,水印用于确定事件时间窗口(Event Time Windows)的关闭时机,以及触发一些基于事件时间的操作,如触发窗口计算等。
-
处理水印(Handling Watermarks):
- 在窗口计算等操作中,Flink需要根据水印来判断是否可以触发计算操作,以此保证结果的正确性和完整性。
水印的核心作用在于解决事件时间处理中的乱序问题,通过适当的水印策略和生成机制,可以有效地处理延迟数据和乱序数据,保证数据处理的准确性和时效性。
-
Watermark生成器(Watermark Generator):
05 Watermark 生成器 使用
在 Apache Flink 中,提供了一些内置的 Watermark 生成器,这些生成器可以用于简化在流处理中的 Watermark 管理。以下是一些常用的内置 Watermark 生成器:
-
BoundedOutOfOrdernessTimestampExtractor:
-
描述: 这是 Flink 内置的基于有界乱序时间的 Watermark 生成器。
-
用法: 用户可以通过指定最大允许的乱序时间来创建一个
BoundedOutOfOrdernessTimestampExtractor实例。通常情况下,用户需要实现extractTimestamp方法,从事件中提取事件时间戳。 -
示例:
public class MyTimestampExtractor extends BoundedOutOfOrdernessTimestampExtractor<MyEvent> { public MyTimestampExtractor(Time maxOutOfOrderness) { super(maxOutOfOrderness); } @Override public long extractTimestamp(MyEvent event) { return event.getTimestamp(); } }
-
-
AscendingTimestampExtractor:
-
描述: 这是一个简单的 Watermark 生成器,适用于按照事件时间戳升序排列的数据流。
-
用法: 用户只需实现
extractAscendingTimestamp方法,从事件中提取事件时间戳。 -
示例:
public class MyAscendingTimestampExtractor extends AscendingTimestampExtractor<MyEvent> { @Override public long extractAscendingTimestamp(MyEvent event) { return event.getTimestamp(); } }
-
-
AssignerWithPunctuatedWatermarks:
-
描述: 这是一种特殊类型的 Watermark 生成器,它可以基于某些事件的属性产生 Watermark。
-
用法: 用户需要实现
checkAndGetNextWatermark方法,根据事件的某些属性来判断是否生成 Watermark。 -
示例:
public class MyPunctuatedWatermarkAssigner implements AssignerWithPunctuatedWatermarks<MyEvent> { @Override public long extractTimestamp(MyEvent element, long previousElementTimestamp) { return element.getTimestamp(); } @Override public Watermark checkAndGetNextWatermark(MyEvent lastElement, long extractedTimestamp) { // 根据 lastElement 的某些属性判断是否生成 Watermark if (lastElement.getProperty() > threshold) { return new Watermark(extractedTimestamp); } return null; // 如果不生成 Watermark,则返回 null } }
-
这些内置的 Watermark 生成器提供了灵活性和方便性,使得在 Flink 中实现基于事件时间的处理变得更加容易。根据具体的业务需求和数据特征,可以选择合适的 Watermark 生成器来确保准确的事件时间处理。
06 应用场景
在Apache Flink 1.18中,水印(Watermark)是事件时间处理的核心组件,用于解决事件时间流处理中的乱序和延迟数据的问题。下面是一些Flink 1.18中集成Watermark水印的应用场景:
-
流式窗口操作:
- 在流式处理中,经常需要对事件进行窗口化操作,例如按时间窗口、会话窗口等进行聚合计算。Watermark的到达可以作为触发窗口计算的信号,确保窗口在事件时间上的正确性。这种情况下,Watermark能够确保窗口内的数据已经全部到达,可以进行聚合计算,同时还能够处理延迟的数据。
-
处理乱序数据:
- 在实际的数据流中,事件通常不会按照严格的时间顺序到达,可能存在乱序的情况。Watermark可以帮助系统理清事件的先后顺序,确保在事件时间上的正确性。通过适当设置Watermark的生成策略,可以根据数据特性来处理乱序数据,保证数据处理的正确性。
-
事件时间窗口计算:
- 在处理事件时间窗口时,Watermark起到了关键作用。它确定了窗口的关闭时机,即在Watermark达到窗口的结束时间时,系统可以安全地关闭该窗口,并对其中的数据进行计算。这确保了窗口计算的正确性,同时也能够处理延迟数据,使得窗口计算能够在数据到达时即时进行。
-
处理迟到的数据:
- Watermark还可以用于处理迟到的数据,即已经超过窗口关闭时限但仍然到达的数据。通过设置适当的延迟容忍阈值,可以容忍一定程度的迟到数据,并将其纳入窗口计算中。这样可以提高数据处理的完整性和准确性。
- 实时数据监控和异常检测:
- 在实时数据流中,通常需要对数据进行实时监控和异常检测。Watermark可以用于确定事件时间的进度,从而实现实时监控和异常检测。例如,可以基于事件时间窗口对数据进行统计分析,发现突发的异常情况,并及时采取相应的措施。
总的来说,Flink 1.18中集成Watermark水印的应用场景涵盖了广泛的实时数据处理领域,包括流式窗口操作、处理乱序数据、事件时间窗口计算、处理迟到的数据以及实时数据监控和异常检测等方面。Watermark作为事件时间处理的核心组件,为Flink提供了处理实时数据流的强大功能,能够确保数据处理的准确性和时效性。
07 注意事项
Apache Flink 中水印(Watermark)的使用是关键的,特别是在处理事件时间(Event Time)数据时。水印是一种机制,用于处理无序事件流,并确保在执行窗口操作时数据的完整性和正确性。以下是在使用 Flink 1.18 中水印的一些注意事项:
-
水印生成器(Watermark Generators)的选择:
- Flink 提供了多种内置的水印生成器,如 BoundedOutOfOrdernessTimestampExtractor 和 AscendingTimestampExtractor。
- BoundedOutOfOrdernessTimestampExtractor 适用于处理带有乱序的数据流,它会为每个事件引入一定的延迟。
- AscendingTimestampExtractor 适用于处理按事件顺序到达的数据流,它假定数据已经按照事件时间排序。
-
水印延迟(Watermark Lag)的设置:
- 设置水印延迟是非常重要的,它决定了 Flink 在处理数据时能够容忍的事件延迟时间。
- 如果设置的水印延迟过小,可能会导致窗口操作不正确,因为 Flink 认为某些事件已经到达,但实际上它们还没有到达。
- 如果设置的水印延迟过大,可能会导致窗口操作的延迟增加,因为 Flink 需要等待更长时间以确保数据的完整性。
-
数据源的处理:
- 在读取数据源时,确保正确地分配时间戳并生成水印。这通常需要在数据源的读取逻辑中明确指定时间戳和水印生成的逻辑。
-
水印与窗口操作的关系:
- 在执行窗口操作(如窗口聚合、窗口计算等)时,水印的生成和处理是至关重要的。
- 水印确保在触发窗口计算时,Flink 已经收到了窗口结束时间之前的所有数据,从而确保计算结果的准确性。
-
定期检查水印生成是否正常:
- 在部署 Flink 作业时,建议定期检查水印的生成情况。可以通过 Flink 的监控界面或日志来查看水印的生成情况,并根据需要调整水印生成的逻辑和设置。
-
监控和调试:
- 在使用水印时,需要重点关注作业的监控和调试,以确保水印的生成和处理是符合预期的。
- 如果发现数据延迟或窗口计算不正确,可以通过监控数据流和日志来定位和解决问题,可能需要调整水印的生成逻辑或调整水印延迟来改善作业的性能和准确性。
-
数据倾斜和性能优化:
- 在使用水印时,需要注意数据倾斜可能会影响水印的生成和处理性能。可以通过合理的数据分片和并行处理来减轻数据倾斜带来的影响,从而提高作业的性能和稳定性。
总的来说,水印在 Flink 中的使用是非常重要的,它能够确保在处理事件时间数据时保持数据的完整性和正确性。因此,在设计和部署 Flink 作业时,需要特别注意水印的生成和处理,以确保作业能够正确运行并获得良好的性能表现。
08 案例分析
8.1 窗口统计数据不准
当涉及到事件时间处理时,延迟和乱序是非常常见的情况。下面是一个简单的案例,演示了在事件时间处理中可能遇到的延迟和乱序问题。
假设我们有一个用于监控网站用户访问的实时数据流。每个事件都包含用户ID、访问时间戳和访问的网页URL。我们想要计算每个用户在每小时内访问的不同网页数量。
考虑到网络传输和数据处理可能会引入延迟和乱序,我们的数据流可能如下所示:
Event 1: {UserID: 1, Timestamp: 12:00:05, URL: "example.com/page1"}
Event 2: {UserID: 2, Timestamp: 12:00:10, URL: "example.com/page2"}
Event 3: {UserID: 1, Timestamp: 12:00:15, URL: "example.com/page2"}
Event 4: {UserID: 1, Timestamp: 11:59:58, URL: "example.com/page3"} <-- 延迟
Event 5: {UserID: 2, Timestamp: 12:00:02, URL: "example.com/page4"} <-- 乱序
在这个示例中,Event 4由于延迟而晚于其他事件到达,而Event 5由于乱序而在其本应到达的时间之前到达。
如果没有使用水印机制,Flink 可能会错误地将 Event 4 的数据统计到 12:00:00 ~ 12:01:00 的窗口中,这是因为 Flink 默认情况下是根据接收到事件的时间来进行处理的,而不是根据事件实际发生的事件时间。
8.2 水印是如何解决延迟与乱序问题?
在上述案例中,Flink 的水印(Watermark)机制通过指示事件时间的上限,帮助系统确定事件时间窗口的边界。水印本质上是一种元数据,它告知 Flink 在某个时间点之前的数据已经全部到达。
下面简要说明水印如何在案例中发挥作用:
-
处理延迟数据:
- 当 Event 4 发生延迟到达时,水印会逐渐推进,最终达到 Event 4 的事件时间戳(11:59:58)。
- Flink 知道在水印之前的所有数据都已经到达,因此即使 Event 4 晚到,也不会影响窗口的触发。
-
处理乱序数据:
- 当 Event 5 由于乱序提前到达时,水印仍然在逐渐推进。
- Flink 通过水印判断,在当前水印之前的所有数据都已到达,因此可以触发相应的窗口计算。
-
窗口触发:
- Flink 会根据水印确定触发窗口的时机。当水印到达某个时间戳时,Flink 知道在该水印之前的数据已经全部到达,可以安全地触发窗口计算。
- 比如,在水印到达 12:00:05 时,Flink 可以触发 12:00:00 - 12:01:00 的窗口计算,处理这一时段内的数据。
综合来说,水印帮助 Flink 在事件时间处理中正确处理延迟和乱序的数据,确保窗口操作的准确性和完整性。通过逐渐推进水印,系统能够在事件时间轴上有序地进行处理,而不会受到延迟和乱序数据的影响。
8.3 详细分析
假设我们有以下十条乱序的事件数据,每条数据包含事件时间戳和相应的值:
事件时间戳(毫秒) 值
1000 10
2000 15
3000 12
1500 8
2500 18
1200 6
1800 14
4000 20
3500 16
3200 9
我们将使用Watermark来处理这些数据,并进行窗口统计。假设窗口大小为2秒,最大乱序时间为1秒。
使用Watermark前的统计:
- 当接收到事件时间戳为1000毫秒时,将值10加入窗口。
- 当接收到事件时间戳为2000毫秒时,将值15加入窗口。
- 当接收到事件时间戳为3000毫秒时,将值12加入窗口。
- 当接收到事件时间戳为1500毫秒时,将值8加入窗口。
- 当接收到事件时间戳为2500毫秒时,将值18加入窗口。
- 当接收到事件时间戳为1200毫秒时,将值6加入窗口。
- 当接收到事件时间戳为1800毫秒时,将值14加入窗口。
- 当接收到事件时间戳为4000毫秒时,将值20加入窗口。
- 当接收到事件时间戳为3500毫秒时,将值16加入窗口。
- 当接收到事件时间戳为3200毫秒时,将值9加入窗口。
使用Watermark后的统计:
Watermark的计算过程如下: Watermark = max(当前Watermark, 当前事件时间 - 最大乱序时间)
在这个例子中,我们设定最大乱序时间为1秒,即1000毫秒。
- 当收到事件时间戳为1000毫秒时,Watermark = max(0, 1000 - 1000) = 0毫秒。
- 当收到事件时间戳为2000毫秒时,Watermark = max(0, 2000 - 1000) = 1000毫秒。
- 当收到事件时间戳为3000毫秒时,Watermark = max(1000, 3000 - 1000) = 2000毫秒。
- 当收到事件时间戳为1500毫秒时,Watermark = max(2000, 1500 - 1000) = 2000毫秒。
- 当收到事件时间戳为2500毫秒时,Watermark = max(2000, 2500 - 1000) = 2000毫秒。
- 当收到事件时间戳为1200毫秒时,Watermark = max(2000, 1200 - 1000) = 2000毫秒。
- 当收到事件时间戳为1800毫秒时,Watermark = max(2000, 1800 - 1000) = 2000毫秒。
- 当收到事件时间戳为4000毫秒时,Watermark = max(2000, 4000 - 1000) = 3000毫秒。
- 当收到事件时间戳为3500毫秒时,Watermark = max(3000, 3500 - 1000) = 3000毫秒。
- 当收到事件时间戳为3200毫秒时,Watermark = max(3000, 3200 - 1000) = 3000毫秒。
Watermark确定了什么时候触发窗口统计。在本例中,当Watermark超过窗口的结束时间时,窗口将被关闭,并进行统计。因此,Watermark确保了即使在乱序数据的情况下,窗口统计也能够按照正确的事件时间顺序进行。
为了更清晰地展示Watermark的影响,以下是每个事件被处理时的Watermark状态和窗口统计的结果:文章来源:https://www.toymoban.com/news/detail-829518.html
事件时间戳(毫秒) 值 Watermark 窗口统计结果
1000 10 0 10
2000 15 1000 25
3000 12 2000 27
1500 8 2000 27
2500 18 2000 30
1200 6 2000 30
1800 14 2000 32
4000 20 3000 36
3500 16 3000 36
3200 9 3000 36
这里的窗口统计结果是在Watermark触发时计算的。在Watermark超过窗口结束时间时,窗口会被关闭,并进行统计。文章来源地址https://www.toymoban.com/news/detail-829518.html
09 项目实战demo
9.1 pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xsy</groupId>
<artifactId>aurora_flink_connector_file</artifactId>
<version>1.0-SNAPSHOT</version>
<!--属性设置-->
<properties>
<!--java_JDK版本-->
<java.version>11</java.version>
<!--maven打包插件-->
<maven.plugin.version>3.8.1</maven.plugin.version>
<!--编译编码UTF-8-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--输出报告编码UTF-8-->
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<!--通用依赖-->
<dependencies>
<!--集成日志框架 start-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.17.1</version>
</dependency>
<!--集成日志框架 end-->
<!-- json -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<!-- flink读取Text File文件依赖 start-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.18.0</version>
</dependency>
<!-- flink读取Text File文件依赖 end-->
<!-- flink基础依赖 start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.18.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.18.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.18.0</version>
</dependency>
<!-- flink基础依赖 end -->
</dependencies>
<!--编译打包-->
<build>
<finalName>${project.name}</finalName>
<!--资源文件打包-->
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>org.google.code.flindbugs:jar305</exclude>
<exclude>org.slf4j:*</exclude>
<excluder>org.apache.logging.log4j:*</excluder>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.aurora.KafkaStreamingJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<!--插件统一管理-->
<pluginManagement>
<plugins>
<!--maven打包插件-->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
<configuration>
<fork>true</fork>
<finalName>${project.build.finalName}</finalName>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<!--编译打包插件-->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.plugin.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
9.2 log4j2.properties配置
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmprootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmp
9.3 Watermark水印作业
package com.aurora.demo;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.eventtime.TimestampAssigner;
import org.apache.flink.api.common.eventtime.TimestampAssignerSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.Random;
/**
* 描述:Flink集成Watermark水印
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-08 10:31:40
*/
public class WatermarkStreamingJob {
private static final Logger logger = LoggerFactory.getLogger(WatermarkStreamingJob.class);
public static void main(String[] args) throws Exception {
// 创建 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 自定义数据源,每隔1000ms下发一条数据
SourceFunction<JSONObject> dataSource = new SourceFunction<>() {
private volatile boolean running = true;
@Override
public void run(SourceContext<JSONObject> sourceContext) throws Exception {
while (running) {
long timestamp = System.currentTimeMillis();
timestamp = timestamp - new Random().nextInt(11) + 10;
// 将时间戳转换为 LocalDateTime 对象
LocalDateTime dateTime = LocalDateTime.ofInstant(Instant.ofEpochSecond(timestamp), ZoneId.systemDefault());
// 定义日期时间格式
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 格式化日期时间对象为指定格式的字符串
String format = formatter.format(dateTime);
JSONObject dataObj = new JSONObject();
int transId = 8;
dataObj.put("userId", "user_" + transId);
dataObj.put("timestamp", timestamp);
dataObj.put("datetime", format);
dataObj.put("url", "example.com/page" + transId);
logger.info("数据源url={},用户={},交易时间={},系统时间={}", "example.com/page" + transId, "user_" + transId, format);
Thread.sleep(1000);
sourceContext.collect(dataObj);
}
}
@Override
public void cancel() {
running = false;
}
};
//创建水印策略处理事件发生时间
TimestampAssignerSupplier<JSONObject> timestampAssignerSupplier = new TimestampAssignerSupplier<JSONObject>() {
@Override
public TimestampAssigner<JSONObject> createTimestampAssigner(Context context) {
return new TimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
//使用自定义的事件发生时间来做水印,确保窗口统计的是按照我们的时间字段统计,提高准确度,否则默认使用消费时间
return element.getLong("timestamp");
}
};
}
};
//创建数据流
env.addSource(dataSource).assignTimestampsAndWatermarks(WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner(timestampAssignerSupplier))
//按照url分组
.keyBy(new KeySelector<JSONObject, Object>() {
@Override
public Object getKey(JSONObject jsonObject) throws Exception {
return jsonObject.getString("url");
}
})
.window(TumblingEventTimeWindows.of(Time.seconds(2)))
.reduce(new ReduceFunction<JSONObject>() {
@Override
public JSONObject reduce(JSONObject reduceResult, JSONObject record) throws Exception {
logger.info("窗口统计url={},用户流水={},次数={}", reduceResult.getString("url"), reduceResult.getString("userId"), reduceResult.getInteger("urlNum") == null ? 1 : reduceResult.getInteger("urlNum"));
int urlNum = reduceResult.getInteger("urlNum") == null ? 1 : reduceResult.getInteger("urlNum");
reduceResult.put("urlNum", urlNum + 1);
return reduceResult;
}
})
.print();
// 执行任务
env.execute("WatermarkStreamingJob");
}
}
到了这里,关于【天衍系列 03】深入理解Flink的Watermark:实时流处理的时间概念与乱序处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!