1.背景介绍
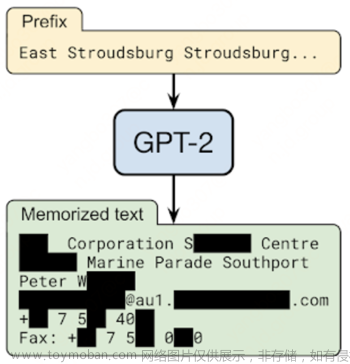
随着人工智能技术的发展,数据驱动的模型量化已经成为了主流的深度学习方法。然而,这种方法在处理敏感数据和模型安全方面面临着挑战。在这篇文章中,我们将讨论模型量化的安全与隐私保护,以及如何确保数据和模型的安全。
模型量化是指将深度学习模型从浮点数到整数域的转换。这种转换可以减少模型的存储和计算成本,从而提高模型的性能和可扩展性。然而,这种转换也可能导致数据泄露和模型安全问题。因此,在进行模型量化时,我们需要关注数据和模型的安全性。
2.核心概念与联系
在讨论模型量化的安全与隐私保护之前,我们需要了解一些核心概念。
2.1 模型量化
模型量化是指将深度学习模型从浮点数到整数域的转换。这种转换可以减少模型的存储和计算成本,从而提高模型的性能和可扩展性。
2.2 数据隐私
数据隐私是指保护个人信息不被未经授权的访问、收集、传输或处理。在模型量化中,数据隐私可能被破坏,因为模型可能会泄露敏感信息。
2.3 模型安全
模型安全是指保护模型免受恶意攻击和篡改。在模型量化中,模型安全可能被破坏,因为敌人可能会通过攻击模型来获取敏感信息或篡改模型的输出。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
在这一部分,我们将详细讲解模型量化的算法原理、具体操作步骤以及数学模型公式。
3.1 模型量化算法原理
模型量化算法的主要目标是将深度学习模型从浮点数到整数域的转换。这种转换可以减少模型的存储和计算成本,从而提高模型的性能和可扩展性。
模型量化算法通常包括以下几个步骤:
- 权重量化:将模型的权重从浮点数到整数域的转换。
- 操作量化:将模型的运算从浮点数到整数域的转换。
- 量化参数调整:根据模型的性能,调整量化参数。
3.2 权重量化
权重量化是指将模型的权重从浮点数到整数域的转换。这种转换可以减少模型的存储和计算成本,从而提高模型的性能和可扩展性。
权重量化的具体操作步骤如下:
- 对模型的权重进行归一化,使其值在0到1之间。
- 对归一化后的权重进行取整,将其转换为整数。
- 对整数权重进行缩放,使其值在预定义的范围内。
权重量化的数学模型公式如下:
$$ Q(x) = \lfloor C \cdot x + d \rfloor \mod p $$
其中,$Q(x)$ 表示量化后的权重,$x$ 表示原始权重,$C$ 表示缩放因子,$d$ 表示偏置,$p$ 表示量化范围。
3.3 操作量化
操作量化是指将模型的运算从浮点数到整数域的转换。这种转换可以减少模型的存储和计算成本,从而提高模型的性能和可扩展性。
操作量化的具体操作步骤如下:
- 对模型的运算进行归一化,使其值在0到1之间。
- 对归一化后的运算进行取整,将其转换为整数。
- 对整数运算进行缩放,使其值在预定义的范围内。
操作量化的数学模型公式如下:
$$ Q(x) = \lfloor C \cdot x + d \rfloor \mod p $$
其中,$Q(x)$ 表示量化后的运算,$x$ 表示原始运算,$C$ 表示缩放因子,$d$ 表示偏置,$p$ 表示量化范围。
3.4 量化参数调整
量化参数调整是指根据模型的性能,调整量化参数。这种调整可以确保模型的性能不受量化影响。
量化参数调整的具体操作步骤如下:
- 使用验证数据集评估模型的性能。
- 根据模型的性能,调整量化参数,如缩放因子和偏置。
- 使用调整后的量化参数重新训练模型。
量化参数调整的数学模型公式如下:
$$ Q(x) = \lfloor C \cdot x + d \rfloor \mod p $$
其中,$Q(x)$ 表示量化后的参数,$x$ 表示原始参数,$C$ 表示缩放因子,$d$ 表示偏置,$p$ 表示量化范围。
4.具体代码实例和详细解释说明
在这一部分,我们将通过一个具体的代码实例来解释模型量化的具体操作步骤。
4.1 权重量化代码实例
```python import numpy as np
原始权重
weights = np.random.rand(10, 10)
权重量化
def quantizeweights(weights, scalefactor, bias, quantizationrange): quantizedweights = np.floor(scalefactor * weights + bias) % quantizationrange return quantized_weights
量化参数
scalefactor = 256 bias = 128 quantizationrange = 256
量化后的权重
quantizedweights = quantizeweights(weights, scalefactor, bias, quantizationrange) ```
在上面的代码实例中,我们首先定义了原始权重,然后定义了权重量化的函数quantize_weights。接着,我们设置了量化参数,如缩放因子、偏置和量化范围。最后,我们调用了权重量化函数,将原始权重量化为整数域。
4.2 操作量化代码实例
```python import numpy as np
原始运算
operations = np.random.rand(10, 10)
运算量化
def quantizeoperations(operations, scalefactor, bias, quantizationrange): quantizedoperations = np.floor(scalefactor * operations + bias) % quantizationrange return quantized_operations
量化参数
scalefactor = 256 bias = 128 quantizationrange = 256
量化后的运算
quantizedoperations = quantizeoperations(operations, scalefactor, bias, quantizationrange) ```
在上面的代码实例中,我们首先定义了原始运算,然后定义了运算量化的函数quantize_operations。接着,我们设置了量化参数,如缩放因子、偏置和量化范围。最后,我们调用了运算量化函数,将原始运算量化为整数域。
5.未来发展趋势与挑战
在这一部分,我们将讨论模型量化的未来发展趋势与挑战。
5.1 未来发展趋势
模型量化的未来发展趋势包括以下几个方面:
- 更高效的量化算法:未来的研究可以关注更高效的量化算法,以提高模型的性能和可扩展性。
- 更安全的量化方法:未来的研究可以关注更安全的量化方法,以保护模型免受恶意攻击和篡改。
- 更智能的量化参数调整:未来的研究可以关注更智能的量化参数调整,以确保模型的性能不受量化影响。
5.2 挑战
模型量化的挑战包括以下几个方面:
- 数据泄露:模型量化可能导致数据泄露,因为模型可能会泄露敏感信息。
- 模型安全:模型量化可能导致模型安全问题,因为敌人可能会通过攻击模型来获取敏感信息或篡改模型的输出。
- 性能下降:模型量化可能导致模型性能下降,因为量化可能会导致模型的精度降低。
6.附录常见问题与解答
在这一部分,我们将回答一些常见问题。
6.1 问题1:模型量化会导致数据泄露吗?
答案:是的,模型量化可能导致数据泄露,因为模型可能会泄露敏感信息。为了解决这个问题,我们可以使用数据脱敏技术,如加密、掩码等方法,来保护数据的隐私。
6.2 问题2:模型量化会导致模型安全问题吗?
答案:是的,模型量化可能导致模型安全问题,因为敌人可能会通过攻击模型来获取敏感信息或篡改模型的输出。为了解决这个问题,我们可以使用模型安全技术,如模型加密、模型访问控制等方法,来保护模型的安全。文章来源:https://www.toymoban.com/news/detail-829637.html
6.3 问题3:模型量化会导致模型性能下降吗?
答案:是的,模型量化可能导致模型性能下降,因为量化可能会导致模型的精度降低。为了解决这个问题,我们可以使用精确量化技术,如非均匀量化、动态量化等方法,来提高模型的精度。文章来源地址https://www.toymoban.com/news/detail-829637.html
到了这里,关于模型量化的安全与隐私保护:如何确保数据和模型的安全的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!