在Python开发的爬虫项目中,requests和selenium是两个常用的库,它们各有特点和应用场景。
相同点
-
数据抓取: 无论是
selenium还是requests,两者的基本目的都是为了从网络上抓取数据。 - 自动化: 它们都能够自动化地访问网页,获取需要的信息。
不同点
-
工作原理:
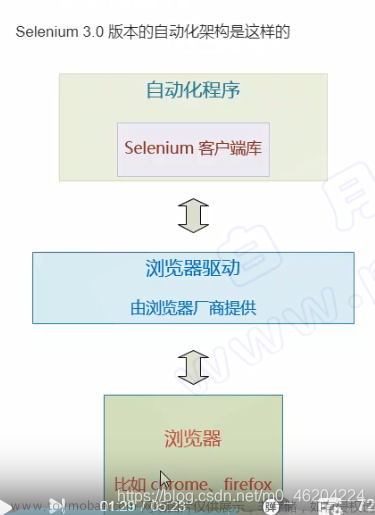
requests直接发送HTTP请求到服务器并获取响应,而selenium通过控制浏览器模拟用户的行为来获取数据。 -
运行环境:
requests是一个轻量级HTTP客户端,无需浏览器环境,而selenium需要与浏览器驱动和实例配合使用。 -
交互能力:
selenium能够执行JavaScript,模拟用户交互,如点击、滚动等,而requests仅能发送请求和接收响应。
优缺点
Requests:
-
优点:
- 速度快: 不加载JavaScript或CSS等资源,响应时间更短。
- 资源消耗少: 不需要浏览器环境,消耗的计算机资源更少。
- 简单易用: API简洁,易于理解和使用。
-
缺点:
- 功能有限: 不能处理JavaScript生成的内容或用户交互。
- 动态页面处理差: 对于AJAX或JavaScript重构的页面,无法直接获取数据。
Selenium:
-
优点:
- 交互能力强: 能够执行JavaScript,模拟用户的各种行为。
- 页面渲染: 可以处理复杂的Web应用程序,包括AJAX和Flash应用。
-
缺点:
-
速度慢: 加载完整的页面资源,速度比
requests慢。 - 资源消耗大: 需要浏览器环境,占用更多的CPU和内存资源。
- 环境依赖: 需要相应的浏览器和驱动程序。
-
速度慢: 加载完整的页面资源,速度比
Selenium常见问题与解决方法
- 环境配置: Selenium需要浏览器和对应的驱动,配置起来比较麻烦。解决办法: 自动化脚本安装和配置驱动,或使用容器化技术如Docker。
- 加载速度慢: 页面加载特别是JavaScript的运行需要时间。解决办法: 设置合理的超时时间,并在必要时使用显式等待。
- 反爬虫策略: 很多网站能检测到自动化的浏览器行为。解决办法: 使用代理,设置随机的用户代理,模拟真实用户行为。
Python爬虫:Requests VS Selenium
在Python爬虫的世界里,requests和selenium都扮演着重要的角色。这两个库虽然都可以用来抓取数据,但它们的工作原理、特点以及适用的场景大相径庭。
工作原理和特点
requests是一个HTTP库,用来发送各种HTTP请求。它的主要特点是简单、快速、轻量级。你可以用它获取静态页面的内容,通过发送GET或POST请求与服务器通信,但它不会加载JavaScript或CSS,不会等待页面上的动态内容加载完成。
相比之下,selenium是一个自动化测试工具,它通过控制浏览器来模拟用户的各种行为,如点击、滚动等。使用selenium可以解决由JavaScript动态生成的内容问题,因为它能够等待和执行JavaScript,获取渲染后的页面数据。
应用场景
因此,如果你的目标是抓取静态网页数据,使用requests会更加高效;而如果你需要从复杂的Web应用程序、SPA(单页面应用)或需要与页面交互来获取数据的网站中抓取数据,selenium可能是更好的选择。
性能考量
但是,selenium的缺点也很明显,它比requests慢得多,资源消耗也大得多。这是因为selenium模拟的是完整的浏览器环境,而requests只处理HTTP请求和响应。
常见问题与解决方法
使用selenium时,你可能会遇到一些配置和性能问题。例如,你需要确保所有环境都安装了合适的浏览器驱动,这可以通过自动化脚本或Docker容器来解决。另外,为了避免因页面加载慢而导致的超时问题,你应该使用合理的超时设置,并利用selenium的显式等待功能来等待特定元素的加载。
最后,由于selenium可以被一些网站检测到,因此你可能需要使用代理和随机用户代理来模拟真实用户的行为,避免被网站封锁。文章来源:https://www.toymoban.com/news/detail-830318.html
结论
总之,选择requests还是selenium,取决于你的具体需求。如果你可以直接通过API或简单的HTTP请求获取数据,那么requests是最佳选择。但如果你需要处理复杂的JavaScript或用户交互,那么selenium可能是必要的。在某些复杂的爬虫项目中,甚至可能需要组合使用这两个强大的工具。文章来源地址https://www.toymoban.com/news/detail-830318.html
到了这里,关于网络请求爬虫【requests】和自动化爬虫【selenium】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!