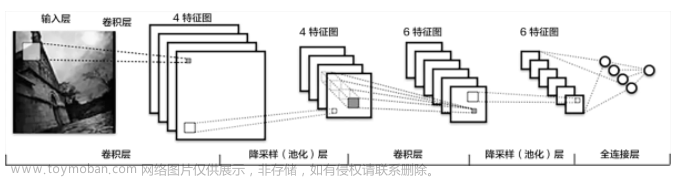
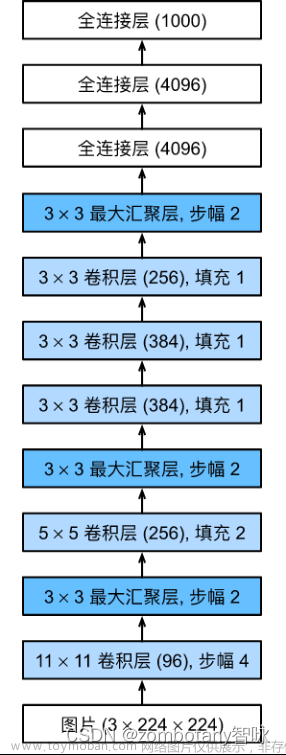
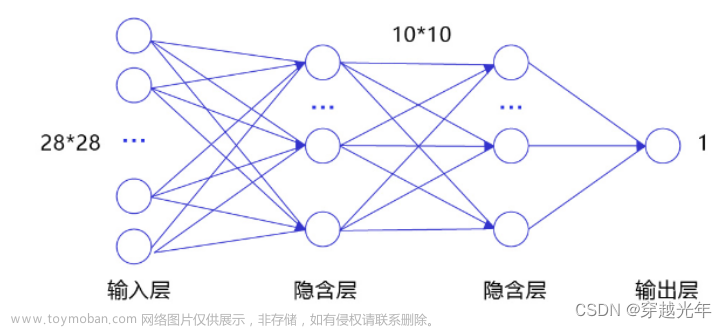
文档类图像的智能识别是利用人工智能技术对文档图像进行自动识别和信息提取的过程。在实际应用中,文档分类是文档类图像识别的一个重要环节,而自定义分类器则可以提高文档分类的准确性和适应性。本文将介绍文档分类自定义分类器的相关概念和方法。
1. 文档分类概述
文档分类是指将文档图像按照预设的类别进行划分和归类。在实际应用中,文档分类可以帮助用户快速找到所需的信息,提高工作效率。常见的文档分类包括:
- 证件分类:如身份证、护照、驾驶证等。
- 表格分类:如工资表、成绩单、财务报表等。
- 简历分类:如个人简历、企业简历等。
- 文献分类:如学术论文、专利文献等。
2. 自定义分类器概述
自定义分类器是指根据用户的需求和场景,自行设计和训练的分类器。自定义分类器的优势在于:
- 提高分类准确性:自定义分类器可以针对特定的应用场景和需求进行优化,从而提高分类准确性。
- 增强适应性:自定义分类器可以随着业务的发展和变化进行调整和优化,具有较强的适应性。
- 保护隐私:自定义分类器可以避免使用公开的预训练模型,从而保护数据隐私。
3. 自定义分类器的方法
自定义分类器的方法主要包括以下几个步骤:
3.1 数据收集与预处理
收集用于训练自定义分类器的数据,并对数据进行预处理。预处理包括:
- 数据清洗:去除噪声和异常数据。
- 数据标注:对数据进行分类标注,为训练分类器提供标签。
- 数据增强:通过旋转、缩放、裁剪等方法扩充数据集。
3.2 选择合适的深度学习模型
根据文档分类的需求,选择合适的深度学习模型作为基础模型。常见的深度学习模型包括卷积神经网络(CNN)、循环神经网络(RNN)和Transformer等。
3.3 模型训练与调优
使用收集和预处理的数据集对基础模型进行训练。在训练过程中,可以采用以下方法进行调优:
- 调整超参数:如学习率、批量大小、迭代次数等。
- 数据增强:在训练过程中继续对数据进行增强。
- 模型正则化:采用Dropout、权重衰减等方法防止过拟合。
3.4 模型评估与优化
在训练过程中,定期评估模型的性能。评估指标可以采用准确率、召回率、F1值等。根据评估结果,对模型进行优化和调整。
3.5 模型部署与应用
将训练好的模型部署到实际应用场景中,如文档分类、信息提取等。在实际应用中,可以结合业务需求对模型进行持续优化和调整。
4. 总结
文档类图像的智能识别在实际应用中具有重要意义。通过自定义分类器,可以提高文档分类的准确性和适应性。文档分类自定义分类器的方法包括数据收集与预处理、选择合适的深度学习模型、模型训练与调优、模型评估与优化以及模型部署与应用。随着人工智能技术的不断发展,未来文档分类自定义分类器的性能和功能将得到进一步提升。文章来源地址https://www.toymoban.com/news/detail-830352.html
文章来源:https://www.toymoban.com/news/detail-830352.html
到了这里,关于文档类图像的智能识别,文档分类自定义分类器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!