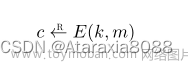斯坦福新算法DPO革新AI训练!无需强化学习也能微调对齐大语言模型
引言:探索无监督语言模型的可控性挑战
在人工智能领域,无监督语言模型(Language Models, LMs)的发展已经达到了令人惊叹的水平,这些模型能够在广泛的数据集上进行预训练,学习到丰富的世界知识和一定的推理能力。然而,如何精确控制这些模型的行为,使其按照人类的偏好和目标行动,一直是一个难题。这主要是因为这些模型的训练完全是无监督的,它们从人类生成的数据中学习,而这些数据背后的目标、优先级和技能水平五花八门。例如,我们希望人工智能编程助手能够理解常见的编程错误以便纠正它们,但在生成代码时,我们又希望模型能偏向于它训练数据中的高质量编码能力,即使这种能力可能相对罕见。
现有的方法通常通过强化学习(Reinforcement Learning, RL)来引导LMs符合人类的偏好,这些方法需要收集关于模型生成内容相对质量的人类标签,并通过微调(fine-tuning)来使无监督LM与这些偏好对齐。然而,强化学习从人类反馈(RLHF)的过程复杂且通常不稳定,它首先需要拟合一个反映人类偏好的奖励模型,然后使用强化学习来微调大型无监督LM,以最大化这个估计的奖励,同时又不能偏离原始模型太远。
本文介绍了一种新的奖励模型参数化方法,该方法在RLHF中能够以闭合形式提取相应的最优策略,允许我们仅使用简单的分类损失来解决标准的RLHF问题。这一算法,我们称之为直接偏好优化(Direct Preference Optimization, DPO),稳定、高效且计算成本低,无需在微调期间从LM中采样或进行大量超参数调整。我们的实验表明,DPO能够与现有方法一样好或更好地微调LMs以符合人类偏好。值得注意的是,使用DPO进行微调在控制生成情感方面超过了基于PPO的RLHF,并在摘要和单轮对话响应质量上匹敌或改进,同时实现方式大大简化,训练更加直接。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核后发布。
智能体传送门:赛博马良-AI论文解读达人文章来源:https://www.toymoban.com/news/detail-830477.html
神奇口令: 小瑶读者 (前100位有效)文章来源地址https://www.toymoban.com/news/detail-830477.html
1. 论文标题、机构、论文链接和项目地址(如有)。
- 论文标题:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- 机构:Stanford University, CZ Biohub
- 论文链接:arXiv:2305.18290
直接偏好优化(DPO)简介
1. DPO与传统RLHF方法的对比
直接偏好优化(Direct Preference Optimization,简称DPO)是一种新型的算法,它与传统的基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,简称RLHF)方法相比,具有显著的不同。RLHF方法通常通过收集人类对模型生成内容的相对质量标签,然后对未监督的语言模型(LM)进行微调,使其与这些偏好对齐。这一过程涉及到先拟合一个反映人类偏好的奖励模型,然后使用强化学习对大型未监督LM进行微调,以最大化这一估计的奖励,同时不过分偏离原始模型。然而,RLHF是一个复杂且通常不稳定的过程,涉及训练多个LM,并在训练循环中从LM策略中采样,带来显著的计算成本。
与之相对,DPO通过一个简单的分类损失直接优化语言模型以符合人类偏好,无需显式的奖励建模或强化学习。DPO的更新增加了优先响应相对于非优先响应的相对对数概率,但它包含了一个动态的、每个示例的重要性权重,防止了模型退化,这是使用简单概率比目标时发现的问题。DPO利用理论偏好模型(如Bradley-Terry模型)来测量给定奖励函数与经验偏好数据的一致性,但与现有方法使用偏好模型来定义奖励模型的训练偏好损失不同,DPO通过变量变换直接将偏好损失定义为策略的函数。因此,DPO可以使用一个简单的二元交叉熵目标来优化策略,产生一个隐含的奖励函数的最优策略。
2. DPO的工作原理与优势
DPO的工作原理基于将奖励函数转换为最优策略的分析映射,这使得我们能够将奖励函数上的损失函数转换为策略上的损失函数。这种变量变换方法避免了拟合一个显式的、独立的奖励模型,同时仍然在现有的人类偏好模型(如Bradley-Terry模型)下进行优化。本质上,策略网络同时代表了语言模型和(隐含的)奖励。
DPO的主要贡献是提供了一种简单的、无需强化学习的算法,用于根据偏好训练语言模型。实验表明,DPO至少与现有方法一样有效,包括基于PPO的RLHF,在诸如情感调节、摘要和对话等任务中从偏好中学习,使用多达6B参数的语言模型。
实验设计:评估DPO在不同文本生成任务中的表现
1. 实验任务介绍:情感生成、摘要和单轮对话
实验任务涉及三种不同的开放式文本生成任务。在控制情感生成中,x是IMDb数据集中电影评论的前缀,策略必须生成具有积极情感的y。在摘要任务中,x是Reddit论坛帖子,策略必须生成帖子主要观点的摘要y。最后,在单轮对话中,x是人类查询,可能是关于天体物理学的问题或寻求恋爱关系的建议,策略必须产生一个有趣且有帮助的响应y。
2. 实验评估方法:GPT-4胜率评估与人类判断验证
实验使用两种不同的评估方法。为了分析每种算法在优化受限奖励最大化目标的有效性,在控制情感生成设置中,通过计算每种算法与参考策略的KL散度,评估每种算法的前沿。然而,在现实世界中,真实的奖励函数是未知的;因此,使用GPT-4作为摘要质量和单轮对话响应有用性的代理,评估算法的胜率。对于摘要,我们使用测试集中的参考摘要作为基线;对于对话,我们使用测试数据集中的首选响应作为基线。尽管现有研究表明LM可以是比现有指标更好的自动评估者,但我们进行了人类研究来证明我们使用GPT-4进行评估的合理性。我们发现GPT-4的判断与人类高度相关,人类与GPT-4的一致性通常与人与人之间的注释者一致性相似或更高。
实验结果:DPO在多个任务中的性能表现
1. DPO与PPO在情感生成任务中的对比
在情感生成任务中,Direct Preference Optimization (DPO) 与 Proximal Policy Optimization (PPO) 进行了对比。DPO 通过简单的分类损失直接优化模型以符合人类偏好,而无需显式的奖励建模或强化学习。实验结果表明,DPO 在控制生成情感的能力上超越了基于 PPO 的 RLHF 方法,并且在摘要和单轮对话任务中匹配或提高了响应质量,同时实现了更简单的实施和训练过程。
2. DPO在摘要和单轮对话任务中的胜率分析
在摘要任务中,DPO 通过与人类写的摘要进行比较,使用 GPT-4 作为评估器,展示了其性能。DPO 在温度为 0.0 时的胜率约为 61%,超过了 PPO 在其最佳采样温度 0.0 时的 57% 胜率。在单轮对话任务中,DPO 与 Anthropic Helpful and Harmless 对话数据集中的人类偏好响应进行了比较。DPO 是唯一一种在 Anthropic HH 数据集测试集中改进过的选择摘要的方法,并且与计算上要求高的最佳 128 基线相比,提供了类似或更好的性能。
理论分析:DPO的理论基础与潜在优势
1. 语言模型作为隐式奖励模型的理论支持
DPO 方法能够绕过显式奖励拟合和执行 RL 学习策略,使用单一的最大似然目标。优化目标等同于在奖励参数化下的 Bradley-Terry 模型,其中奖励参数化为 r∗(x, y) = β log π∗(y|x) / πref(y|x),并且通过变量变换优化参数模型 πθ,等效于奖励模型优化。这种重新参数化不会限制学习奖励模型的类别,并允许精确恢复最优策略。
2. DPO的优化目标与理论属性
DPO 的更新直观上增加了偏好完成 yw 的相对对数概率,并降低了不受偏好的完成 yl 的概率。重要的是,示例通过隐式奖励模型 ˆrθ 评估不受偏好完成的程度进行加权,这考虑了 KL 约束的强度。DPO 的一般流程包括:1) 对于每个提示 x,采样完成 y1, y2 ∼ πref(·|x),并使用人类偏好构建离线偏好数据集 D;2) 优化语言模型 πθ 以最小化给定 πref 和 D 以及所需的 β 的 LDPO。实验表明,DPO 在没有显著超参数调整的情况下,至少与现有方法一样有效,包括基于 PPO 的 RLHF,用于从偏好中学习任务,如情感调节、摘要和对话。
讨论与未来展望
1. DPO在偏好学习框架中的地位与影响
Direct Preference Optimization(DPO)作为一种新型的偏好学习方法,其在未来的发展中扮演着重要角色。DPO通过简单的分类损失直接优化语言模型以符合人类偏好,避免了传统的强化学习方法中对奖励模型的显式拟合。这种方法的提出,不仅简化了训练流程,还降低了计算成本,使得语言模型的训练更加高效和稳定。在实验中,DPO在情感调节、摘要生成和单轮对话等任务上展现了与现有方法相当或更优的性能,尤其是在控制生成文本的情感方面,DPO超越了基于PPO的RLHF方法,并在摘要和对话响应质量上达到或超越了现有方法,同时实现了更简单的实施和训练过程。
2. DPO的局限性与未来研究方向
尽管DPO在偏好学习中展现出显著的优势,但其仍存在一些局限性。首先,DPO如何在分布外的泛化能力上与显式奖励函数学习的策略相比尚不明确。初步结果表明,DPO策略在泛化方面与基于PPO的模型相似,但需要更全面的研究来验证这一点。其次,DPO在没有灾难性遗忘的情况下对语言模型进行微调的能力还有待进一步探索。此外,DPO对于大规模模型的扩展性也是未来研究的一个激动人心的方向。在评估方面,GPT-4作为自动化系统的评估者的有效性也是未来研究的一个重要问题。最后,DPO除了在训练语言模型方面的应用外,还有许多潜在的应用领域,包括在其他模态中训练生成模型。
总结:DPO作为一种新型训练语言模型的方法
DPO通过直接优化语言模型以符合人类偏好,提供了一种无需强化学习的训练范式。DPO识别出语言模型策略与奖励函数之间的映射,使得可以直接使用简单的交叉熵损失来训练语言模型,而不牺牲一般性。DPO的性能与现有基于PPO的RLHF算法相当或更优,且几乎不需要调整超参数,从而显著降低了从人类偏好中训练更多语言模型的障碍。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核后发布。
智能体传送门:赛博马良-AI论文解读达人
神奇口令: 小瑶读者 (前100位有效)
到了这里,关于十分钟读完「斯坦福提出的革新AI训练的新算法DPO」论文的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!