扣字和分割
把图片中的文字,识别出来,并将每个字的图片抠出来;
import cv2
import numpy as np
HIOG = 50
VIOG = 3
Position = []
'''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
# 获取图像大小
(h,w)=image.shape
# 统计像素个数
h_ = [0]*h
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
# cv2.imshow('hProjection2',cv2.resize(hProjection, None, fx=0.3, fy=0.5, interpolation=cv2.INTER_AREA))
# cv2.waitKey(0)
return h_
def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
(h,w) = image.shape
w_ = [0]*w
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
# cv2.imshow('vProjection',cv2.resize(vProjection, None, fx=1, fy=0.1, interpolation=cv2.INTER_AREA))
# cv2.waitKey(0)
return w_
def scan(vProjection, iog, pos = 0):
start = 0
V_start = []
V_end = []
for i in range(len(vProjection)):
if vProjection[i] > iog and start == 0:
V_start.append(i)
start = 1
if vProjection[i] <= iog and start == 1:
if i - V_start[-1] < pos:
continue
V_end.append(i)
start = 0
return V_start, V_end
def checkSingle(image):
h = getHProjection(image)
start = 0
end = 0
for i in range(h):
pass
#分割
def CropImage(image,dest,boxMin,boxMax):
a=boxMin[1]
b=boxMax[1]
c=boxMin[0]
d=boxMax[0]
cropImg = image[a:b,c:d]
cv2.imwrite(dest,cropImg)
#开始识别
def DOIT(rawPic):
# 读入原始图像
origineImage = cv2.imread(rawPic)
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
# cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
# kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
# img = cv2.erode(img, kernel)
# cv2.imshow('binary',cv2.resize(img, None, fx=0.3, fy=0.3, interpolation=cv2.INTER_AREA))
#图像高与宽
(h,w)=img.shape
#垂直投影
V = getVProjection(img)
start = 0
V_start = []
V_end = []
# 对垂直投影水平分割
V_start, V_end = scan(V, HIOG)
if len(V_start) > len(V_end):
V_end.append(w-5)
# 分割行,分割之后再进行列分割并保存分割位置
for i in range(len(V_end)):
#获取行图像
if V_end[i] - V_start[i] < 30:
continue
cropImg = img[0:h, V_start[i]:V_end[i]]
# cv2.imshow('cropImg',cropImg)
# cv2.waitKey(0)
#对行图像进行垂直投影
H = getHProjection(cropImg)
H_start, H_end = scan(H, VIOG, 40)
if len(H_start) > len(H_end):
H_end.append(h-5)
for pos in range(len(H_start)):
# 再进行一次列扫描
DcropImg = cropImg[H_start[pos]:H_end[pos], 0:w]
d_h, d_w = DcropImg.shape
# cv2.imshow("dcrop", DcropImg)
sec_V = getVProjection(DcropImg)
c1, c2 = scan(sec_V, 0)
if len(c1) > len(c2):
c2.append(d_w)
x = 1
while x < len(c1):
if c1[x] - c2[x-1] < 12:
c2.pop(x-1)
c1.pop(x)
x -= 1
x += 1
# cv2.waitKey(0)
if len(c1) == 1:
Position.append([V_start[i],H_start[pos],V_end[i],H_end[pos]])
else:
for x in range(len(c1)):
Position.append([V_start[i]+c1[x], H_start[pos],V_start[i]+c2[x], H_end[pos]])
#根据确定的位置分割字符
number=0
for m in range(len(Position)):
rectMin = (Position[m][0]-5,Position[m][1]-5)
rectMax = (Position[m][2]+5,Position[m][3]+5)
cv2.rectangle(origineImage,rectMin, rectMax, (0 ,0 ,255), 2)
number=number+1
#start-crop
CropImage(origineImage,'result/' + '%d.jpg' % number,rectMin,rectMax)
# cv2.imshow('image',cv2.resize(origineImage, None, fx=0.6, fy=0.6, interpolation=cv2.INTER_AREA))
cv2.imshow('image',origineImage)
cv2.imwrite('result/' + 'ResultImage.jpg' , origineImage)
cv2.waitKey(0)
#############################
rawPicPath = r"H:\TEMP\TEXT_PROCCESS\TEST05.jpg"
DOIT(rawPicPath)
#############################
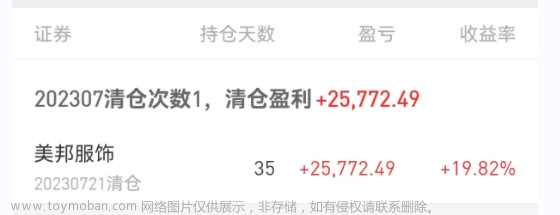
原图片:

分割后文件夹:

重命名
可见此时文件都还是数字为文件名称,那么接下来要利用OCR自动给每个文字图片文件命名
我们使用UMIOCR , UMI-OCR的安装建议去GITHUB上查,windows上部署还是很方便的;
这里使用本机安装好的UMI-OCR 的 API地址 http://127.0.0.1:1224/api/ocr
先定义API调用方法
############################################
import base64
import requests
import json
#API访问使用
def UMI_OCR_OPT(url,img_path):
# url = "http://127.0.0.1:1224/api/ocr"
# img_path= './result/123.jpg'
with open(img_path,'rb') as f:
image_base64 = base64.b64encode(f.read())
image_base64 =str(image_base64,'utf-8')
data = {
"base64": image_base64,
# 可选参数
# Paddle引擎模式
# "options": {
# "ocr.language": "models/config_chinese.txt",
# "ocr.cls": False,
# "ocr.limit_side_len": 960,
# "tbpu.parser": "MergeLine",
# }
# Rapid引擎模式
# "options": {
# "ocr.language": "简体中文",
# "ocr.angle": False,
# "ocr.maxSideLen": 1024,
# "tbpu.parser": "MergeLine",
# }
}
headers = {"Content-Type": "application/json"}
data_str = json.dumps(data)
response = requests.post(url, data=data_str, headers=headers)
if response.status_code == 200:
res_dict = json.loads(response.text)
#检测失败与否
if(str(res_dict).find('No text found in image')!=-1):
# print("返回失败内容\n", res_dict)
return ''
print("返回值字典\n", res_dict)
resText = res_dict['data'][0]['text']
return resText
return ''
开始批量调用检测
import easyocr
import shutil
error =''
#api地址
uni_orc_url="http://127.0.0.1:1224/api/ocr"
#将所有字体
for i in range(1,285):
filePath = "./result/"+str(i)+".jpg"
# result = reader.readtext(filePath, detail = 0)
result = UMI_OCR_OPT(uni_orc_url,filePath)
if(len(result)==0 or result == ''):
error+= filePath +'\n'
continue
print(result)
destPath = "./resultX/"+result[0]+".jpg"
print('sour :: '+ filePath)
print('dest :: '+ destPath)
shutil.copyfile(filePath, destPath)
print('error:\n'+error)
然后将能够识别出来的所有文字图片都复制并重命名为该字
效果如下:文章来源:https://www.toymoban.com/news/detail-830631.html
 文章来源地址https://www.toymoban.com/news/detail-830631.html
文章来源地址https://www.toymoban.com/news/detail-830631.html
到了这里,关于使用Python+OpenCV2进行图片中的文字分割(支持竖版)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!