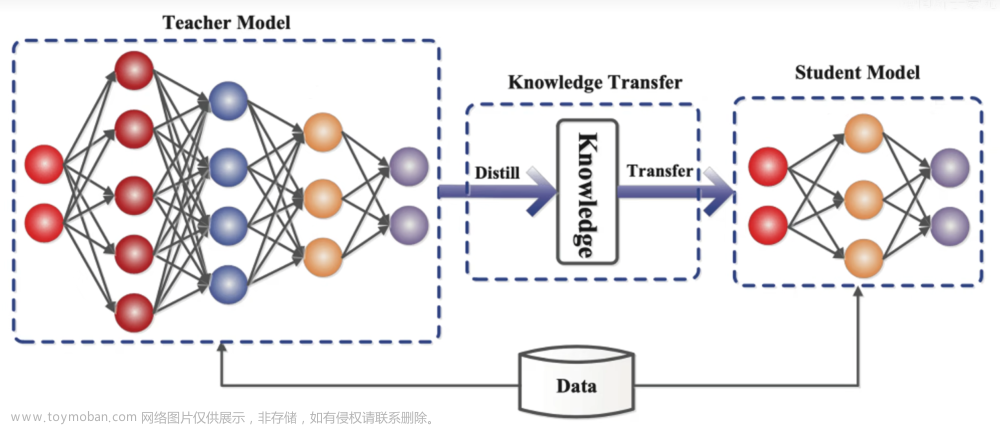
一、知识蒸馏的来源
知识蒸馏(Knowledge Distillation)源自于一篇由Hinton等人于2015年提出的论文《Distilling the Knowledge in a Neural Network》。这个方法旨在将一个大型、复杂的模型的知识(通常称为教师模型)转移到一个小型、简化的模型(通常称为学生模型)中。通过这种方式,学生模型可以获得与教师模型相似的性能,同时具有更小的模型体积和计算资源需求。
二、知识蒸馏的原理
知识蒸馏的核心思想是利用教师模型的输出作为附加的监督信号来训练学生模型。在传统的监督学习中,目标是最小化模型预测与真实标签之间的差距(损失函数)。而在知识蒸馏中,除了最小化模型预测与真实标签之间的差距外,还引入了一个额外的损失项,该项衡量了学生模型预测与教师模型预测之间的距离。
具体而言,损失函数通常由两部分组成:一部分是传统的交叉熵损失,用于衡量学生模型的预测与真实标签之间的差距;另一部分是知识蒸馏损失,用于衡量学生模型的预测与教师模型的预测之间的差距。知识蒸馏损失通常使用一些形式的距离度量来计算,例如平方误差损失或者交叉熵损失。
在蒸馏求loss时候,需要采用蒸馏函数,这个函数就是把softmax函数在计算时候,预测出来的结果Z进行除以温度T,进行求解后验概率。下面是修改后的softmax函数,也就是蒸馏函数。

T表示蒸馏的温度,T=1时即为softmax。


上述两张图就是知识蒸馏模型的全过程。下面小编用通俗的语言来解释一下具体如何实现的。
具体过程:
(1)首先我们要先训练出较大模型既teacher模型。(在图中没有出现)
(2)再对teacher模型进行蒸馏,此时我们已经有一个训练好的teacher模型,所以我们能很容易知道teacher模型输入特征x之后,预测出来的结果teacher_preds标签。
(3)此时,求到老师预测结果之后,我们需要求解学生在训练过程中的每一次结果student_preds标签。
(4)先求hard_loss,也就是学生模型的预测student_preds与真实标签targets之间的损失。
(5)再求soft_loss,也就是学生模型的预测student_preds与教师模型teacher_preds的预测之间的损失。
(6)求出hard_loss与soft_loss之后,求和总loss=a*hard_loss + (1-a)soft_loss,a是一个自己设置的权重参数,我在代码中设置为a=0.3。
(7)最后反向传播继续迭代。
三、知识蒸馏的作用
(1)模型压缩和加速:知识蒸馏可以将大型的复杂模型(如深度神经网络)转换成小型的简化模型,从而减少了模型的存储空间和计算资源需求,使得模型更适合在资源受限的设备上部署和运行,如移动设备或嵌入式系统。
(2) 迁移学习和模型微调:通过知识蒸馏,可以将一个在大规模数据集上训练的模型的知识迁移到一个相似但规模较小的模型上,这有助于在资源受限的情况下进行迁移学习或模型微调。
(3)提高模型泛化性能:知识蒸馏还可以帮助提高模型的泛化性能,因为学生模型在训练过程中利用了教师模型的“软标签”,这些软标签包含了教师模型对数据分布的更丰富的信息,有助于减少过拟合。
四、代码实战部分
最后的代码实战部分,小编另外一章博客来讲述。文章来源:https://www.toymoban.com/news/detail-830680.html
博客地址:知识蒸馏实战代码教学二(代码实战部分)-CSDN博客文章来源地址https://www.toymoban.com/news/detail-830680.html
到了这里,关于知识蒸馏实战代码教学一(原理部分)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!