系列文章目录
`
前言
一、基本构成
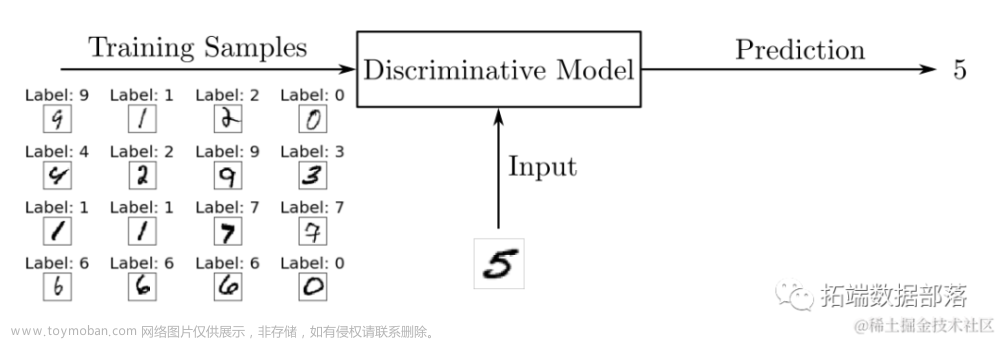
GAN (Generative Adversarial Network) : 通过两个神经网络,即生成器(Generator)和判别器(Discriminator),相互竞争来学习数据分布。
{ 生成器 ( G e n e r a t o r ) : 负责从随机噪声中学习生成与真实数据相似的数据。 判别器 ( D i s c r i m i n a t o r ) : 尝试区分生成的数据和真实数据。 \left\{ \begin{array}{l} 生成器(Generator):负责从随机噪声中学习生成与真实数据相似的数据。 \\ \\ 判别器(Discriminator):尝试区分生成的数据和真实数据。 \\ \end{array}\right. ⎩ ⎨ ⎧生成器(Generator):负责从随机噪声中学习生成与真实数据相似的数据。判别器(Discriminator):尝试区分生成的数据和真实数据。
二、应用领域
-
图像生成:如风格迁移、人脸生成等。
-
数据增强:通过生成额外的样本来增强训练集。
-
医学图像分析:例如通过GAN生成医学图像以辅助诊断。
-
图像超分辨:SRGAN
三、基本原理
GANs的目标是通过学习一个生成模型G来尽可能接近真实数据分布。

生成网络采用随机输入,G(z)从P(z)获取输入z(noise),其中z是来自概率分布P(z)的样本,z~P(z),生成器产生Fake Samples送入D(x)。
Pdata(x) ------真实数据的分布 x-----Pdata(x)的样本
P(z)------生成器的分布 z-----P(z)的样本
G(z)-----生成网络 D(x)----判别网络
x 是一个真实图片,可以想象成一个向量,这个向量分布集合就是Pdata(x)
目标是min G ~=0
max D ~=1
生成器的目标是最大化判别器对其生成样本的错误分类概率,其中,(G(z)) 表示生成器从随机噪声 (z) 生成的样本,(D(x)) 是判别器对样本 (x) 为真实的概率估计。
上面目标函数实际上是两个二元交叉熵的和,其对应于判别器D对真实样本和生成样本的分类能力。判别器D的目标是最大化以下目标函数,找到能够最小化的生成器G。
V(D,G) :判别器最大化,生成器想最小化
第一项:是实际分布Pdata(x)的数据,通过判别器的熵,试图将其最大化为1
第二项:是随机输入P(Z)的数据通过G的熵,判别器尝试将其最小化为0
对抗损失函数一般由两部分组成:
判别器的损失项(Discriminator Loss):这一部分表示判别器要尽可能准确地区分真实数据和生成器生成的数据。判别器试图最大化这个值,以便更好地区分真实数据和生成的数据。
生成器的损失项(Generator Loss):这一部分表示生成器试图生成足够逼真的数据,以至于判别器无法轻易区分生成的数据和真实数据。生成器试图最小化这个值。
具体来说,判别器的损失项旨在最大化以下两个期望值:
真实数据的判别概率(判别器越接近1越好)
生成数据的判别概率(判别器越接近0越好)
而生成器的损失项旨在最小化生成数据的判别概率(生成器希望判别器难以将其识别为生成数据)。
通过优化这个对抗损失函数,生成器和判别器不断调整自己的参数,最终使得生成器可以生成非常逼真的数据,同时判别器难以区分真实数据和生成的数据。
四、如何训练GAN
- 训练判别器,冻结生成器
- 训练生成器,冻结判别器
冻结:即不训练,神经网络只进行前向传播不进行反向传播
训练步骤:
step1: 定义问题,生成假图像还是文字,收集相应数据
step2: 定义GAN的架构,生成器和判别器可以使用多层感知机或者卷积神经网络
step3: 用真实数据训练N个epoch,训练判别器正确预测假的数据为假
step4: 用生成器产生假的输入数据,用来训练判别器,训练判别器正确预测假的数据为假
step5: 用判别器的输出来训练生成器 当判别器被训练后,将其预测值作为标记来训练生成器以迷惑判别器
step6: 重复3~5多个epoch
step7: 手动检查数据是否合理,合理即停止,否则回到step3
一般来说,Discrimnator比Genenrator训练的多,比如训练五次Discrimnator,再训练一次Genenrator。文章来源:https://www.toymoban.com/news/detail-830732.html
训练GAN时最重要的阻碍—稳定文章来源地址https://www.toymoban.com/news/detail-830732.html
到了这里,关于生成对抗网络----GAN的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!