美团面试:Kafka如何处理百万级消息队列?
在今天的大数据时代,处理海量数据已成为各行各业的标配。特别是在消息队列领域,Apache Kafka 作为一个分布式流处理平台,因其高吞吐量、可扩展性、容错性以及低延迟的特性而广受欢迎。但当面对真正的百万级甚至更高量级的消息处理时,如何有效地利用 Kafka,确保数据的快速、准确传输,成为了许多开发者和架构师思考的问题。本文将深入探讨 Kafka 的高级应用,通过10个实用技巧,帮助你掌握处理百万级消息队列的艺术。
引言
在一个秒杀系统中,瞬时的流量可能达到百万级别,这对数据处理系统提出了极高的要求。Kafka 作为消息队列的佼佼者,能够胜任这一挑战,但如何发挥其最大效能,是我们需要深入探讨的。本文不仅将分享实用的技巧,还会提供具体的代码示例,帮助你深入理解和应用 Kafka 来处理大规模消息队列。
正文
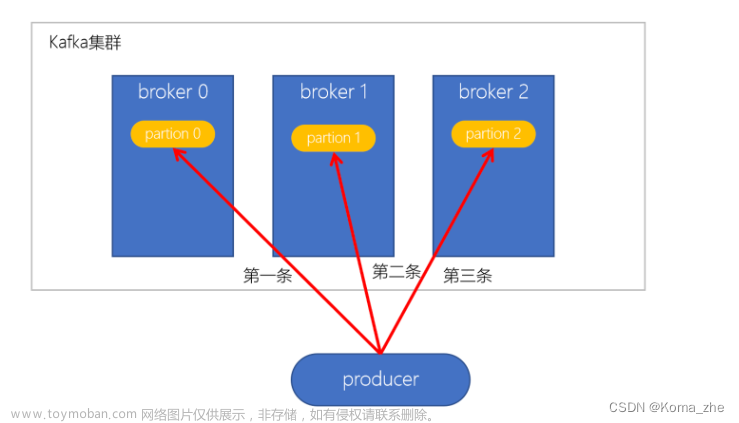
1、利用 Kafka 分区机制提高吞吐量
Kafka 通过分区机制来提高并行度,每个分区可以被一个消费者组中的一个消费者独立消费。合理规划分区数量,是提高 Kafka 处理能力的关键。
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-broker1:9092,kafka-broker2:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
// 发送消息
for(int i = 0; i < 1000000; i++) {
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), "message-" + i));
// my-topic:目标主题
// Integer.toString(i):消息的键(key),这里用作分区依据
// "message-" + i:消息的值(value)
}
producer.close();
`
2、合理配置消费者组以实现负载均衡
在 Kafka 中,消费者组可以实现消息的负载均衡。一个消费者组中的所有消费者共同消费多个分区的消息,但每个分区只能由一个消费者消费。
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-broker1:9092,kafka-broker2:9092");
props.put("group.id", "my-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
// 订阅主题
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
// 处理消息
}
}
3、使用 Kafka Streams 进行实时数据处理
Kafka Streams 是一个客户端库,用于构建实时应用程序和微服务,其中输入和输出数据都存储在 Kafka 中。你可以使用 Kafka Streams 来处理数据流。
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("my-input-topic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.as("counts-store"));
wordCounts.toStream().to("my-output-topic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
4、优化 Kafka 生产者和消费者的配置
通过调整 Kafka 生产者和消费者的配置,如 batch.size, linger.ms, buffer.memory 等,可以显著提高 Kafka 的性能。
// 生产者配置优化
props.put("linger.ms", 10);
props.put("batch.size", 16384);
props.put("buffer.memory", 33554432);
// 消费者配置优化
props.put("fetch.min.bytes", 1024);
props.put("fetch.max.wait.ms", 100);
5、使用压缩技术减少网络传输量
Kafka 支持多种压缩技术,如 GZIP、Snappy、LZ4、ZSTD,可以在生产者端进行配置,以减少数据在网络中的传输量。
props.put("compression.type", "snappy");
6、利用 Kafka Connect 集成外部系统
Kafka Connect 是用于将 Kafka 与外部系统(如数据库、键值存储、搜索引擎等)连接的框架,可以实现数据的实时导入和导出。
// 以连接到MySQL数据库为例
// 实际上需要配置Connect的配置文件
{
"name": "my-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "my-topic",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
}
}
7、监控 Kafka 性能指标
监控 Kafka 集群的性能指标对于维护系统的健康状态至关重要。可以使用 JMX 工具或 Kafka 自带的命令行工具来监控。
// 使用JMX监控Kafka性能指标的示例代码
//具体实现需要根据监控工具的API进行
8、实现高可用的 Kafka 集群
确保 Kafka 集群的高可用性,需要合理规划 Zookeeper 集群和 Kafka broker 的部署,以及配置恰当的副本数量。
// 在Kafka配置文件中设置副本因子
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
transaction.state.log.min.isr=2
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=zookeeper1:2181,zookeeper2:2181,zookeeper3:2181
zookeeper.connection.timeout.ms=6000
9、使用 Kafka 的事务功能保证消息的一致性
Kafka 0.11 版本引入了事务功能,可以在生产者和消费者之间保证消息的一致性。
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();
try {
producer.beginTransaction();
for(int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), "value-" + i));
}
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
producer.abortTransaction();
} catch (KafkaException e) {
// 处理异常
}
10、深入理解 Kafka 的内部工作原理
深入理解 Kafka 的内部工作原理,如分区策略、消息存储机制、消费者偏移量管理等,对于优化 Kafka 应用至关重要。
总结
Kafka 在处理百万级消息队列方面拥有无与伦比的能力,但要充分发挥其性能,需要深入理解其工作原理并合理配置。通过本文介绍的10个实用技巧及其代码示例,相信你已经有了处理百万级消息队列的信心和能力。记住,实践是检验真理的唯一标准,不妨在实际项目中尝试应用这些技巧,你会发现 Kafka 的强大功能及其对业务的巨大帮助。
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
项目文档&视频:
开源:项目文档 & 视频 Github-Doc
本文,已收录于,我的技术网站 aijiangsir.com,有大厂完整面经,工作技术,架构师成长之路,等经验分享文章来源:https://www.toymoban.com/news/detail-830850.html
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!文章来源地址https://www.toymoban.com/news/detail-830850.html
到了这里,关于美团面试:Kafka如何处理百万级消息队列?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!