MongoDB是一个非关系型数据库,以其高性能、可扩展性和灵活性而闻名。MongoDB的技术架构为其提供了强大的数据存储和处理能力,支持各种现代应用程序的需求。本文将深入探讨MongoDB的技术架构,帮助您更好地理解其内部工作原理。
一、MongoDB概述
MongoDB是一个面向文档的数据库,它以BSON(Binary JSON)格式存储数据。与关系型数据库不同,MongoDB没有固定的表结构,允许存储不同结构和类型的数据。这使得MongoDB非常适合处理半结构化和非结构化数据,如日志、社交媒体数据等。
MongoDB的主要特点包括:
- 高性能:MongoDB使用内存映射文件存储引擎(WiredTiger或MMAPv1),支持高速数据读写操作。
- 高可用性:MongoDB支持主从复制和分片集群,确保数据的高可用性和可扩展性。
- 灵活性:MongoDB支持动态模式,允许在运行时添加或删除字段。
- 丰富的查询语言:MongoDB提供强大的查询语言,支持聚合、文本搜索、地理空间查询等功能。
二、MongoDB技术架构
MongoDB的技术架构分为以下几个层次:
- 数据存储层:MongoDB使用内存映射文件存储引擎(如WiredTiger)将数据持久化到磁盘。存储引擎负责数据的读写、压缩、加密等操作。MongoDB将数据划分为多个集合(collection),每个集合包含多个文档(document)。文档是MongoDB的基本数据单位,以BSON格式存储。
- 数据模型层:MongoDB的数据模型基于文档,支持嵌套文档和数组。这使得MongoDB能够存储复杂的数据结构,如树形结构、图形数据等。MongoDB还提供了丰富的数据类型,如字符串、整数、浮点数、日期、二进制数据等。
- 查询语言层:MongoDB使用基于文档的查询语言(MongoDB Query Language,MQL),支持丰富的查询操作符和聚合管道。MQL允许用户根据文档的结构和内容进行查询,实现灵活的数据检索和分析。
- 索引层:MongoDB支持多种类型的索引,如单字段索引、复合索引、地理空间索引等。索引可以提高查询性能,加快数据的检索速度。MongoDB还支持索引交集和索引覆盖扫描等优化技术,进一步提高查询效率。
- 复制和分片层:MongoDB支持主从复制和分片集群,确保数据的高可用性和可扩展性。主从复制可以实现数据的备份和故障恢复;分片集群可以将数据分布在多个节点上,实现水平扩展和负载均衡。
- 事务层:MongoDB从4.0版本开始支持多文档事务,确保数据的一致性和完整性。事务是一系列操作的原子单位,要么全部成功,要么全部失败。MongoDB的事务支持隔离级别为“可重复读”(Read Committed),满足大多数应用程序的需求。
- 安全性和认证层:MongoDB提供了一系列安全特性,如身份验证、授权、加密等。身份验证可以确保只有授权的用户才能访问数据库;授权可以控制用户对数据库的访问权限;加密可以保护数据在传输和存储过程中的安全。
- 客户端驱动层:MongoDB提供了多种编程语言的客户端驱动,如Java、Python、Node.js等。客户端驱动负责与MongoDB服务器进行通信,实现数据的增删改查等操作。MongoDB的客户端驱动具有良好的兼容性和性能,方便开发者在各种环境中使用MongoDB。
三、MongoDB集群架构模式
MongoDB的三种主要集群架构模式分别是主从复制(Master-Slave)、副本集(Replica Set)和分片(Sharding)。
-
主从复制(Master-Slave):
这是一种简单的复制模式,其中一台服务器被配置为主服务器(Master),负责处理所有的写操作和部分读操作,而其他服务器则作为从服务器(Slave),主要处理读操作以及作为主服务器的备份。然而,主从复制模式存在一些缺点,例如,主节点故障时,系统无法自动切换,需要手动干预;同时,主从复制模式下数据一致性的保障也相对较弱。因此,MongoDB官方已经不建议在新的生产环境中使用这种模式。 -
副本集(Replica Set):
副本集是MongoDB推荐的生产环境部署模式。在副本集中,每个节点都可以担任主节点或从节点的角色,通过异步复制数据到多个服务器上,保证了数据的高可用性和冗余性。当主节点出现故障时,副本集可以自动进行故障切换,选择一个从节点成为新的主节点,从而保证了服务的连续性。此外,副本集还提供了数据冗余,增强了数据的容错能力。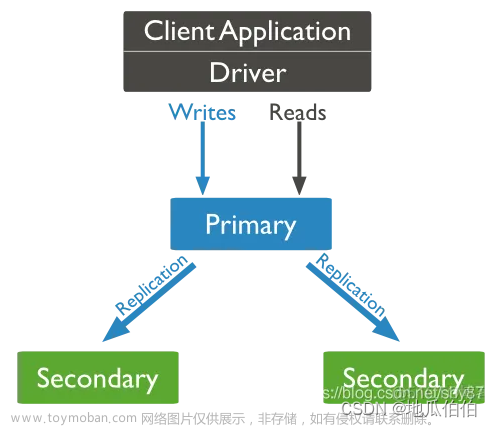
-
分片(Sharding):
分片是MongoDB处理大规模数据的核心技术。通过将数据分散存储到多个服务器上,分片可以显著提高系统的整体性能和可扩展性。每个分片都是一个独立的数据库,可以独立地进行数据复制和故障恢复。在实际生产环境中,通常将副本集和分片两种技术结合使用,以实现既高性能又高可用性的数据存储解决方案。
MongoDB分片集群中共有三种角色,它们分别是:
-
Shard角色(或称为分片服务器):
这是MongoDB分片集群中的数据节点,用于存储实际的数据块。在实际生产环境中,一个Shard角色可以由几台机器组成一个副本集(Replica Set)来承担,以防止主机单点故障,保证数据的高可用性和完整性。Shard角色可以是一个副本集,也可以是单独的一台服务器。 -
Config Server角色(或称为配置服务器):
这类角色主要用来保存MongoDB分片集群的元数据信息,包括各个分片包含了哪些数据的信息,以及数据块的分布信息等。Config Server角色通常由一个独立的mongod进程来运行,并且为了保证其高可用性,通常会将其运行为一个副本集。它不需要太多的存储空间,因为保存的只是数据的分布表。 -
Router角色(或称为路由服务器、mongos):
这是MongoDB分片集群中的前端路由,客户端由此接入,让整个集群看上去像单一数据库。Router角色主要用来接收客户端的读写请求,并将请求路由到相应的分片上进行处理。为了使得Router角色的高可用,通常会用多个节点来组成Router高可用集群。Router角色通常由mongos实例来运行。
以上三种角色共同协作,实现了MongoDB的分片集群功能,使得MongoDB能够支持大规模的数据存储和高并发的读写操作。
在MongoDB分片集群中,数据读写时的流程大致如下:
-
客户端发送请求:客户端通过MongoDB的驱动程序连接到Router角色(mongos实例)。客户端发送读写请求到Router,请求中包含了要操作的数据库、集合以及具体的CRUD(增删改查)操作。
-
Router路由请求:Router接收到客户端的请求后,会根据请求中的元数据信息(如数据库名、集合名和查询条件等),查询Config Server来获取数据的分片信息。Config Server返回相关的分片信息给Router,告诉它应该将数据路由到哪个Shard上进行处理。
-
Router转发请求:Router根据从Config Server获取的分片信息,将客户端的请求转发到相应的Shard上。如果请求涉及多个Shard上的数据(如跨分片的查询),Router可能会将请求拆分成多个子请求,并分别发送到相关的Shard上进行处理。
-
Shard处理请求:Shard接收到Router转发的请求后,会在本地执行相应的CRUD操作。如果是写操作(如插入、更新、删除),Shard会在本地进行数据变更,并将变更结果返回给Router;如果是读操作(如查询),Shard会查询本地存储的数据,并将查询结果返回给Router。
-
Router汇总结果:如果请求涉及多个Shard上的数据,Router会等待所有Shard返回结果后,对结果进行汇总和排序等操作(如果需要的话),然后将最终的结果返回给客户端。
-
客户端接收结果:客户端通过MongoDB的驱动程序接收到Router返回的结果,完成一次数据读写操作。
需要注意的是,MongoDB分片集群中的Router、Config Server和Shard之间的通信是通过MongoDB的内部协议进行的,而客户端与Router之间的通信则是通过MongoDB的驱动程序和标准的MongoDB协议进行的。此外,为了保证数据的一致性和可用性,MongoDB分片集群还提供了复制集(Replica Set)和自动故障切换等机制。
总结来说,主从复制模式由于其存在的问题已经被MongoDB官方淘汰;副本集模式适合对数据可用性有较高要求的生产环境;而分片模式则适合处理大规模数据,提高系统的整体性能和可扩展性。在实际应用中,需要根据具体的需求和场景来选择合适的集群架构模式。文章来源:https://www.toymoban.com/news/detail-830858.html
四、总结
本文详细介绍了MongoDB的技术架构,包括数据存储层、数据模型层、查询语言层、索引层、复制和分片层、事务层、安全性和认证层以及客户端驱动层。MongoDB的技术架构为其提供了高性能、可扩展性和灵活性,使其成为现代应用程序的理想数据存储解决方案。通过深入了解MongoDB的技术架构,开发者可以更好地利用MongoDB的优势,构建出高效、可靠的应用程序。文章来源地址https://www.toymoban.com/news/detail-830858.html
到了这里,关于MongoDB技术架构详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!











