前言
这一章节袁庭新带领大家学习Elastic Stack的核心产品。首先,我们将对Elastic Stack的核心产品进行介绍;然后,带领大家去安装Elasticsearch-Head插件。

一. ELK简介
1.Elastic Stack产品概述
Elastic Stack核心产品包括Elasticsearch、Kibana、Beats和Logstash(也称为ELK)等等。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。

2.Elastic Stack产品介绍
2.1 Kibana介绍
Kibana是一个免费且开放的用户界面,能够让您对Elasticsearch数据进行可视化,并让您在Elastic Stack中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。
2.2 Elasticsearch介绍
Elasticsearch是一个分布式、RESTful风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为Elastic Stack的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
2.3 Logstash介绍
Logstash是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
2.4 Beats介绍
Beats是一个免费且开放的平台,集合了多种单一用途数据采集器(轻量型数据采集器)。它们从成百上千或成千上万台机器和系统向Logstash或Elasticsearch发送数据。
ELK内部实际就是个管道结构,数据从Logstash到Elasticsearch再到Kibana做可视化展示。这三个组件各自也可以单独使用,比如Logstash不仅可以将数据输出到Elasticsearch,也可以输出到数据库、缓存中等。
二. 安装Elasticsearch-Head插件
1.elasticsearch-head简介
elasticsearch-head是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。你可以通过插件把它集成到Elasticsearch(首选方式)也可以安装成一个独立webapp。
elasticsearch-head主要有三个方面的操作:
- 显示集群的拓扑,并且能够执行索引和节点级别操作。
- 搜索接口能够查询集群中原始JSON或表格格式的检索数据。
- 能够快速访问并显示集群的状态。
2.elasticsearch-head安装
elasticsearch-head的安装基于谷歌浏览器进行介绍。
1.通过https://fifiles.cnblogs.com/fifiles/sanduzxcvbnm/elasticsearch-head.7z网址下载elasticsearch-head.7z压缩包。
2.将elasticsearch-head.7z解压到任意一个没有中文没有空格的目录下。
3.在谷歌浏览器中点击【扩展程序】-【加载已解压的压缩程序】选项,找到elasticsearch-head文件夹,点击打开即可进行安装。
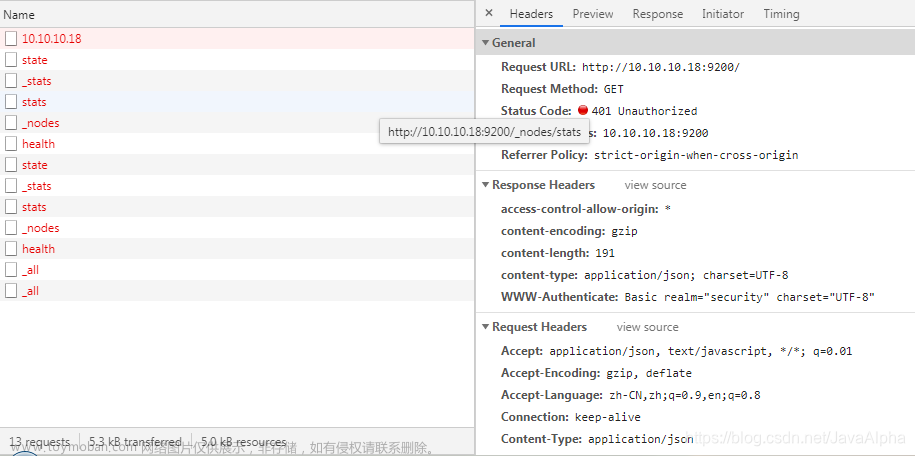
4.访问chrome-extension://ffmkiejjmecolpfloofpjologoblkegm/elasticsearch-head/index.html地址将看到以下窗口表示安装成功。

三. 安装IK分词器
Lucene的IK分词器早在2012年已经没有维护了,现在我们要使用的是在其基础上维护升级的版本,并且被开发为Elasticsearch的集成插件了,与Elasticsearch一起维护升级,版本也保持一致。
IK分词器下载地址:Releases · medcl/elasticsearch-analysis-ik · GitHub。
1.IK分词器安装
1.访问Release v6.2.4 · medcl/elasticsearch-analysis-ik · GitHub地址下载IK分词器zip安装包。
2.将下载的elasticsearch-analysis-ik-6.2.4.zip的压缩包解压到elasticsearch-6.2.4/plugins/目录下,并将解压后的目录重命名成analysis-ik。

3.重新启动Elasticsearch服务即可加载IK分词器,然后再重启Kibana服务。
2.IK分词器使用
我们先不管语法的含义,先测进行功能的测试,检测IK分词器是否能正常运行。
2.1 ik_max_word和ik_smart有什么区别?
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌”,会穷尽各种可能的组合,适合词条(Term)查询。
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、国歌”,适合词组(Phrase)查询。
2.2 IK分词器测试案例
1.将analyzer分词器设置为ik_max_word进行测试。
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}2.运行得到以下结果。
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}3.将analyzer分词器设置为ik_smart进行测试。
GET /_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}4.运行得到以下结果。
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}四. 结语
我们一块儿回顾下本章节学习的主要内容,首先我们对Elasticsearch、Kibana、Beats和Logstash等产品做了简单介绍。然后,基于谷歌浏览器安装了Elasticsearch-Head插件。并启动Elasticsearch-Head插件访问Elasticsearch。
今天的内容就分享到这里吧。关注「袁庭新」,干货天天都不断!文章来源:https://www.toymoban.com/news/detail-830902.html
 文章来源地址https://www.toymoban.com/news/detail-830902.html
文章来源地址https://www.toymoban.com/news/detail-830902.html
到了这里,关于袁庭新ES系列06节 | 安装Elasticsearch-Head的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![Elasticsearch安装分词插件[ES系列] - 第499篇](https://imgs.yssmx.com/Uploads/2024/02/785194-1.jpeg)




