参考:https://www.xjx100.cn/news/1726910.html?action=onClick
Milvus 基于FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求。通常,建议用户使用 Kubernetes 部署 Milvus,以获得最佳可用性和弹性。
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。

整个系统分为四个层次:
- 接入层(Access Layer):系统的门面,由一组无状态 proxy 组成。对外提供用户连接的 endpoint,负责验证客户端请求并合并返回结果。
- 协调服务(Coordinator Service):系统的大脑,负责分配任务给执行节点。协调服务共有四种角色,分别为 root coord、data coord、query coord 和 index coord。
- 执行节点(Worker Node):系统的四肢,负责完成协调服务下发的指令和 proxy 发起的数据操作语言(DML)命令。执行节点分为三种角色,分别为 data node、query node 和 index node。
- 存储服务 (Storage): 系统的骨骼,负责 Milvus 数据的持久化,分为元数据存储(meta store)、消息存储(log broker)和对象存储(object storage)三个部分。

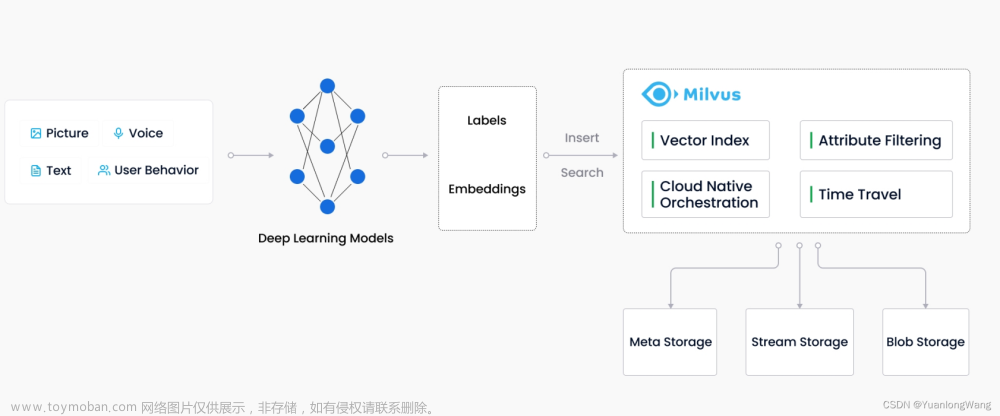
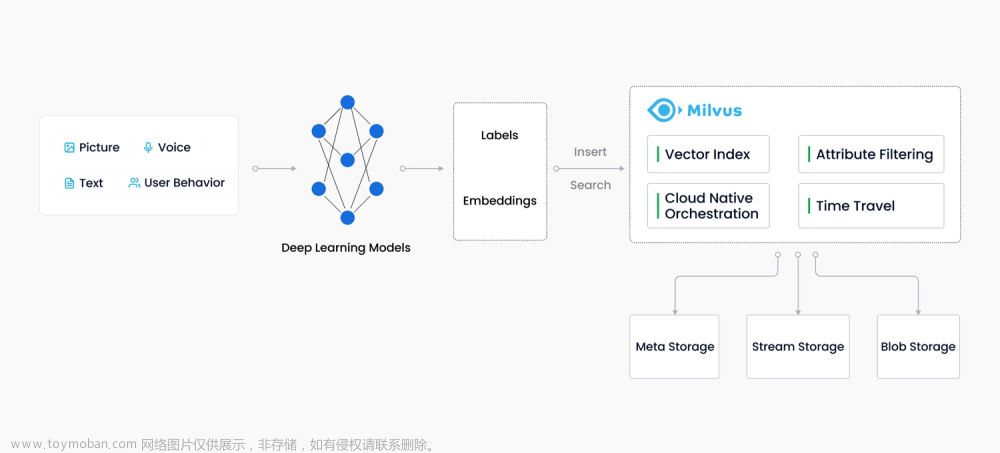
Milvus 向量数据库能够帮助用户轻松应对海量非结构化数据(图片/视频/语音/文本)检索。单节点 Milvus 可以在秒内完成十亿级的向量搜索,分布式架构亦能满足用户的水平扩展需求。
milvus特点总结如下:
- 高性能:性能高超,可对海量数据集进行向量相似度检索。
- 高可用、高可靠:Milvus 支持在云上扩展,其容灾能力能够保证服务高可用。
- 混合查询:Milvus 支持在向量相似度检索过程中进行标量字段过滤,实现混合查询。
- 开发者友好:支持多语言、多工具的 Milvus 生态系统。
2.2 Milvus关键概念
非结构化数据:非结构化数据指的是数据结构不规则,没有统一的预定义数据模型,不方便用数据库二维逻辑表来表现的数据。非结构化数据包括图片、视频、音频、自然语言等,占所有数据总量的 80%。非结构化数据的处理可以通过各种人工智能(AI)或机器学习(ML)模型转化为向量数据后进行处理。
特征向量:向量又称为embedding vector,是指由 embedding 技术从离散变量(如图片、视频、音频、自然语言等各种非结构化数据)转变而来的连续向量。在数学表示上,向量是一个由浮点数或者二值型数据组成的 n 维数组。
通过现代的向量转化技术,比如各种人工智能(AI)或者机器学习(ML)模型,可以将非结构化数据抽象为 n 维特征向量空间的向量。这样就可以采用最近邻算法(ANN)计算非结构化数据之间的相似度。
向量相似度检索:相似度检索是指将目标对象与数据库中数据进行比对,并召回最相似的结果。同理,向量相似度检索返回的是最相似的向量数据。近似最近邻搜索(ANN)算法能够计算向量之间的距离,从而提升向量相似度检索的速度。如果两条向量十分相似,这就意味着他们所代表的源数据也十分相似。
Collection-集合:包含一组entity,可以等价于关系型数据库系统(RDBMS)中的表。
Entity-实体:包含一组 field。field 与实际对象相对应。field 可以是代表对象属性的结构化数据,也可以是代表对象特征的向量。primary key 是用于指代一个 entity 的唯一值。注意:你可以自定义primary key,否则 Milvus 将会自动生成primary key。目前Milvus 不支持primary key去重,因此有可能在一个collection内出现primary key相同的entity。
Field-字段:Entity 的组成部分。Field可以是结构化数据,例如数字和字符串,也可以是向量。注意:Milvus2.0现已支持标量字段过滤。并且,Milvus 2.0在一个集合中只支持一个主键字段。

Partition-分区:分区是集合(Collection)的一个分区。Milvus 支持将收集数据划分为物理存储上的多个部分。这个过程称为分区,每个分区可以包含多个段。
Segment-段:Milvus 在数据插入时,通过合并数据自动创建的数据文件。一个collection可以包含多个segment。一个segment可以包含多个entity。在搜索中,Milvus会搜索每个segment,并返回合并后的结果。
Sharding-分片:Shard是指将数据写入操作分散到不同节点上,使 Milvus 能充分利用集群的并行计算能力进行写入。默认情况下,单个Collection包含 2 个分片(Shard)。目前 Milvus 采用基于主键哈希的分片方式,未来将支持随机分片、自定义分片等更加灵活的分片方式。注意: 分区的意义在于通过划定分区减少数据读取,而分片的意义在于多台机器上并行写入操作。
索引:索引基于原始数据构建,可以提高对 collection 数据搜索的速度。Milvus 支持多种索引类型。为提高查询性能,你可以为每个向量字段指定一种索引类型。目前,一个向量字段仅支持一种索引类型。切换索引类型时,Milvus 自动删除之前的索引。相似性搜索引擎的工作原理是将输入的对象与数据库中的对象进行比较,找出与输入最相似的对象。索引是有效组织数据的过程,极大地加速了对大型数据集的查询,在相似性搜索的实现中起着重要作用。对一个大规模向量数据集创建索引后,查询可以被路由到最有可能包含与输入查询相似的向量的集群或数据子集。在实践中,这意味着要牺牲一定程度的准确性来加快对真正的大规模向量数据集的查询。
PChannel:PChannel 表示物理通道。每个 PChannel 对应一个日志存储主题。默认情况下,将分配一组 256 个 PChannels 来存储记录 Milvus 集群启动时数据插入、删除和更新的日志。
VChannel:VChannel 表示逻辑通道(虚拟通道)。每个集合将分配一组 VChannels,用于记录数据的插入、删除和更新。VChannels 在逻辑上是分开的,但在物理上共享资源。
Binlog:binlog 是一个二进制日志,或者是一个更小的段单位,记录和处理 Milvus 向量数据库中数据的更新和更改。 一个段的数据保存在多个二进制日志中。 Milvus 中的 binlog 分为三种:InsertBinlog、DeleteBinlog 和 DDLBinlog。
日志代理(Log broker):日志代理是一个支持回放的发布订阅系统。它负责流数据持久化、可靠异步查询的执行、事件通知和查询结果的返回。当工作节点从系统崩溃中恢复时,它还确保增量数据的完整性。
日志订阅者:日志订阅方通过订阅日志序列来更新本地数据,并以只读副本的形式提供服务。
日志序列(Log sequence):日志序列记录了在 Milvus 中更改集合状态的所有操作。
正则化:正则化是指转换嵌入(向量)以使其范数等于1的过程。 如果使用内积 (IP) 来计算embeddings相似度,则必须对所有embeddings进行正则化。 正则化后,内积等于余弦相似度。
对象存储:负责存储日志的快照文件、标量/向量索引文件以及查询的中间处理结果。Milvus 采用 MinIO 作为对象存储,另外也支持部署于 AWS S3 和Azure Blob 这两大最广泛使用的低成本存储。但是,由于对象存储访问延迟较高,且需要按照查询计费,因此 Milvus 未来计划支持基于内存或 SSD 的缓存池,通过冷热分离的方式提升性能以降低成本。
消息存储:消息存储是一套支持回放的发布订阅系统,用于持久化流式写入的数据,以及可靠的异步执行查询、事件通知和结果返回。执行节点宕机恢复时,通过回放消息存储保证增量数据的完整性。
目前,分布式版Milvus依赖 Pulsar 作为消息存储,单机版Milvus依赖 RocksDB 作为消息存储。消息存储也可以替换为 Kafka、Pravega 等流式存储。
整个 Milvus 围绕日志为核心来设计,遵循日志即数据的准则,因此在 2.0 版本中没有维护物理上的表,而是通过日志持久化和日志快照来保证数据的可靠性。
日志系统作为系统的主干,承担了数据持久化和解耦的作用。通过日志的发布订阅机制,Milvus 将系统的读、写组件解耦。一个极致简化的模型如上图所示,整个系统主要由两个角色构成,分别是消息存储(log broker)(负责维护”日志序列“)与“日志订阅者”。其中的“日志序列”记录了所有改变库表状态的操作,“日志订阅者”通过订阅日志序列更新本地数据,以只读副本的方式提供服务。 发布订阅机制还为系统在变更数据捕获(CDC)和全面的分布式部署方面的可扩展性提供了空间。
单机版 Milvus包括三个组件:
- Milvus 负责提供系统的核心功能。
- etcd 是元数据引擎,用于管理 Milvus 内部组件的元数据访问和存储,例如:proxy、index node 等。
- MinIO 是存储引擎,负责维护 Milvus 的数据持久化。

2.3.2 分布式版 Milvus
分布式版 Milvus 由八个微服务组件和三个第三方依赖组成,每个微服务组件可使用 Kubernetes 独立部署。
微服务组件
- Root coord
- Proxy
- Query coord
- Query node
- Index coord
- Index node
- Data coord
- Data node
第三方依赖
- etcd 负责存储集群中各组件的元数据信息。
- MinIO 负责处理集群中大型文件的数据持久化,如索引文件和全二进制日志文件。
- Pulsar 负责管理近期更改操作的日志,输出流式日志及提供日志订阅服务。

索引方式:
- FLAT:准确率高, 适合数据量小,暴力求解相似。
- IVF-FLAT:量化操作, 准确率和速度的平衡
- IVF: inverted file 先对空间的点进行聚类,查询时先比较聚类中心距离,再找到最近的N个点。
- IVF-SQ8:量化操作,disk cpu GPU 友好
- SQ8:对向量做标量量化,浮点数表示转为int型表示,4字节->1字节。
- IVF-PQ:快速,但是准确率降低,把向量切分成m段,对每段进行聚类;查询时,查询向量分端后与聚类中心计算距离,各段相加后即为最终距离。使用对称距离(聚类中心之前的距离)不需要计算直接查表,但是误差回更大一些。
- HNSW:基于图的索引,高效搜索场景,构建多层的NSW。
- ANNOY:基于树的索引,高召回率
milvus目录结构:
│
├─conf //配置文件目录
│ server_config.yaml //配置文件 搜索引擎配置都在这里修改
│
├─db //数据库存储目录 你的索引与向量存储的位置
│
└─logs //日志存储目录
│
└─wal // 预写式日志相关配置

GitHub - milvus-io/milvus-sdk-java: Java SDK for Milvus.文章来源:https://www.toymoban.com/news/detail-831100.html
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.3.3</version>
</dependency>
https://github.com/milvus-io/milvus-sdk-java/tree/master/examples文章来源地址https://www.toymoban.com/news/detail-831100.html
到了这里,关于Milvus数据库介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!