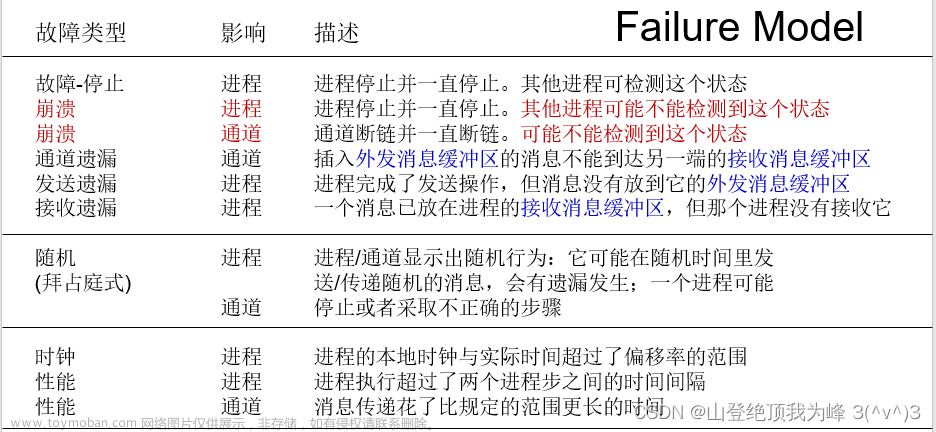
本文主要探讨rabbitmq集群镜像模式的高可用容错方案和容错能力的探讨。在出现单机故障时相关的容错方案。
更多关于分布式系统的架构思考请参考文档关于常见分布式组件高可用设计原理的理解和思考
1. broker启动加载逻辑
在rabbitmq中,只有broker进程,其余的组件或者角色都是通过broker衍生出来,因此broker的高可用和数据加载流程有必要理解和分析。
1.1 日志文件
RabbitMQ使用数据文件来存储队列、交换机和消息等信息。以下是一些常见的RabbitMQ数据文件:
- Queues(队列):每个队列都有一个对应的数据文件用于存储队列中的消息。这些文件通常保存在RabbitMQ服务器的磁盘上,以便在服务器重启后保留消息。
- Exchanges(交换机):交换机也有对应的数据文件,用于存储交换机的配置信息,包括交换机的名称、类型和绑定规则等。
- Message logs(消息日志):RabbitMQ记录每个传入/传出的消息以及与之相关的元数据信息,例如消息的交换机和队列等。这些消息日志通常以日志文件的形式存储在磁盘上。
- Cluster state(集群状态):如果使用RabbitMQ集群,每个节点都会维护一个集群状态文件,用于记录集群成员、队列分布和其他集群相关的信息。
- Configuration files(配置文件):RabbitMQ还使用配置文件来存储服务器的配置信息,例如监听的端口、虚拟主机、用户权限等。
这些数据文件通常存储在RabbitMQ服务器的指定目录中。在默认情况下,RabbitMQ使用的数据文件位于服务器的/var/lib/rabbitmq目录下。但是,可以通过配置文件指定不同的目录或自定义数据文件的存储位置。
1.2 broker启动流程
1.2.1 整体流程
RabbitMQ节点启动流程可以归纳为以下几个步骤:
- 启动Erlang虚拟机:RabbitMQ使用Erlang语言进行开发,所以首先需要启动Erlang虚拟机。Erlang虚拟机负责管理RabbitMQ的进程和资源。
- 加载RabbitMQ应用程序:一旦Erlang虚拟机启动,它将加载RabbitMQ的应用程序代码。该代码包括RabbitMQ的主要组件,如AMQP协议处理器、队列管理器、交换机管理器等。
- 初始化节点:在RabbitMQ节点启动时,它会执行一系列初始化步骤。这些步骤包括读取配置文件、创建必要的目录和文件、加载插件等。
- 启动AMQP协议处理器:RabbitMQ使用AMQP协议来进行消息传递。一旦节点初始化完成,它会启动AMQP协议处理器,以便处理传入和传出的AMQP请求。
- 启动队列和交换机管理器:RabbitMQ的队列管理器和交换机管理器负责管理消息队列和消息路由。这些组件在节点启动时会被启动,以便为客户端提供队列和交换机的管理功能。
- 启动其他插件和扩展:RabbitMQ还支持许多插件和扩展,如插件可以用于实现各种功能,如可视化管理界面、消息持久化、消息过滤等。这些插件和扩展会在节点启动时被加载和启动。
- 监听客户端连接:最后,RabbitMQ节点会开始监听传入的客户端连接。一旦客户端连接到节点,它们可以使用AMQP协议与节点进行交互,发送和接收消息。
这些步骤通常是自动完成的,用户只需要启动RabbitMQ节点,并确保配置正确,节点就可以正常工作。
1.2.2 数据恢复流程
rabbitmq节点异常恢复后的加载顺序如下
- 优先加载本地的数据文件获取集群的配置信息,并重新组建集群
- 如果本地的数据文件为空,则会读取集群的配置文件,并组建集群
镜像模式下,节点以Follower的身份启动
- 首先遍历 rabbit_queue 表,找到 需要在本节点进行做镜像的队列。
先查询出当前需要做镜像队列的队列的所有从节点,再把通过suggested_queue_nodes 函数找出队列建议在哪些节点上需要做镜像队列,再和当前节点对比,如果需要在当前节点需要做镜像队列,则进行镜像队列进程的初始化操作
suggested_queue_nodes 函数 是通过配置策略来进行运算的,参考:rabbit_mirror_queue_mode_exactly.erl
rabbit_mirror_queue_mode_nodes.erl rabbit_mirror_queue_mode_all.erl 这三个文件的 suggested_queue_nodes 函数
用python转换下,大概以下逻辑是遍历队列当前节点队列,并跟队列的Leader进行数据同步
need_mirror_queues = []
for q in rabbit_queue:
qSlaveNodeArr = []
for sqid in q.Spids:
if node(spid) != node():
continue
else:
qSlaveNodeArr.append(node(spid))
break
if node() in qSlaveNodeArr:
pass
else:
qSlaveNodeArr.append(node())
suggestedNodes = suggested_queue_nodes(qSlaveNodeArr)
if node() in suggestedNodes:
need_mirror_queues.append(q)
for q in need_mirror_queues:
start_mirror(q)
- 开启镜像队列进程
rabbit_mirror_queue_misc::add_mirror() -- >
rabbit_amqqueue_sup_sup:start_queue_process(MirrorNode, Q, slave) -->
rabbit_amqqueue_sub::start_link()
队列进程中加载了 rabbit_amqqueue_process 和 rabbit_mirror_queue_slave
- 往镜像队列进程发送初始化消息
rabbit_mirror_queue_slave:go(SPid, SyncMode)
-
删除消息队列名字为QName对应的目录下面所有的消息索引磁盘文件
-
实际调用 rabbit_variable_queue 进行队列 索引等存储初始化操作( 因为索引等文件都删除了,这一步实际内存中镜像队列进程中队列数据是空的,这一步可以参考队列主节点数据恢复过程 )
-
往队列主节点的进程PID发送 同步消息
这个是队列镜像队列进程起来后,由队列从节点进程往队列主节点进程发送这个消息,请参考rabbit_mirror_queue_slave::handle_go() 里的rabbit_mirror_queue_misc:maybe_auto_sync(Q1) -
队列主节点进程接收到 sync_mirrors 消息 (rabbit_amqqueue_process 下)
-
开启同步进程并且查找到当前队列所有从节点信息,并且往所有从队列从节点进程广播发送 sync_start 同步开始的消息
-
队列从节点进程接收到 sync_start 消息(在rabbit_mirror_queue_slave 里)
-
进行判断当前这个节点是否已经是最新的数据,因为有可能本来 队列需要 1主多人的情况下,又新加一个从节点进来,原来的从节点上的数据已经是和主节点上的数据保持一致了。那本来运行的从节点上是不需要进行数据同步的。
- 已经同步过返回:sync_deny
- 需要同步返回 :sync_ready
- 同步进程给需要同步的队列从节点进程发送 同步数据
队列主节点进程遍历当前所有消息同步发送给同步进程,再由同步进程发送给从节点进程
每次发送消息之前会发送一条 这是第几条数据. 这条消息存在队列从节点进程 #state{depth_delta} 字段中,当初始化同步近个队列的时候,这个值>0大于代表不需要同步
- 队列从节点处理同步进程同步过来的消息
当队列从节点接收到 sync_start 消息的时候 ,会进入一个死循环接收消息的状态。这个状态只会和 同步进程之间同步,和其他进程通信延迟。从进程初始化的时候 depth_delta = undefined,当然 depth_delta = 0 的时候,这个时候就不会进入接收数据的状态,会返回给同步进程不需要同步消息。在数据同步完的时候 ,从进程会把 depth_delta 设置成 0
rabbit_mirror_queue_slave::handle_cast({sync_start, Ref, Syncer},
数据处理逻辑大概是拿到消息后调用 rabbit_variable_queue::publish() 往队列进程中写消息
2. 队列高可用
2.1 选主逻辑
-
如果某个slave失效了,系统处理做些记录外几乎啥都不做:master依旧是master,客户端不需要采取任何行动,或者被通知slave失效。
-
如果master失效了,那么slave中的一个必须被选中为master。被选中作为新的master的slave通常是最老的那个,因为最老的slave与前任master之间的同步状态应该是最好的。然而,特殊情况下,如果存在没有任何一个slave与master完全同步的情况,那么前任master中未被同步的消息将会丢失。
2.1.1 从节点晋升策略
镜像队列主节点出现故障时,最老的从节点会被提升为新的主节点。如果新提升为主节点的这个副本与原有的主节点并未完成数据的同步,那么就会出现数据的丢失,而实际应用中,出现数据丢失可能会导致出现严重后果。
rabbitmq 提供了 ha-promote-on-shutdown,ha-promote-on-failure 两个参数让用户决策是保证队列的可用性,还是保证队列的一致性;两个参数分别控制正常关闭、异常故障情况下从节点是否提升为主节点,其可设置的值为 when-synced 和 always。
| ha-promote-on-shutdown/ha-promote-on-failure | 说明 |
|---|---|
| when-synced | 从节点与主节点完成数据同步,才会被提升为主节点 |
| always | 无论什么情况下从节点都将被提升为主节点 |
这里要注意的是ha-promote-on-failure设置为always,插拔网线模拟网络异常的两个测试场景:当网络恢复后,其中一个会重新变为mirror,具体是哪个变为mirror,受cluster_partition_handling处理策略的影响。
例如两台节点A,B组成集群,并且cluster_partition_handling设置为autoheal,队列的master位于节点A上,具有全量数据,mirror位于节点B上,并且还未完成消息的同步,此时出现网络异常,网络异常后两个节点交互决策:如果节点A节点成为赢家,此时B节点内部会重启,这样数据全部保留不会丢失;相反如果B节点成为赢家,A需要重启,那么由于ha-prromote-on-failure设置为always,B节点上的mirror提升为master,这样就出现了数据丢失。
2.1.2 主队列选择策略
RabbitMQ中的每个队列都有一个主队列。该节点称为队列主服务器。所有队列操作首先经过主队列,然后复制到镜像。这对于保证消息的FIFO排序是必要的。通过在策略中设置 queue-master-locator 键的方法可以定义主队列选择策略,这是常用的方法。
| queue-master-locator | 说明 |
|---|---|
| min-masters | 选择承载最小绑定主机数量的节点 |
| client-local | 选择客户机声明队列连接到的节点 |
| random | 随机选择一个节点 |
2.2 HA切换
如果leader节点宕机或者节点异常,会触发选举逻辑,选择新的leader队列。
3. 疑问和思考
3.1 如果一个broker宕机,运行在broker上的队列数据丢失,是否会自动做均衡?
不会。因为镜像队列所有节点理论上保持的数据相同,如果Leader节点宕机,会重新触发选举,选择新的节点成为Leader继续提供服务。文章来源:https://www.toymoban.com/news/detail-831293.html
3.2 如果一个broker宕机,重新加入集群后,数据同步逻辑是怎样的?
每当一个节点加入或者重新加入(例如从网络分区中恢复过来)镜像队列,之前保存的队列内容会被清空。文章来源地址https://www.toymoban.com/news/detail-831293.html
| ha-sync-mode | 说明 |
|---|---|
| manual | 这是默认模式。新队列镜像将不接收现有消息,它只接收新消息。一旦使用者耗尽了仅存在于主服务器上的消息,新的队列镜像将随着时间的推移成为主服务器的精确副本。如果主队列在所有未同步的消息耗尽之前失败,则这些消息将丢失。您可以手动完全同步队列,详情请参阅未同步的镜像部分。 |
| automatic | 当新镜像加入时,队列将自动同步。值得重申的是,队列同步是一个阻塞操作。如果队列很小,或者您在RabbitMQ节点和ha-sync-batch-size之间有一个快速的网络,那么这是一个很好的选择。 |
4. 参考文档
- RabbitMQ 启动过程
到了这里,关于RabbitMQ节点故障的容错方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!