import requests
import json
import base64, urllib
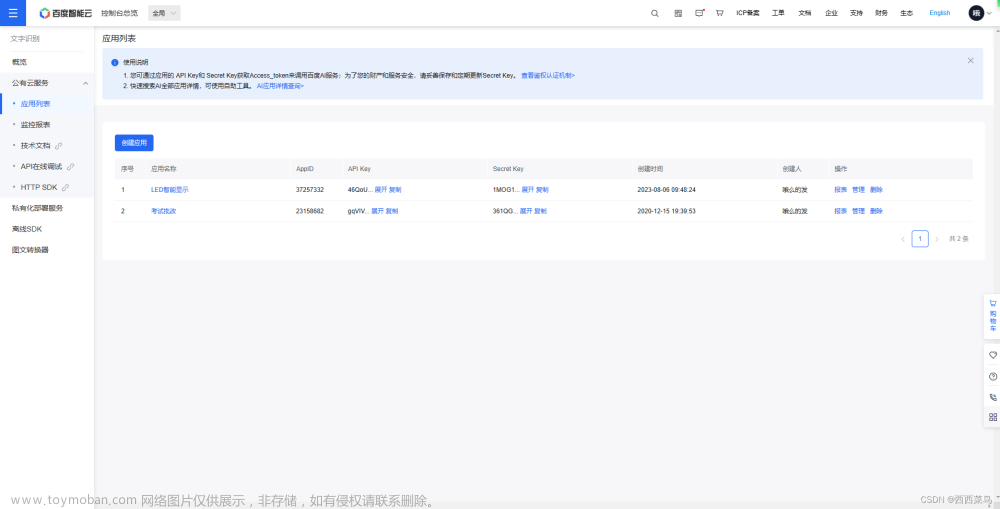
API_KEY = 'xx'
SECRECT_KEY = 'xx'
pic_name = "img.jpg"
def ocr_baidu():
"""invoke token"""
url = 'https://aip.baidubce.com/oauth/2.0/token'
body = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRECT_KEY
}
req = requests.post(url=url, data=body)
token = json.loads(req.content)['access_token']
"""use token call BAIDU ocr api"""
ocr_url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token=%s' % token
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
body = base64.b64encode(open(pic_name, "rb").read())
data = urllib.parse.urlencode({'image': body})
r = requests.post(url=ocr_url, headers=headers, data=data)
res_words = json.loads(r.content)['words_result']
return res_words文章来源:https://www.toymoban.com/news/detail-831355.html
if __name__ == '__main__':
for i in ocr_baidu():
print(i['words'])文章来源地址https://www.toymoban.com/news/detail-831355.html
到了这里,关于百度OCR api调用代码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[C#]调用tesseact-ocr的traineddata模型进行ocr文字识别](https://imgs.yssmx.com/Uploads/2024/02/783178-1.jpeg)