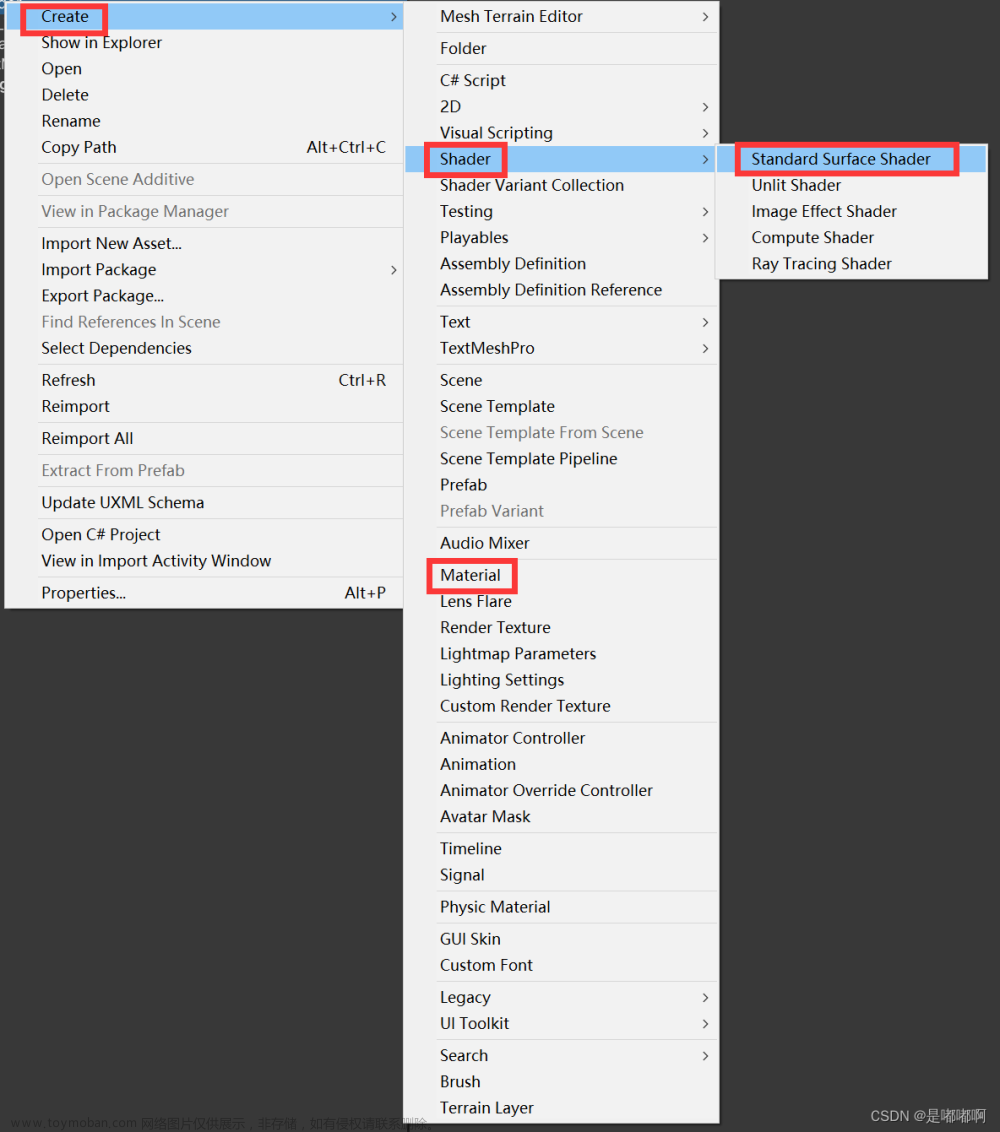
catalyst引擎
作用:将SparkSql转换成spark rdd任务提交进行计算
- 解析器
- 将sparksql代码解析成语法树(未解析的逻辑查询计划)
- 分析器
- 将语法树解析成解析后的逻辑查询计划
- 对逻辑查询计划进行属性和关系关联检验
- 优化器
- 将解析后的逻辑查询计划进行优化, 得到优化后的逻辑查询计划
- 谓词下推(调整执行顺序)和列值裁剪(过滤列)
- 执行器
- 将优化后的逻辑查询计划转换成物理查询计划
- 转换成RDD任务进行执行
kafka使用
1,消息队列
离线计算
通常称为批处理,表示哪些离线批量,延时较高的静态数据处理过程
实时计算
用户访问信息,用户访问的数据直接背传递给spark计算
概念
消息是在两台计算机传送的数据单位
临时存储传递消息的容器->kafka是非关系型数据库之一,也是消息队列之一
实时计算时需要将流数据(消息)先存储在消息队列中,否则容易产生数据积压导致数据丢失问题
应用场景:解耦,异步,消峰
解耦:接触应用之间的关联关系
异步:应用之间不会同时执行,应用B不会等待应用A执行完成后再产生信息
消峰:某个节点数据量突然增多,导致处理不过来,供大于求
2,模式
点对点模式:
一对一关系,私聊
角色:发送者(生产者),接收者(消费者)
- 每个消息只有一个接收者(Consumer),一旦被消费,消息就不再存在于消息队列中。
- 发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息。
- 接收者在成功接收消息之后需要向队列应答成功,以便消息队列删除当前接收的消息。
发布与订阅:
一对多关系,群聊。一个消息对应多个消费者
角色:主题,发布者,订阅者
- 每个消息可以有多个订阅者。
- 发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。
- 为了消费消息,订阅者需要提前订阅该角色主题,并保持在线运行。
3,分类
ActiveMQ:
TabbitMQ:应用程序对消息队列要求不高,数据临时缓存
TocketMQ:在线业务,对延迟和稳定性要求高
kafka:流计算、实时计算,处理海量的消息
选择:
- 如果消息队列不是将要构建系统的重点,对消息队列功能和性能没有很高的要求,只需要一个快速上手易于维护的消息队列,建议使用 RabbitMQ。
- 如果系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,需要低延迟和高稳定性,建议使用 RocketMQ。
- 如果需要处理海量的消息,像收集日志、监控信息或是埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合的消息队列。
kafka消息队列
特点:
可靠性:分布式,分区,赋值和容错等
可扩展性:kafka消息传递系统秦颂缩放无需停机,可以添加新的服务器资源,不需要对服务器关闭重启,可以自动识别添加
耐用性:分布式提交日志,消息会尽可能快速的保存再磁盘上,因此它是持久的文章来源:https://www.toymoban.com/news/detail-831471.html
高性能:kafka对于发布和订阅都具有高吞吐量,同时存储了许多tb级消息,也有稳定的性能,kafka非常快并且保证零停机和零数据丢失文章来源地址https://www.toymoban.com/news/detail-831471.html
1,概念术语
- Producer 生产者
- 也就是发送消息的一方。生产者负责创建消息,然后将其投递到Kafka
- Consumer 消费者
- 也就是接收消息的一方。消费者连接到Kafka上并接收消息,进而进行相应的业务逻辑处理。
- Consumer Group(CG)消费者组
- 由多个 consumer 组成。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- broker 服务代理节点(中间人)
- kafka集群运行后,每台服务器上的kafka称为一个broker节点
- 处理消费者和生成者的请求
- 生产者需要保存数据到kafka,就需要请求broker
- 消费者需要从kafka中获取数据,也需要请求broker
- 多个broker会选取产生一个控制器,类似zk中的leader角色
- 管理broker,监控broker的变化
- 参与分区副本的领导者选举
- 处理消费者和生成者的请求
- 由zk从broker中选举出控制器
- 本质哪台服务器先启动了kafka,生成了broker节点,该节点就作为控制器
- Topic 主题
- kakfa是对消息数据的处理
- 消息数据会有不同的分类
- 使用主题对消息数据进行分类,然后分别存储
- 主题创建成功后,会将主题信息写入zk中,所有的broker就可以从zk中获取有哪些主题
- 生产者写入数据时可以指定写入的主题,人为对数据按照主题分类
- 消费者读取数据时也可以指定主题,从对应的主题下获取数据
- Partition 分区(分片)
- 分区是kafka存储数据的最小单元,消息数据最终是存储在分区上的
- 一个主题在存储时可以指定多个分区
- 当有多个分区时,分区被分配到不同broker上
- 分区所存储的数据是在系统的磁盘上进行存储。每个分区会创建不同目录,然后将数据写入该目录下的文件中
- 文件中存储的数据是有有效期的,默认的有效期是168小
到了这里,关于kafka的基本使用--学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!