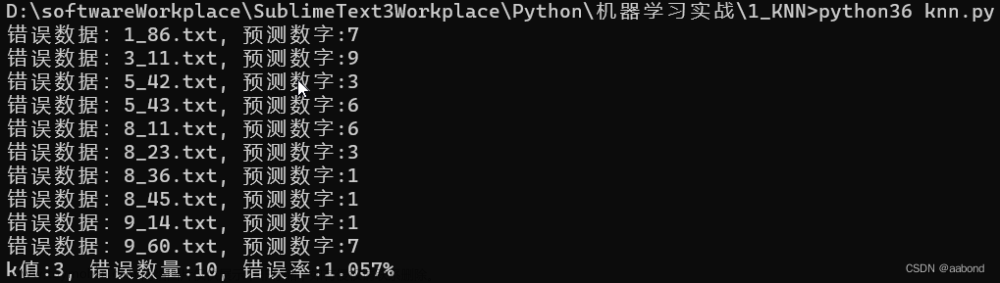
距离度量
欧氏距离(Euclidean distance)

欧几里得度量(Euclidean Metric)(也称欧氏距离)是一个通常采用的距离定义,指在𝑚维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
曼哈顿距离(Manhattan distance)

想象你在城市道路里,要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直
线距离吗?显然不是,除非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的来源, 曼哈顿距离也称为城市街区距离(City Block distance)
切比雪夫距离(Chebyshev distance)

二个点之间的距离定义是其各坐标数值差绝对值的最大值。国际象棋棋盘上二个位置间的切比雪夫距离是指王要从一个位子移至另一个位子需要走的步数。由于王可以往斜前或斜后方向移动一格,因此可以较有效率的到达目的的格子。上图是棋盘上所有位置距f6位置的切比雪夫距离。
闵可夫斯基距离(Minkowski distance)

𝑝取1或2时的闵氏距离是最为常用的
𝑝 = 2即为欧氏距离,
𝑝 = 1时则为曼哈顿距离。
当𝑝取无穷时的极限情况下,可以得到切比雪夫距离
汉明距离(Hamming distance)

汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念,它表示两个(相同长度)字对应位不同的数量,我们以表示两个字之间的汉明距离。对两个字符串进行异或运算,并统计结果为1的个数,那么这个数就是汉明距离。
余弦相似度
两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。
假定𝐴和𝐵是两个𝑛维向量,𝐴是 𝐴1, 𝐴2, … , 𝐴𝑛 ,𝐵是𝐵1,𝐵2, … , 𝐵𝑛 ,则𝐴和𝐵的夹角的余弦等于:

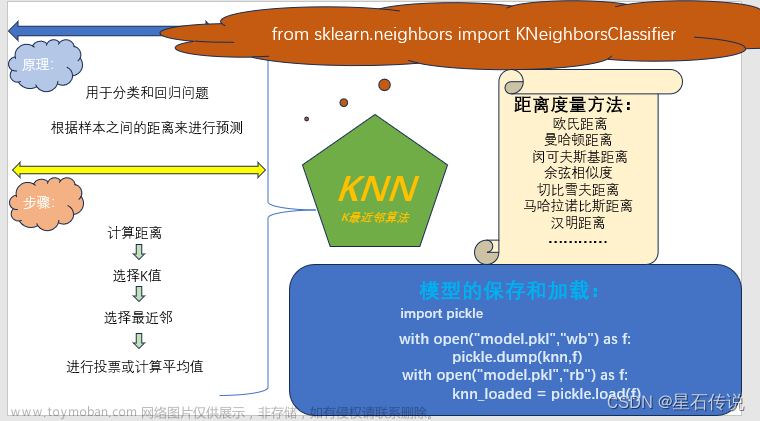
KNN算法
𝑘近邻法(k-Nearest Neighbor,kNN)是一种比较成熟也是最简单的机器学习算法,可以用于基本的分类与回归方法。
算法的主要思路
如果一个样本在特征空间中与𝑘个实例最为相似(即特征空间中最邻近),那么这𝑘个实例中大多数属于哪个类别,则该样本也属于这个类别。
对于分类问题:
对新的样本,根据其𝑘个最近邻的训练样本的类别,通过多数表决等方式进行预测。
对于回归问题:
对新的样本,根据其𝑘个最近邻的训练样本标签值的均值作为预测值
𝑘近邻法的三要素
• 𝑘值选择。
• 距离度量。
• 决策规则。
算法流程
1.计算测试对象到训练集中每个对象的距离
2.按照距离的远近排序
3.选取与当前测试对象最近的k的训练对象,作为该测试对象的邻居
4.统计这k个邻居的类别频次
5.k个邻居里频次最高的类别,即为测试对象的类
 以上图中绿点位置的分类问题为例,图中有正方形和三角形两类,K=3即选取距离绿点最近的三个对象,这三个对象中三角形的类别较多因此将绿点位置归为三角形类,而当K=5时选取距离绿点位置最近的五个对象,此时正方形的数量较多,则此时绿点为正方形类
以上图中绿点位置的分类问题为例,图中有正方形和三角形两类,K=3即选取距离绿点最近的三个对象,这三个对象中三角形的类别较多因此将绿点位置归为三角形类,而当K=5时选取距离绿点位置最近的五个对象,此时正方形的数量较多,则此时绿点为正方形类
KD树划分
KD树(K-Dimension Tree),,也可称之为K维树,可以用更高的效率来对空间进行划分,并且其结构非常适合寻找最近邻居和碰撞检测。
假设有 6 个二维数据点,构建KD树的过程:𝐷 = (2,3), (5,7), (9,6), (4,5), (6,4), (7,2) 。
①从𝑥轴开始划分,根据𝑥轴的取值2,5,9,4,6,7得到中位数为6 ,因此切分线为:𝑥 = 6 。
②可以根据𝑥轴和𝑦轴上数据的方差,选择方差最大的那个轴作为第一轮划分轴。
左子空间(记做 𝐷1)包含点 (2,3),(4,5),(5,7),切分轴轮转,从𝑦轴开始划分,切分线为𝑦 = 5
右子空间(记做 𝐷2 )包含点 (9,6),(7,2),切分轴轮转,从𝑦轴开始划分,切分线为:𝑦 = 6 。
③𝐷1的左子空间(记做 𝐷3)包含点(2,3),切分轴轮转,从x 轴开始划分,切分线为:𝑥 = 2。
其左子空间记做 𝐷7 ,右子空间记做 𝐷8 。由于 𝐷7,𝐷8都不包含任何点,因此对它们不再继续拆分。
𝐷1 的右子空间(记做 𝐷4 )包含点(5,7),切分轴轮转,从x 轴开始划分,切分线为:𝑥 = 5。
其左子空间记做 𝐷9,右子空间记做 𝐷10 。由于𝐷9,𝐷10都不包含任何点,因此对它们不再继续拆分。
④𝐷2的左子空间(记做 𝐷5 )包含点(7,2),切分轴轮转,从x 轴开始划分,切分线为:𝑥 = 7。
其左子空间记做 𝐷11,右子空间记做 𝐷12 。由于𝐷11,𝐷12 都不包含任何点,因此对它们不再继续拆分。
𝐷2的右子空间(记做 𝐷6)不包含任何点,停止继续拆分。

 文章来源:https://www.toymoban.com/news/detail-831554.html
文章来源:https://www.toymoban.com/news/detail-831554.html
KD树搜索
1.首先要找到该目标点的叶子节点,然后以目标点为圆心,目标点到叶子节点的距离为半径,建立一个超球体,我们要找寻的最近邻点一定是在该球体内部。
搜索(4,4)的最近邻时。首先从根节点(6,4)出发,将当前最近邻设为(6,4),对该KD树作深度优先遍历。以(4,4)为圆心,其到(6,4)的距离为半径画圆(多维空间为超球面),可以看出(7,2)右侧的区域与该圆不相交,所以(7,2)的右子树全部忽略。
2.返回叶子结点的父节点,检查另一个子结点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有的话就更新最近邻。
接着走到(6,4)左子树根节点(4,5),与原最近邻对比距离后,更新当前最近邻为(4,5)。以(4,4)为圆心,其到(4,5)的距离为半径画圆,发现(6,4)右侧的区域与该圆不相交,忽略该侧所有节点,这样(6,4)的整个右子树被标记为已忽略
3.如果不相交直接返回父节点,在另一个子树继续搜索最近邻。
4.当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。遍历完(4,5)的左右叶子节点,发现与当前最优距离相等,不更新最近邻。所以(4,4)的最近邻为(4,5)。文章来源地址https://www.toymoban.com/news/detail-831554.html
到了这里,关于【机器学习笔记】7 KNN算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!