前言
性能调优(上)线上问题排查工具汇总
【Jvm】性能调优(上)线上问题排查工具汇总
JVM调优(中)Java中不得不了解的OOM Error
【Jvm】性能调优(中)Java中不得不了解的OOM Error
一.JVM参数
1.参数分类
- 标准参数(-):所有的JVM实现都必须实现该功能且向后兼容
查看标准参数方法: java -help
-
非标准参数(-X):
默认Jvm实现该功能,但是不保证所有jvm实现都满足,且不保证向后兼容
查看非标准参数方法: java -X
-
非稳定参数(-XX):
各个jvm实现会有所不同,将来可能会随时弃用,需慎重使用;
2.非稳定参数(-XX)说明
查看非稳定参数方法: java -XX:+PrintFlagsInitial
语法
Boolean类型格式:
-XX:[±]<option>:表示启用或者禁用name属性
-XX:+<option> 启用选项,如:-XX:+PrintGCDetails
-XX:-<option> 不启用选项,如:-XX:-PrintGCDetails
非Boolean类型格式:
-XX:<name>=<value>设置name属性的值是value
-XX:<name>=<number> 设置name属性的值是value数字类型值,可跟单位,如-XX:NewSize=2m
-XX:<name>=<string> 设置name属性的值是value字符串值,如-XX:HeapDumpPath=./dump.core
非稳定参数主要分3类
行为参数(Behavioral Options):用于改变jvm的一些基础行为,如
-XX:-UseSerialGC 启用串行GC
-XX:-UseParallelGC 启用并行GC
-XX:-UseConcMarkSweepGC 启用CMS,对老年代采用并发标记交换算法进行GC
性能调优(Performance Tuning):用于jvm的性能调优,如
-XX:MaxNewSize=size 年轻内存的最大值
-XX:NewRatio=2 年轻代内存容量与老年代内存容量的比例
-XX:ThreadStackSize=512 设置线程栈大小,若为0则使用系统默认值
调试参数(Debugging Options):一般用于打开跟踪、打印、输出等jvm参数,用于显示jvm更加详细的信息,如
-XX:-PrintGCDetails 每次GC时打印详细信息
-XX:-PrintGCTimeStamps 打印每次GC的时间戳
-XX:-HeapDumpOnOutOfMemoryError 当首次遭遇OOM时导出此时堆中相关信息
-XX:HeapDumpPath=./java_pid<pid>.hprof 指定导出堆信息时的路径或文件名
3.查询JVM默认参数及运行时生效参数
-
java -XX:+PrintFlagsInitial: 输出JVM参数的默认值 -
java -XX:+PrintFlagsFinal -version: 输出运行程序时生效的值 -
java -XX:+PrintCommandLineFlags -version: 查询当前使用的 JVM命令,即被用户修改过的参数值

第1列:参数数据类型
第2列:参数名称
第3列:”=”表示第四列是参数的默认值,如果是":=" 表明了参数被用户或者JVM赋值了(重点关注)
第4列:参数值
第5列:参数的类别
4.常用参数
#初始堆大小,等于-XX:InitialHeapSize,默认为物理内存的1/64(<1GB)。如堆空间初始化大小为6m,可写为:-Xms6291456 或 -Xms6144k 或 -Xms6m
#默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制
#空闲最小堆占比通过-XX:MinHeapFreeRatio调整,默认为40,计算公式为:堆空闲占比=(当前空闲堆大小/当前堆总大小)*100,在每次GC之后,如果堆空闲占比< 空闲最小堆占比,则需要进行堆扩容
#最好将-Xms和-Xmx设为相同值,避免每次GC完成后JVM重新分配内存
-Xms
#最大堆大小。等于-XX:MaxHeapSize,,默认为物理内存的1/4,设如设置堆空间的最大值为80m,可写为:-Xmx83886080 或 -Xmx81920k 或 -Xmx80m
#默认空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制,建议不要超过系统总可用内存的1/2
#空闲最大占比通过-XX:MaxHeapFreeRatio调整,默认为70,计算公式为堆空闲占比=(当前空闲堆大小/当前堆总大小)*100,在每次GC之后,如果堆空闲占比< 空闲最大堆占比,则需要进行堆缩容
-Xmx
#年轻代初始化大小,等同(-Xns)
-XX:NewSize
#年轻代的最大值,等同(-Xmn)(eden+ 2 survivor space)。如设置256m大小的年轻代:-Xmn256m 或 -Xmn262144k 或-Xmn268435456
#. 增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8
-XX:MaxNewSize
#设置年轻代(包括Eden和两个Survivor区)和老年代的比例。默认值是2。表示年轻代与年老代比值为1:2,年轻代占整个年轻代年老代和的1/3
#Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。
-XX:NewRatio
#设置Eden区与与两个Survivor区的内存占比,默认为8,即8:1:1,即Eden=8,Survivor From=1,Survivor To=1。一个Survivor区占整个年轻代的2/10
-XX:SurvivorRatio=ratio
#对象晋升到老年代的年龄阈值,默认为15,如果设为0,则年轻代对象不经过Survivor区,直接进入老年代. 对于老年代比较多的应用,可以提高效率
#如果设为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象在年轻代的存活时间,增加在年轻代即被回收的概率
#该参数只有在串行GC时才有效.
-XX:MaxTenuringThreshold=threshold
#大对象直接晋升老年代的阈值,默认0,单位只能使用byte,如3m,只能写为3145728
#年轻代采用Parallel Scavenge GC时无效 另一种直接在老年代分配的情况是大数组对象,且数组中无外部引用对象.
-XX:PretenureSizeThreshold=size
#大对象直接晋升老年代的阈值,默认0,单位只能使用byte,如3m,只能写为3145728
-XX:PretenureSizeThreshold=size
#设置线程的栈大小,可跟单位,如-Xss2m
# JDK5.0后默认1M(之前默认为256K).根据的线程所需内存大小进行调整
#在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成, 经验值在3000~5000左右
#一般小的应用, 如果栈不是很深 应该是128k够用的,大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。
-Xss
#设置永久代(perm gen)的初始大小,默认为内存的1/64(JDK1.7方法区)
-XX:PermSize=size
#设置永久代的最大值,默认为内存的1/4(JDK1.7方法区)
-XX:MaxPermSize=size
#设置元空间的大小(JDK1.8元空间)
-XX:MetaspaceSize=size
#设置元空间的最大值(JDK1.8元空间)
-XX:MaxMetaspaceSize=size
#限制GC的运行时间。如果GC耗时过长,就抛OOM,默认true,表启用
#GC Overhead limit exceeded原因:通过统计GC时间来预测是否要OOM了,当超过98%的时间用来做GC并且回收了不到2%的堆内存,就会抛出该错误(提前预知,没啥用,该OOM还是会OOM,建议关闭)
-XX:+UseGCOverheadLimit
#Full GC时是否先YGC,默认false,表关闭
-XX:+CollectGen0First
5.GC日志相关参数
#打印GC基本信息
-XX:+PrintGC:
#输出形式: [GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
#打印gc详细信息
-XX:+PrintGCDetails
#输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
#GC时,打印进程启动到现在经历的时间
-XX:+PrintGCTimeStamps
#输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
#输出GC的时间戳
-XX:+PrintGCDateStamps
#输出形式:2013-05-04T21:53:59.234+0800: [GC 98328K->93620K(130112K), 0.0082960 secs]
#GC时,打印应用被暂停时间
-XX:+PrintGCApplicationStoppedTime
#输出形式:Total time for which application threads were stopped: 0.0468229 seconds
#GC时,打印应用执行时间
-XX:+PrintGCApplicationConcurrentTime
#输出形式:Application time: 0.5291524 seconds
#打印每次GC前后的详细堆栈信息
-XX:+PrintHeapAtGC
#将GC日志输出到指定文件(默认打印到控制台),默认为应用启动路径的相对路径下,可使用绝对路径
-Xloggc:../logs/gc.log
#Java 9及更高版本
#日志文件的输出路径,如-Xlog:gc*:file=/opt/tmp/myapp-gc.log
-Xlog:gc*:file=<gc-log-file-path>
6.发生OOM时Dump堆内存快照相关参数
#如果出现了OutOfMemoryError异常,就把堆内信息Dump出来
-XX:+HeapDumpOnOutOfMemoryError
#保存Dump文件的路径,如果不指定,默认为当前启动JVM的目录,默认文件名:java_<pid>_<date>_<time>_heapDump.hprof
-XX:HeapDumpPath=/tmp/heapdump.hprof
#当出现OOM时,指定某个脚本来完成一些动作,比如邮件通知、自动重启等
-XX:OnOutOfMemoryError="sh ~/restart.sh"
7.收集器参数
-XX:-UseSerialGC 启用串行GC,即采用Serial+Serial Old组合GC。串行GC最适合小而简单的应用,不需要垃圾回收的特定功能。
-XX:+UseParNewGC: 使用ParNew+Serial Old收集器组合
-XX:-UseParallelGC:年轻代启用并行GC,年老代使用串行GC,,即采用Parallel Scavenge+Serial Old组合GC(-Server模式下的默认组合)
-XX:+UseParallelOldGC: 老年代启用并行GC(JDK1.6),即使用Parallel Scavenge +Parallel Old组合收集器
-XX:+UseConcMarkSweepGC: 使用ParNew+CMS+Serial Old组合并发收集,优先使用ParNew+CMS,当用户线程内存不足时,采用备用方案Serial Old收集。
-XX:+UseG1GC: 启用G1收集器。适用于多核和大内存服务器。G1收集器很大概率满足GC的停顿时间要求,同时保持一个很好的吞吐量。G1垃圾收集器适合那些具有超大堆空间(6GB左右或更多)且对GC延迟需求很高(低于0.5秒的稳定且可预测的暂停时间)的应用。
-XX:+UseZGC: 在JDK 11当加入,是一款低停顿高并发,支撑TB级别内存的收集器。
ZGC(Z Garbage Collector) 是一款性能比 G1 更加优秀的垃圾收集器。ZGC 第一次出现是在 JDK 11 中以实验性的特性引入,这也是 JDK 11 中最大的亮点。在 JDK 15 中 ZGC 不再是实验功能,可以正式投入生产使用了,使用 –XX:+UseZGC 可以启用 ZGC。
收集器相关配套参数,看这两篇文章即可
- 常见性能性能参数
- 常用JVM虚拟机参数说明
二.GC日志启用与分析
1.输出GC日志
- GC日志相关参数
- 发生OOM时dump堆内存快照相关参数
2.分析GC日志
配置以下JVM参数,发生GC时将日志输出到指定文件中
#显示GC的详细信息 应用执行的时间 打应用被暂停的时间 gc信息输出到/data/jvm_log/gc.log文件中
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -Xloggc:/data/jvm_log/gc.log
YongGC/MinorGC日志
2019-04-18T14:52:06.790+0800: 2.653: [GC (Allocation Failure) [PSYoungGen: 33280K->5113K(38400K)] 33280K->5848K(125952K), 0.0095764 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
含义:
2019-04-18T14:52:06.790+0800(当前时间戳): 2.653(应用启动基准时间): [GC (Allocation Failure) [PSYoungGen(表示 Young GC): 33280K(年轻代回收前大小)->5113K(年轻代回收后大小)(38400K(年轻代总大小))] 33280K(整个堆回收前大小)->5848K(整个堆回收后大小)(125952K(堆总大小)), 0.0095764(耗时) secs] [Times: user=0.00(用户耗时) sys=0.00(系统耗时), real=0.01(实际耗时) secs]
FullGC日志
2019-04-18T14:52:15.359+0800: 11.222: [Full GC (Metadata GC Threshold) [PSYoungGen: 6129K->0K(143360K)] [ParOldGen: 13088K->13236K(55808K)] 19218K->13236K(199168K), [Metaspace: 20856K->20856K(1069056K)], 0.1216713 secs] [Times: user=0.44 sys=0.02, real=0.12 secs]
含义:
2019-04-18T14:52:15.359+0800(当前时间戳): 11.222(应用启动基准时间): [Full GC (Metadata GC Threshold) [PSYoungGen: 6129K(年轻代回收前大小)->0K(年轻代回收后大小)(143360K(年轻代总大小))] [ParOldGen: 13088K(老年代回收前大小)->13236K(老年代回收后大小)(55808K(老年代总大小))] 19218K(整个堆回收前大小)->13236K(整个堆回收后大小)(199168K(堆总大小)), [Metaspace: 20856K(持久代回收前大小)->20856K(持久代回收后大小)(1069056K(持久代总大小))], 0.1216713(耗时) secs] [Times: user=0.44(用户耗时) sys=0.02(系统耗时), real=0.12(实际耗时) secs]
完整日志
Application time: 0.0044872 seconds
[GC (System.gc()) [PSYoungGen: 10653K->5638K(76288K)] 10653K->5646K(251392K), 0.0022633 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (System.gc()) [PSYoungGen: 5638K->0K(76288K)] [ParOldGen: 8K->5381K(175104K)] 5646K->5381K(251392K), [Metaspace: 3510K->3510K(1056768K)], 0.0047247 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
Total time for which application threads were stopped: 0.0072102 seconds, Stopping threads took: 0.0000289 seconds
Heap
PSYoungGen total 76288K, used 1966K [0x000000076b000000, 0x0000000770500000, 0x00000007c0000000)
eden space 65536K, 3% used [0x000000076b000000,0x000000076b1eb9e0,0x000000076f000000)
from space 10752K, 0% used [0x000000076f000000,0x000000076f000000,0x000000076fa80000)
to space 10752K, 0% used [0x000000076fa80000,0x000000076fa80000,0x0000000770500000)
ParOldGen total 175104K, used 5381K [0x00000006c1000000, 0x00000006cbb00000, 0x000000076b000000)
object space 175104K, 3% used [0x00000006c1000000,0x00000006c15415d0,0x00000006cbb00000)
Metaspace used 3527K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 384K, capacity 388K, committed 512K, reserved 1048576K
Application time: 0.0005665 seconds
具体分析
-
[GC 和 [Full GC表示垃圾收集器的停顿类型,而不是用来区分新生代GC还是老年GC的。- 如果是调用了
System.gc()所触发的GC,那么将显示[Full GC (System),如上所示。
- 如果是调用了
-
接下来的“[DefNew” 或者 “[Tenured” 或者“[Perm” 表示GC发生的区域,
和使用的GC收集器相关。- 如果是
Serial收集器,新生代名为“Default New Generation”,所以显示“[DefNew”。 - 如果是
ParNew收集器,新生代名为“Parallel New Generation”,所以显示“[ParNew”。 - 如果是
Parallel Scavenge收集器,新生代名则显示为“[PSYongGen”, 如上所示。 - 老年代和永久代同理,名称也是由收集器决定的。
- 如果是
-
后面方括号内部的
10653K->5638K(76288K)含义是 “GC前该内存区域已经使用的容量->GC后该内存区域已使用的容量(该内存区域中容量)” -
方括号之外的
10653K->5646K(251392K)表示“GC前Java堆已使用容量->GC后Java堆已使用容量(Java堆中容量)” -
再往后
0.0022633 secs表示该内存区域GC所占用的时间,单位秒。

-
第一行为
年轻代的大小,大小为76288K。而年轻代又分为3个区域分别叫Eden,和2个Survivor区(from和to)。Eden用来存放新的对象,Survivor区用于 新对象 升级到老年代时的 拷贝。默认Eden:from:to比例 为 8:1:1( 通过参数–XX:SurvivorRatio设置 ) 即:Eden 8/10、from 1/10 、to 1/10 -
默认年轻代(Young)与老年代(Old)比例为 1:2( 通过参数–XX:NewRatio设置 ),即:Young 1/3、Old2/3 -
ParOldGen为老年代,大小为
175104K,,大约为PSYoungGen内存大小的2倍。 从JDK8开始,永久代(PermGen)的概念被废弃掉了,使用叫Metaspace的本地内存区来实现永久代功能。
三.调优总结
1.JVM 调优需要做些什么

JVM 调优具体表现为:1.合理地配置JVM的运行内存空间 2.使用合适的垃圾回收器。
-
内存空间的分配设置:JVM 内存分配不合理最直接的表现就是
频繁 GC,这会导致上下文切换(STW)等性能问题,从而降低系统的吞吐量、增加系统的响应时间。具体的优化包括:调整堆内存空间减少 Full GC、调整年轻代减少 MinorGC、设置合理的 Eden 和 Survivor 区的比例。 -
选择合适的垃圾回收器:GC主要指
堆对象和方法区(元空间)只不过废弃常量和无用的类的回收。对于系统响应时间优先的程序可以选择CMS 回收器或 G1 回收器;而对吞吐量优先的程序,则可以选择Parallel Scavenge 回收器来提高系统的吞吐量。
2.调优原则
一般的Java项目需要进行JVM调优吗?
-
回答是否定的,一般的项目加个xms和xmx参数就够了,在没有全面监控,收集性能数据进行分析之前,调优就是在耍流氓
-
JVM调优听起来很高大上,但是要认识到,JVM调优应该是Java性能优化的最后一颗子弹。JVM调优需要我们观察当前系统的运行状况,也就是系统的性能好坏,才能判断是否需要调优。-
如果系统的响应时间很短,系统资源使用率也很低,那我们做系统调优就完全是
为了调优而调优。
-
如果系统的响应时间很短,系统资源使用率也很低,那我们做系统调优就完全是
-
-
因此:JVM调优不是常规手段,性能问题
第一选择是优化程序代码,最后的选择才是进行JVM调优。
JVM调优步骤:
- 记录好日志;
- 对程序做好性能监控;
- 根据日志和性能监控数据优化程序代码
- 使用工具通过不同的JVM参数进行压测并获得最佳配置。
3.JVM调优的时机
不得不考虑进行JVM调优的是那些情况呢?
- 堆内存(老年代)持续上涨达到设置的
最大值 -
Full GC次数频繁 - GC 停顿时间(
STW)过长(超过1秒) - 系统内出现
OutOfMemory等内存异常; - 系统中使用
本地缓存且占用大量内存空间; - 系统
吞吐量与响应性能不高或下降
4.JVM调优的目标
吞吐量、延迟、内存占用三者类似CAP原则,构成了一个不可能三角,只能选择其中2个进行调优,不可三者兼得。选择了其中2个,必然会以牺牲另一个为代价。
- 低延迟:GC低停顿和GC低频率
- 低内存占用
- 高吞吐量
下面展示了一些JVM调优的量化目标参考实例:
- 堆内存使用率
<= 70%; - 老年代内存使用率
<= 70%; - avg pause time
<= 1秒; - Full GC次数为
0或 avg pause interval>= 24小时 ;
注意:不同应用的JVM调优量化目标是不一样的。
5.JVM调优的步骤
一般情况下,JVM调优可通过以下步骤进行:
- 分析系统运行情况:分析GC日志及堆dump文件,判断是否需要优化,确定瓶颈问题点
- 确定JVM调优量化目标
- 确定JVM调优参数(根据历史JVM参数来调整)
- 依次确定调优内存、延迟、吞吐量等指标
- 对比观察调优前后的差异
- 不断的分析和调整,直到找到合适的JVM参数配置
- 找到最合适的参数,将这些参数应用到所有服务器,并进行后续跟踪
以上操作步骤中,某些步骤是需要多次不断迭代完成的。一般是从满足程序的内存使用需求开始的,之后是时间延迟的要求,最后才是吞吐量的要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行。
6.常用调优策略
1.选择合适的垃圾回收器
-
单核CPU,那么毫无疑问
Serial 垃圾回收器是你唯一的选择。
启用Serial垃圾收集器(年轻代):-XX:+UseSerialGC
-
多核CPU,关注
吞吐量,那么选择PS+PO组合。
启用PS+PO,年轻代Parallel Scavenge回收器 老年代使用Parallel Old回收器: -XX:+UseParallelOldGC
-
多核CPU,关注
用户停顿时间,JDK版本1.6或者1.7,那么选择CMS。
启用CMS垃圾收集器(老年代): -XX:+UseConcMarkSweepGC
-
多核CPU,关注
用户停顿时间,JDK1.8及以上, JVM可用内存6G以上,那么选择G1。
启用G1垃圾收集器:-XX:+UseG1GC
2.调整堆内存大小
现象:GC频率非常频繁。
-
原因:堆内存太小导致需要频繁GC才能释放出足够的空间来创建新的对象,所以
增大堆内存的效果是非常显而易见的。
!!!注意:
如果GC次数非常频繁,但是每次能回收的对象非常少,那么这个时候并非内存太小,而可能是"内存泄露"导致对象无法回收,从而造成频繁GC。
参数配置:
//设置堆初始值
-Xms2g 或 -XX:InitialHeapSize=2048m
//设置堆区最大值
-Xmx2g 或 -XX:MaxHeapSize=2048m
//年轻代内存配置
-Xmn512m 或 -XX:MaxNewSize=512m
3.设置符合预期的停顿时间
现象:程序间接性的卡顿
- 原因:如果不设置具体的停顿时间,垃圾回收器默认以吞吐量为主,那么垃圾回收时间就会不稳定。
!!!注意:不要设置不切实际的停顿时间,
单次GC时间越短也意味着需要更多的GC次数才能回收完原有数量的垃圾.
参数配置:
//GC停顿时间,垃圾回收器会尝试用各种手段达到这个时间
-XX:MaxGCPauseMillis
4.调整内存区域大小比率
现象:某一个分代区域的GC频繁,其他都正常。
-
原因:如果对应
分代区域空间不足,导致需要频繁GC来释放空间,在JVM堆内存无法增加的情况下,可以调整对应区域的大小比率。
!!!注意:也许并非空间不足,
如果GC次数非常频繁,但是每次能回收的对象非常少,那么这个时候并非内存太小,而可能是"内存泄露"导致对象无法回收,从而造成频繁GC。
参数配置:
//survivor区和Eden区大小比率
-XX:SurvivorRatio=6 //Survivor区和Eden区占年轻代比率为1:6,两个S区2:6
//年轻代和老年代的占比
-XX:NewRatio=4 //表示年轻代:老年代 = 1:4 即老年代占整个堆的4/5;默认值=2
5.调整对象晋升老年代的年龄阀值
现象:老年代频繁GC,每次回收的对象很多。
-
原因:如果
晋升老年代年龄阀值过小,年轻代对象很快就进入老年代了,导致老年代对象变多,而这些对象其实在随后的很短时间内就可以回收,这时候可以调整对象的升代年龄阀值,让对象不那么容易进入老年代解决老年代空间不足频繁GC问题。
!!!注意:增加了年龄之后,这些对象在
年轻代的存活时间会变长可能导致年轻代的GC频率增加,并且频繁复制这些新生对象的GC时间也可能变长。
参数配置:
//进入老年代最小的GC年龄,年轻代对象转换为老年代对象最小年龄值,默认值7
-XX:InitialTenuringThreshol=7
6.调整大对象的大小阀值
现象:老年代频繁GC,每次回收的对象很多, 而且单个对象的体积都比较大。
- 原因:如果
大量的大对象直接分配到老年代,导致老年代容易被填满而造成频繁GC,可设置对象直接进入老年代的大小阀值。
注意:这些大对象进入年轻代后可能会使
年轻代的GC频率和时间增加。
参数配置:
//年轻代可容纳的最大对象,大于则直接会分配到老年代,0代表没有限制。
-XX:PretenureSizeThreshold=1000000
7.调整GC的触发时机
现象:CMS,G1 经常 Full GC,程序卡顿严重。
-
原因:G1和CMS
部分GC阶段是并发进行的,业务线程和GC线程一起工作,也就说明GC的过程中业务线程会生成新的对象,所以在GC的时需要预留一部分内存空间来容纳新产生的对象,如果这个时候预留内存空间不足以容纳新产生的对象,那么JVM就会停止并发收集并暂停所有业务线程(STW)来保证垃圾回收的正常运行。这种场景可以通过调整GC触发的时机(比如在老年代占用60%就触发GC),在GC线程与业务线程并行处理时,可以预留足够的空间来。
!!!注意:提早触发GC会
增加老年代GC的频率。
参数配置:
//使用多少比例的老年代后开始CMS收集,默认是68%,如果频繁发生SerialOld卡顿,应该调小
-XX:CMSInitiatingOccupancyFraction=68
//G1混合垃圾回收周期中要包括的旧区域设置占用率阈值。默认占用率为 65%
-XX:G1MixedGCLiveThresholdPercent=65
8.调整 JVM本地内存大小
现象:GC的频率、时间、回收的对象都正常,堆内存空间充足,但是报OOM
- 原因: JVM除了堆内存之外还有一块
堆外内存,这片内存也叫本地内存,可是这块内存区域不足了并不会主动触发GC,只有在堆内存区域触发的时候顺带会把本地内存回收了,而一旦本地内存分配不足就会直接报OOM异常。
注意: 本地内存异常的时候除了上面的现象之外,异常信息可能是
OutOfMemoryError:Direct buffer memory。 解决方式除了调整本地内存大小之外,也可以在出现此异常时进行捕获,手动触发GC(System.gc())。
参数配置:
-XX:MaxDirectMemorySize
7.常见问题
在线上应急过程中要记住,只有一个总体目标:「尽快恢复服务,消除影响」。 不管处于应急的哪个阶段,我们首先必须想到的是恢复问题,恢复问题不一定能够定位问题,也不一定有完美的解决方案,也许是通过经验判断,也许是预设开关等,但都可能让我们达到快速恢复的目的,然后保留部分现场,再去定位问题、解决问题和复盘。

问题 1:CPU使用率高
CPU使用率是衡量系统繁忙程度的重要指标,一般情况下单纯的 CPU使用率高并没有问题,它代表系统正在不断的处理我们的任务,但是如果 CPU 过高,导致任务处理不过来,从而引起CPU Load高,这个是非常危险需要关注的。 CPU使用率没有标准安全值,取决于你是计算密集型还是 IO 密集型,一般计算密集型应用 CPU 使用率偏高CPU Load偏低,IO 密集型相反。
问题原因及定位:
1.频繁 FullGC/YongGC
- 开启GC日志用于查看gc日志 :
-XX:+PrintGCDetails -Xloggc:../logs/gc.log - 查看内存使用和 gc 情况:
jstat -gcutil pid
2.代码消耗,如死循环,md5 等内存态操作
-
使用arthas
-
thread -n 5查看 CPU 使用率最高的前 5 个线程堆栈
-
-
jstack 查找
- 查询Java 进程 id:
ps -ef | grep java - 根据进程id找到 CPU占比最高的线程:
top -Hp pid - 将线程 id 转化 16 进制:
printf '0x%x' tid - 查询Java线程堆栈信息并16进制线程Id进行grep:
jstack pid | grep tid
- 查询Java 进程 id:
问题 2:CPU Load 高
load 指单位时间内活跃进程数,包含运行态(runnable 和 running)和不可中断态( IO、内核态锁)。关键字是运行态和不可中断态,运行态可以联想到 Java 线程的 6 种状态,如下,线程 new 之后处于 NEW 状态,执行 start 进入 runnable 等待 CPU 调度,因此如果 CPU 很忙会导致 runnable 进程数增加;不可中断态主要包含网络 IO、磁盘 IO 以及内核态的锁,如 synchronized 等。

问题原因及定位:
1 CPU 利用率高,可运行态进程数多
- 排查方法见常见问题一
2.iowait,等待 IO
-
vmstat:查看 blocked 进程状况 -
jstack -l pid | grep BLOCKED:查看阻塞态线程堆栈
3.等待内核态锁,如 synchronized
-
jstack -l pid | grep BLOCKED:查看阻塞态线程堆栈 -
profiler dump 线程栈:分析线程持锁情况
问题 3:持续 FullGC
在了解 FullGC 原因之前回顾下 Jvm 的内存相关知识
GC过程
- 新 new 的对象放在
Eden 区,当 Eden 区满之后进行一次MinorGC,并将存活的对象放入S0; - 当
下一次 Eden 区满的时候,再次进行MinorGC,并将Eden和 S0 的存活对象对象放入S1,然后清空Eden和S0垃圾对象,最后交换S0和S1的位置(S0 和 S1 始终有一个是空的); -
依次循环第一、二步,直到 S0 或者 S1 快满的时候将对象放入old 区,直到 old 区满 或 内存不足以放下晋升对象时 进行 FullGC。
永久代和元空间
-
JDK1.7 之前Java 类信息、常量池、静态变量存储在Perm 永久代,类的原数据和静态变量在类加载的时候放入 Perm 区,类卸载的时候清理 -
在 JDK1.8 中,MetaSpace 代替 Perm 区,使用本地内存,常量池和静态变量放入堆区,一定程度上解决了在运行时生成或加载大量类造成的 FullGC,如反射、代理、groovy等。
回收器
-
年轻代
常用 ParNew,复制算法,多线程并行; -
老年代
常用 CMS,标记清除算法(会产生内存碎片),并发收集(收集过程中有用户线程产生对象)。-
关键常用参数
- CMSInitiatingOccupancyFraction:表示老年代使用率达到多少时进行 FullGC;
- UseCMSCompactAtFullCollection:表示在进行 FullGC 之后进行老年代内存整理,避免产生内存碎片。
-
关键常用参数
问题 4:线程池满
Java 线程池以有界队列的线程池为例
- 当新任务提交时,如果业务线程
小于corePoolSize(核心线程),则创建新线程来处理请求。 - 如果业务线程数
等于corePoolSize(核心线程数)时,则新任务被添加到任务队列中,直到队列满。 - 当队列满了后,会继续开辟
新线程(非核心线)来处理任务,但不超过maximumPoolSize(最大线程=核心线程+非核心线程)。 - 当
任务队列满了并且已开辟了最大线程数,此时又来了新任务,ThreadPoolExecutor 会执行拒绝策略。
问题 5:NoSuchMethodException
1.jar 包冲突: java 在装载一个目录下所有 jar 包时,它加载的顺序完全取决于操作系统。
-
mvn dependency:tree -Dverbose: 分析报错方法所在的 jar 包版本,留下新的 - arthas的
sc -d ClassName:查看 jvm 已加载类信息 -
-XX:+TraceClassLoading: 输出类的加载顺序,可以用来排查 class 的冲突问题:
2.同类问题
- ClassNotFoundException
- NoClassDefFoundError
- ClassCastException
问题 6:JVM生成"hs_err_pid"开头的文件
JVM 发生内部崩溃,必然会生成"hs_err_pid"开头的文件。
- 无法申请内存,显示
commit_memory错误
Current thread (0x00007f3e40013000): JavaThread "Unknown thread" [_thread_in_vm, id=11408, stack(0x00007f3e49983000,0x00007f3e49a84000)]
Stack: [0x00007f3e49983000,0x00007f3e49a84000], sp=0x00007f3e49a82360, free space=1020k
Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code)
V [libjvm.so+0x9a32da] VMError::report_and_die()+0x2ea
V [libjvm.so+0x497f7b] report_vm_out_of_memory(char const*, int, unsigned long, char const*)+0x9b
V [libjvm.so+0x81fcce] os::Linux::commit_memory_impl(char*, unsigned long, bool)+0xfe
V [libjvm.so+0x820219] os::pd_commit_memory(char*, unsigned long, unsigned long, bool)+0x29
V [libjvm.so+0x819faa] os::commit_memory(char*, unsigned long, unsigned long, bool)+0x2a
V [libjvm.so+0x99eae9] VirtualSpace::expand_by(unsigned long, bool)+0x1c9
V [libjvm.so+0x99ec6d] VirtualSpace::initialize(ReservedSpace, unsigned long)+0xcd
V [libjvm.so+0x57962f] CardGeneration::CardGeneration(ReservedSpace, unsigned long, int, GenRemSet*)+0x11f
V [libjvm.so+0x46ceed] ConcurrentMarkSweepGeneration::ConcurrentMarkSweepGeneration(ReservedSpace, unsigned long, int, CardTableRS*, bool, FreeBlockDictionary<FreeChunk>::DictionaryChoice)+0x5d
V [libjvm.so+0x57a906] GenerationSpec::init(ReservedSpace, int, GenRemSet*)+0x106
V [libjvm.so+0x56afe4] GenCollectedHeap::initialize()+0x344
V [libjvm.so+0x9751aa] Universe::initialize_heap()+0xca
V [libjvm.so+0x976379] universe_init()+0x79
V [libjvm.so+0x5b1d25] init_globals()+0x65
V [libjvm.so+0x95dc6d] Threads::create_vm(JavaVMInitArgs*, bool*)+0x1ed
V [libjvm.so+0x639fe4] JNI_CreateJavaVM+0x74
这一般是因为 Xmx 设置过大,超过系统可用内存,JVM 申请内存失败。
- 比如服务器总内存
30G,同时运行多个程序, 程序 A 配了10G Xmx, 程序B也配了10G Xmx,Linux的交换空间也没有设置,如果程序AB用满Xmx的那么可用内存必然低于10G,这时如果程序C需要大于10G的内存就很容易发生该错误,直接宕机!
解决方案
-
减少Xmx值使得所有的总和不超过服务器物理内存 - 调整 Xms=Xmx 详见4.常用参数
- 服务器不要运行其他不必要的程序
- 配置一部分
swap空间(虚拟内存)- hs_err_pid.log分析
- JVM致命错误日志(hs_err_pid.log)分析
如果找不到"hs_err_pid"开头的文件,那么这个进程的闪退必然是被从外部终止的。
-
java进程长期内存占用过高,系统需要内存使用的时候没有内存,Linux的
OOM Killer机制会干掉最低优先级的内存 -
检查
/var/log/message,/var/log/dmesg或者对应日期文件,看看有没有类似下面的内容,日志有时间可以判断 -
如
grep 'Out of memory' /var/log/messages
常见问题汇总
线程池满
-
rpc 框架线程池满:高 RT(响应时间)接口进行线程数限流
-
应用内线程池满:
重启可短暂缓解,具体还得看问题原因
CPU 高,load 高
-
单机置换或重启,可短暂缓解,恢复看具体原因 - 集群高且流量大幅增加,
扩容,恢复看具体原因
下游 RT(响应时间)高
限流降级
数据库
- 死锁:
kill 死锁线程 - 慢 sql: 优化sql或sql 限流
【Mysql】太可怕了,跟踪及解决Mysql死锁原来可以这么简单
四.调优实例1-初窥门径
在日常的Java开发中,常见以下问题:
- 内存泄露
- 某个进程突然cpu飙升
- 线程死锁
- 响应变慢
1.浏览量暴增后网站响应速度变慢
问题推测:在测试环境测速度比较快,但是一到生产就变慢,所以推测可能是因为垃圾回收导致的业务线程停顿。
-
定位:通过
jstat -gc指令发现GC次数频率非常高且GC所占用的时间非常长,所以判断是因为GC频率非常高,所以导致业务线程经常停顿,从而造成网页反应很慢。 -
解决方案:因为网页访问量很高,所以对象创建速度非常快,导致堆内存容易填满从而频繁GC,所以这里问题在于
年轻代内存太小,所以这里可以增加JVM内存就行了,所以初步从原来的2G内存增加到16G内存。
第二个问题:增加内存后的确平常的请求比较快了,但是又出现了另外一个问题,就是不定期的会间断性的卡顿,而且单次卡顿的时间要比之前要长很多。
-
问题推测:由于之前的优化加大了内存,所以推测可能是
因为内存加大了,从而导致单次GC的时间变长从而导致间接性的卡顿。 -
定位:还是通过
jstat -gc 指令发现FGC次数变多,但是花费在FGC上的时间是非常高的, 根据GC日志 查看到单次FGC的时间有达到几十秒的。 -
解决方案: 因为JVM默认使用的是
PS+PO的组合,PS+PO垃圾标记和收集阶段都是STW,所以内存加大了之后,需要进行垃圾回收的时间就变长了,所以这里要想避免单次GC时间过长,所以需要使用并发收集器- 当前为JDK1.7所以选择
CMS垃圾收集器,根据之前垃圾收集情况设置了一个预期的停顿的时间,上线后网站再也没有了卡顿问题。
- 当前为JDK1.7所以选择
2.后台导出数据引发的OOM
问题描述: 公司的后台系统,偶发性的引发OOM异常,堆内存溢出。
-
因为是偶发性的,所以第一次简单的认为就是堆内存不足导致,所以单方面的加大了堆内存从4G调整到
8G。 -
但问题依然没有解决,只能从堆内存信息下手,通过开启了
-XX:+HeapDumpOnOutOfMemoryError获得堆内存的dump文件。 -
VisualVM 对 堆dump文件进行分析,通过VisualVM查看到占用内存最大的对象是String对象,本来想跟踪着String对象找到其引用的地方,但dump文件太大,跟踪进去的时候总是卡死,而String对象占用比较多也比较正常,最开始也没有认定就是这里的问题,于是就从线程信息里面找突破点。 -
通过线程进行分析,先找到了几个正在运行的业务线程,然后逐一跟进业务线程看了下代码,发现有个引起我注意的方法,
导出订单信息。 -
因为订单信息导出这个方法可能会有
几万的数据量,首先要从数据库里面查询出来订单信息,然后把订单信息生成excel,这个过程会产生大量的String对象。 -
在订单导出功能测试的过程中发现
导出按钮前端居然没有做点击后按钮置灰交互事件,结果按钮可以一直点,因为导出订单数据本来就非常慢,使用的人员可能发现点击后很久后页面都没反应,结果就一直点,结果就大量的请求进入到后台,堆内存产生了大量的订单对象和EXCEL对象,而且方法执行非常慢,导致这一段时间内这些对象都无法被回收,所以最终导致内存溢出。 -
最终没有调整任何JVM参数,只是
在前端的导出订单按钮上加上了置灰状态,等后端响应之后按钮才可以进行点击,然后减少了查询订单信息的非必要字段来减少生成对象的体积,然后问题就解决了。
3.单个缓存数据过大导致的系统CPU飚高
-
系统发布生产后发现CPU一直飚高到
600%,发现这个问题后首先要做的是定位到是哪个应用占用CPU高,通过top找到了对应的一个java应用占用CPU资源600%。 -
如果是应用的CPU飚高,那么基本上可以定位可能是
锁资源竞争,或是频繁GC造成的。 -
从
GC方向排查,如果GC正常的话再从线程方向排查,首先使用jstat -gc PID 指令打印出GC的信息,发现应用在运行了几分钟GC时间就达到了482秒,那么问这很明显就 是频繁GC导致的CPU飚高。 -
定位到了是GC的问题,那么下一步就是
找到频繁GC的原因了,所以可以从2方面定位了,可能是哪个地方频繁创建对象,或者就是有内存泄露导致内存回收不掉。 -
使用
jmap -dump 指令把堆内存信息dump下来看一下(堆内存空间大的慎用这个指令否则会导致应用暂停时间过长,因为我们的堆内存空间才2G所以也就没考虑这个问题了)。 -
使用JvisualVM导入dump进行离线分析,首先从占用内存最多的对象中查找,结果排名第三看到一个业务VO占用堆内存约10%的空间,很明显这个对象是有问题的。 -
通过业务对象找到了对应的业务代码,发现该对象是
查看新闻资讯信息生成的对象,由于想提升查询的效率,所以把新闻资讯保存到了redis缓存里面,每次调用资讯接口都是从缓存里面获取。 -
把新闻保存到redis缓存里面这个方式是没有问题的,有问题的是
新闻的50000多条数据都是保存在一个key里面,这样就导致每次调用查询新闻接口都会从redis里面把50000多条数据都拿出来,再做筛选分页拿出10条返回给前端。50000多条数据也就意味着会产生50000多个对象,每个对象280个字节左右,50000个对象就有13.3M,这就意味着只要查看一次新闻信息就会产生至少13.3M的对象,那么并发请求量只要到10,那么每秒钟都会产生133M的对象,而这种大对象会被直接分配到老年代,这样的话一个2G大小的老年代内存,只需要几秒就会塞满,从而触发GC。 -
由于问题是因为
单个缓存过大造成的,那么只需要把缓存减小就行,这里把缓存以页的粒度进行缓存,每个key缓存10条作为返回给前端1页的数据,每次查询从缓存拿出10条数据,就避免了此问题的 产生。
4.CPU经常100% 问题定位
问题分析:CPU高一定是某个程序长期占用了CPU资源。
1.找出CPU占用率高的进程。
top 列出系统各个进程的资源占用情况。
2.找出该进程里的哪个线程CPU占用率高。
top -Hp 进程ID 列出对应进程里面的线程占用资源情况
4.找到对应线程ID后, 把线程ID转换为16进制
printf "%x\n" PID 把线程ID转换为16进制
5.jstack PID 打印出进程的所有线程信息,过滤出该线程ID对应信息
jstack 进程ID| grep -30 16进制线程ID
6.最后根据线程的堆栈信息定位到具体业务方法,从代码中找到问题所在。
1. 查看是否有线程长时间的watting 或blocked
2. 如果线程长期处于watting状态下, 关注watting on xxxxxx,说明线程在等待这把锁,然后根据锁的地址找到持有锁的线程。
5.内存飚高问题定位
分析: 内存飚高如果是发生在java进程上,一般是因为创建了大量对象所导致,持续飚高说明 垃圾回收跟不上对象创建的速度,或者内存泄露导致对象无法回。
1.先观察垃圾回收的情况
jstat -gc PID 1000 :查看GC次数,时间等信息,每隔一秒打印一次。
jmap -histo PID | head -20 :查看堆内存占用空间最大的前20个对象类型,可初步查看是哪个对象占用了内存
- 如果GC次数频繁,而且每次回收的内存空间也正常,那说明
对象创建速度过快导致内存一直占用很高;如果每次回收的内存非常少,那说明可能是因为 "内存泄露" 导致内存一直无法被回收。
2.导出堆内存文件快照( 堆内存空间大的慎用这个指令否则会导致应用暂停时间过长,我的才2G)
jmap -dump:live,format=b,file=/home/myheapdump.hprof PID :dump指定Java进程堆内存信息到文件
3、使用JvisualVM对dump文件进行离线分析,找到占用内存高的对象,再找到创建该对象的代码位置,从代码和业务场景中定位问题。
6.数据分析平台系统频繁 Full GC
该平台主要对用户在 App 中行为进行定时分析统计,并支持报表导出,使用 CMS GC 算法。
-
发现页面打开经常卡顿,通过
jstat 命令发现系统每次 Young GC 后大约有 10% 的存活对象进入老年代。 -
原因为
Survivor 区空间设置过小,每次 Young GC 后存活对象在 Survivor 区域放不下,提前进入老年代,导致老年代满了后触发Full GC-
通过
调大 Survivor 区,使得 Survivor 区可以容纳 Young GC 后存活对象,对象在 Survivor 区经历多次 Young GC 达到年龄阈值才进入老年代。 -
调整之后每次 Young GC 后进入老年代的对象稳定运行时仅
几百 Kb,Full GC 频率大大降低。
-
7.线程锁死/无限等待
表现: 系统无法访问时,当前cpu占用非常低
- 使用 jstack命令输出线程堆栈即可
jstack 进程ID >> 1.txt
或
jstack -F 进程ID >> 1.txt
或
jstack -l 进程ID | grep -i -E 'BLOCKED | deadlock'
- 或者用
jprofiler工具看堆栈,或者其他任何可以拿到堆栈的工具都可以, java的堆栈就是java方法调用的路径,可以定位一些简单问题
五.调优实例2-登堂入室
1.CPU 利用率高/飙升
表现
CPU全部占满,应用内存达到配置Xmx最大值
常见原因:
- “
内存泄露” 导致对象无法回收,从而造成频繁GC。 - 死循环、线程阻塞、io wait等
public class CpuReaper {
public static void main(String[] args) {
for (int i = 0; i < 8; i++) {
new Thread(() -> {
CpuReaper cpuReaper = new CpuReaper();
cpuReaper.cpuReaper();
}).start();
}
}
public void cpuReaper() {
int num = 0;
long start = System.currentTimeMillis() / 1000;
while (true) {
num = num + 1;
if (num == Integer.MAX_VALUE) {
log.info("reset");
num = 0;
}
if ((System.currentTimeMillis() / 1000) - start > 1000) {
return;
}
}
}
}
第一步:定位出问题的线程
方法 1: 传统的方法
1. top 定位CPU占比最高的Java进程ID
还可以使用
pwdx pid命令找到业务进程路径,进而定位到负责人和项目:

2.top -Hp pid 定位CPU占比最高的线程ID
3. printf '0x%x' tid 将线程 id 转化 16 进制
> printf '0x%x' 12817
> 0x3211
4. jstack pid | grep tid 找到线程堆栈
> jstack 12816 | grep 0x3211 -A 30

方法 2: show-busy-java-threads
show-busy-java-threads教程
show-busy-java-threads脚本
- 这个脚本来自于github上一个开源项目,项目提供了很多有用的脚本,
show-busy-java-threads就是其中的一个。使用这个脚本,可以直接简化方法A中的繁琐步骤。如下:
> wget --no-check-certificate https://raw.github.com/oldratlee/useful-scripts/release-2.x/bin/show-busy-java-threads
> chmod +x show-busy-java-threads
> ./show-busy-java-threads
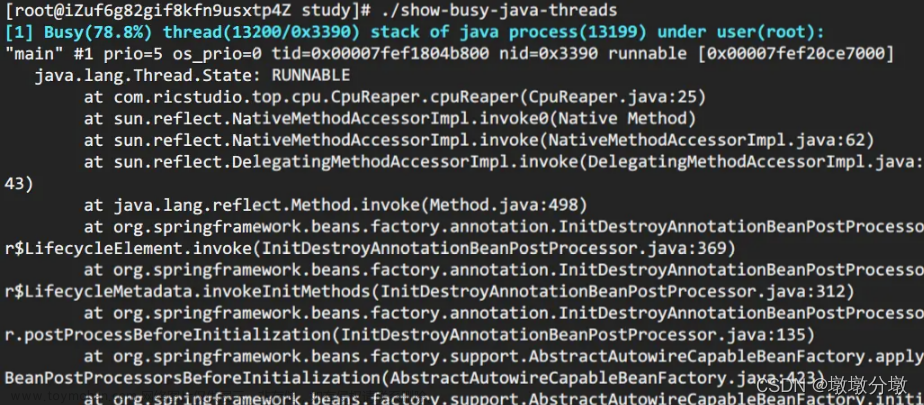
# 默认从所有运行的Java进程中找出最消耗CPU的5个线程,打印出其线程栈
show-busy-java-threads
#可以手动指定要分析的Java进程Id,以保证只会显示你关心的那个Java进程的信息
show-busy-java-threads -p <指定的Java进程Id>
show-busy-java-threads -c <要显示的线程栈数>
方法 3: arthas thread
阿里开源的arthas现在已经几乎包揽了我们线上排查问题的工作,提供了一个很完整的工具集。在这个场景中,也只需要一个thread -n命令即可。
> curl -O https://arthas.gitee.io/arthas-boot.jar # 下载

要注意的是,arthas的cpu占比,和前面两种cpu占比统计方式不同。前面两种针对的是
Java进程启动开始到现在的cpu占比情况,arthas这种是一段采样间隔内,当前JVM里各个线程所占用的cpu时间占总cpu时间的百分比。
- 具体见官网
arthas使用
Arthas 是阿里巴巴开源的Java 诊断工具,基于Java Agent方式,使用 Instrumentation修改字节码方式进行 Java 应用诊断
常用命令:
-
dashboard:系统实时数据面板, 可查看线程,内存,gc 等信息 -
thread:查看当前线程信息,查看线程的堆栈,如查看最繁忙的前 n 线程 - getstatic:获取静态属性值,如 getstatic className attrName 可用于查看线上开关真实值
- sc:查看 jvm 已加载类信息,可用于排查 jar 包冲突
- sm:查看 jvm 已加载类的方法信息
- jad:反编译 jvm 加载类信息,排查代码逻辑没执行原因
- logger:查看logger信息,更新logger level
- watch:观测方法执行数据,包含出参、入参、异常等
watch xxxClass xxxMethod " {params, throwExp} " -e -x 2
watch xxxClass xxxMethod “{params,returnObj}” “params[0].sellerId.equals(‘189’)” -x 2
watch xxxClass xxxMethod sendMsg ‘@com.taobao.eagleeye.EagleEye@getTraceId()’ - trace:方法内部调用时长,并输出每个节点的耗时,用于性能分析
- tt:用于记录方法,并做回放
arthas常见问题解决
第二步:具体问题具体分析
场景1:CPU占比最高的都是GC线程
GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fd99001f800 nid=0x779 runnable
GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fd990021800 nid=0x77a runnable
GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007fd990023000 nid=0x77b runnable
GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007fd990025000 nid=0x77c runnable
当发生内存溢出的时候,或快要内存溢出的时候,JVM 发现内存不够就会 GC,所有 GC线程开始工作,暂停 JVM 运行,如果回收到内存了,JVM正常执行
如果执行GC没有回收到什么内存,GC会循环持续执行,这就导致了cpu全部占满的现象,所以说"内存溢出的时候,一定伴随cpu占满“
场景2:CPU占比最高的都是业务线程
-
iowait,等待 IO
-
vmstat:查看 blocked 进程状况 -
jstack -l pid | grep BLOCKED:查看阻塞状态线程堆栈
-
-
等待内核态锁,如 synchronized
-
jstack -l pid | grep -i -E 'BLOCKED | deadlock': 查看阻塞状态线程堆栈 -
profiler dump 线程栈,分析线程持锁情况
-
使用arthas的thread -b指令,查询当前阻塞其他线程的线程。
-
2.频繁 GC
GC处理过程

解决方案
查看gc日志-
jstat -gcutil {进程号} {统计间隔毫秒} {统计次数}(默认代表一直统计)
HotSpot JVM有一类特别的参数叫做
可管理的参数,可以在运行时动态修改。
- 通过JDK自带的
jinfo工具修改 (如“PrintGC”开头的都是动态参数,可以在运行时开启或是关闭GC日志。)- 通过
JMX客户端调用HotSpotDiagnostic MXBean的setVMOption方法来设置这些参数。- 通过
arthas的vmoption命令更新VM诊断相关的参数
获取到gc日志之后,可以上传到GC easy帮助分析,得到可视化的图表分析结果。


GC 原因及定位(常见问题 3:持续 FullGC)
晋升老年代失败
-
从survivor区晋升的对象在老年代也放不下导致 FullGC(FGC 回收无效则抛 OOM)。
-
可能原因:
-
survivor 区太小,对象过早进入老年代
查看 SurvivorRatio 参数
java -XX:+PrintFlagsFinal -version | grep 'SurvivorRatio' - 大对象分配,没有足够的内存:dump堆快照,使用 jhat/JProfiler/MAT 分析对象占用情况
- 老年代存在大量对象:dump堆快照,使用jhat/JProfiler/MAT 分析对象占用情况
-
survivor 区太小,对象过早进入老年代
你也可以从Full GC 的效果来推断问题
-
正常情况下,一次Full GC应该会回收大量内存,所以 「
正常的堆内存增长曲线应该是呈锯齿形」。- 如果你发现Full gc 之后
堆内存几乎没有下降,那么可以推断: 「堆中有大量不能回收的对象且在不停膨胀,使堆的使用占比超过Full GC的触发阈值,但又回收不掉,导致Full GC一直执行。「换句话来说,可能是」内存泄露」了。
- 如果你发现Full gc 之后
一般来说,GC相关的异常推断都需要涉及到「内存分析」,使用jmap之类的工具dump出堆内存快照(或者 Arthas的heapdump)命令,然后使用MAT、JProfiler、JVisualVM等可视化内存分析工具。
问题原因及定位:
1. 晋升老年代失失败:从S区晋升的对象在老年代也放不下导致 FullGC(FGC 回收无效则抛 OOM)。原因:
-
survivor 区太小,对象过早晋升老年代
- 查看 Survivor区占比:
java -XX:+PrintFlagsFinal -version | grep 'SurvivorRatio' -
jstat -gcutil pid 1000: 观察内存运行情况; -
jinfo pid: 查看 SurvivorRatio 参数;
- 查看 Survivor区占比:
-
大对象分配,没有足够的内存
- GC日志查找关键字 “
allocating large” - dump堆快照,然后使用 jhat/JProfiler/MAT 分析大对象分布情况
- GC日志查找关键字 “
-
老年代存在大量对象
- 实例数量前十的类:
jmap -histo pid | sort -n -r -k 2 | head -10 - 实例容量前十的类:jmap -histo pid | sort -n -r -k 3 | head -10
- dump堆内存快照,使用jhat/JProfiler/MAT 分析对象占用情况
- 实例数量前十的类:
2.concurrent mode failed(CMS并发收集失败)在 CMS GC 过程中业务线程将对象放入老年代(并发收集的特点)内存不足。原因:
-
FGC 触发比例过大,导致老年代占用过多,并发收集时用户线程持续产生对象导致达到触发 FGC 比例。
-
jinfo pid: 查看CMSInitiatingOccupancyFraction参数,一般 70~80 即可
-
-
老年代存在内存碎片。
-
jinfo pid: 查看UseCMSCompactAtFullCollection参数,在 FullGC 后整理内存
-
你也可以从Full GC 的效果来推断问题
-
正常情况下,一次Full GC应该会回收大量内存,所以 「
正常的堆内存曲线应该是呈锯齿形」。- 如果你发现Full gc 之后
堆内存几乎没有下降,那么可以推断: 「堆中有大量不能回收的对象且在不停膨胀,使堆的使用占比超过Full GC的触发阈值,但又回收不掉,导致Full GC一直执行。「换句话来说,可能是」内存泄露」了。
- 如果你发现Full gc 之后
一般来说,GC相关的异常推断都需要涉及到「内存分析」,使用jmap之类的工具dump出堆内存快照(或者 Arthas的heapdump)命令,然后使用MAT、JProfiler、JVisualVM等可视化内存分析工具。
问题原因及定位:
1.下游 RT 高,超时时间不合理
- 业务监控
- sunfire
- eagleeye
2 数据库慢 sql 或者数据库死锁
- 日志关键字 “
Deadlock found when trying to get lock” -
jstack -l pid | grep BLOCKED或zprofiler查看阻塞态线程【Mysql】太可怕了,跟踪及解决Mysql死锁原来可以这么简单
3 Java 代码死锁
jstack –l pid | grep -i –E 'BLOCKED | deadlock'-
dump thread通过 zprofiler 分析阻塞线程和持锁情况
相关好文文章来源:https://www.toymoban.com/news/detail-831566.html
彻底理解对象内存分配及Minor GC和Full GC全过程
如何优化生产环境的Full GC?
阿里二面:说说JVM的Stop the World?
JVM调优之GC调优——吞吐量优先(二)
JVM调优之GC调优——响应时间优先(三)
【JVM进阶之路】七:垃圾收集器盘点
JVM-09自动内存管理机制【内存分配和回收策略】
JVM - G1初探文章来源地址https://www.toymoban.com/news/detail-831566.html
到了这里,关于【Jvm】性能调优(下)线上问题排查思路汇总的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!