目录
常用方式
特征
潜在问题
信息安全
高性能
UUID
雪花算法
数据库生成
美团Leaf方案
Leaf-segment 数据库方案
Leaf-snowflake 方案
常用方式
- uuid
- 雪花算法
- 数据库主键
特征
- 全局唯一
- 趋势递增
- 信息安全
潜在问题
信息安全
- 如果id连续递增, 容易被爬虫, 批量下载数据
- 如果订单id是连续递增, 容易被竞争对手推算出日交易量, 这时候需要ID不规则
- 可能泄漏本机mac地址
高性能
保证在高qps时候, 系统也高可用, 延迟低
UUID
标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 36 个字符.
示例:ecb02c7d-0a3f-4c00-85f6-aa5c6962eb4d
优点: 本地生成, 性能高, 没有网络消耗
缺点:
- UUID太长不易储存, 16字节, 128位
- 信息不安全. 基于 MAC 地址生成UUID的算法, 可能造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置
- 不适合做DB主键. 数据库主键应该越短越好, uuid随机性, 导致聚集索引的数据频繁变动, 影响性能
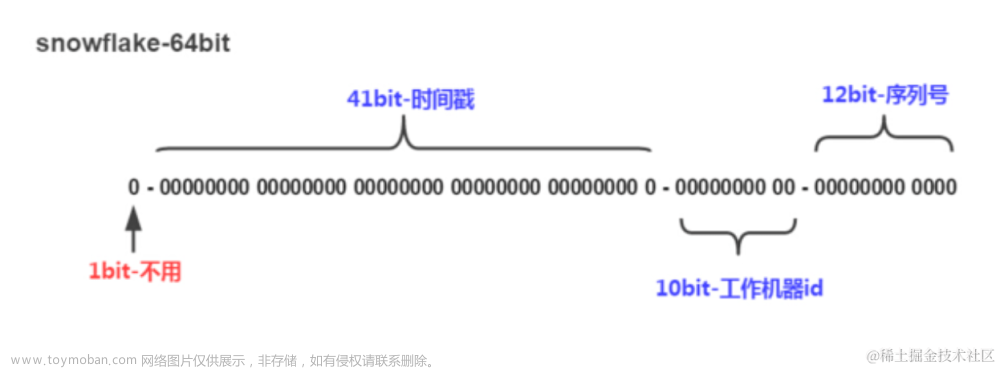
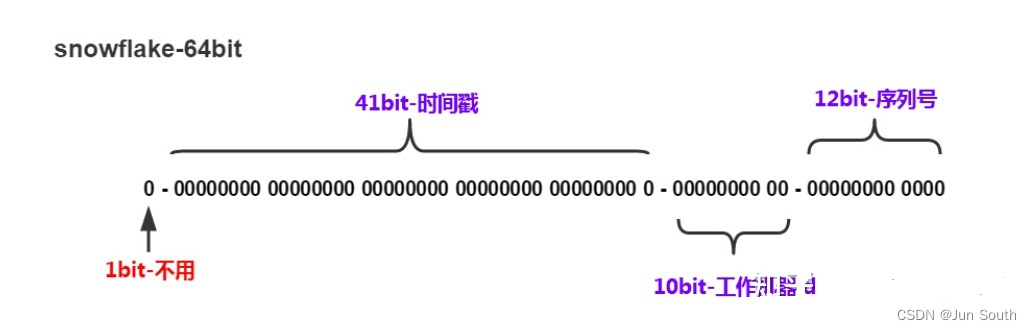
雪花算法

- 第 0 位: 符号位(标识正负),始终为 0,没有用,不用管。
- 第 1~41 位 :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
- 第 42~52 位 :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整),这样就可以区分不同集群/机房的节点,这样就可以表示 32 个 IDC,每个 IDC 下可以有 32 台机器。
- 第 53~64 位 :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。理论上 snowflake 方案的 QPS 约为 409.6w/s
优点:
- 顺序递增, 时间戳在高位, 自增序列在地位
- 本地生成, 不依赖第三方主键, 稳定性更高, 性能高
- 可以根据自身业务, 灵活分配bit位
缺点:
存在时钟回拨问题
数据库生成
- mysql自增主键
- redis的incr命令
- mongodb的ObjectId
- zookeeper顺序节点
美团Leaf方案
Leaf 这个名字是来自德国哲学家、数学家莱布尼茨的一句话:
There are no two identical leaves in the world(“世界上没有两片相同的树叶”)
Leaf 分别在 MySQL 和雪花上做了相应的优化,实现了 Leaf-segment 和 Leaf-snowflake 方案。
Leaf-segment 数据库方案
==文章来源地址https://www.toymoban.com/news/detail-831667.html文章来源:https://www.toymoban.com/news/detail-831667.html
Leaf-snowflake 方案
==
到了这里,关于分布式id实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!