链表
链表基础
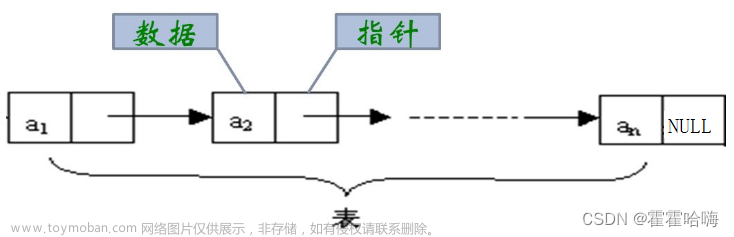
首先链表有数据域和指针域,其次链表在内存中不是连续分布的,链表查找慢,增删灵活。
链表有以下几种类型:
(1)单向链表: 头增头删快,因为一般都是给链表表头没有表尾的概念了。
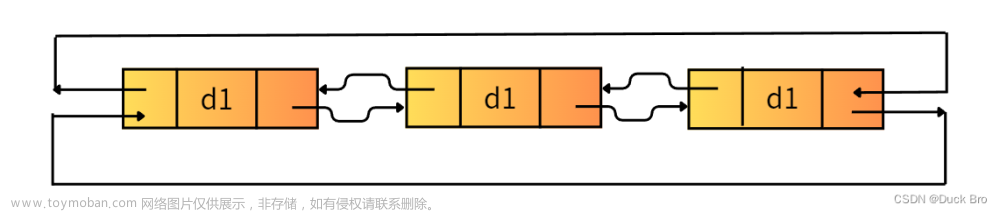
(2)双向链表: 每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点,既可以向前查询也可以向后查询。
(3)循环链表:链表首尾相连。
链表的创建
我们用尾添加来创建一个链表,如果只有一个表头变量Head,那么我们每添加一个节点都要遍历一遍当前链表,有些慢,所以我们引入一个表尾变量Tail来辅助创建链表。
步骤:
(1)Head(是创建完给出的)Tail(是辅助创建用的,不是应该得到的)
(2)结构体
typedef struct node
{
int value;
struct node* pNext;
}List;(注:typedef struct node在C语言中要使用,不然定义一个指针都要像这样:struct node *p;)
(3)创建
首先将当前数据装到对应节点中num->node。
其次将当前节点放到链表中node->list。
代码:
#include<stdio.h>
typedef struct node
{
int value;
struct node* pNext;
}List;
List* Creat() {
List* pHead=NULL;
List* pTail=NULL;
List* pTemp = NULL;
printf_s("输入链表长度\n");
int len;
scanf_s("%d", &len);
while (len--)
{
int num;
scanf_s("%d", &num);
pTemp = (List*)malloc(sizeof(List));
pTemp->value = num;
//初值必须放,要不然会变成野地址
pTemp->pNext = NULL;
if (pHead == NULL) {
pHead = pTemp;
}
else {
pTail->pNext = pTemp;
}
pTail = pTemp;
}
return pHead;
}
void Print(List* pH)
{
while(pH)
{
printf_s("%d ", pH->value);
pH = pH->pNext;
}
}
int main() {
List* pHead = NULL;
pHead = Creat();
Print(pHead);
return 0;
}单向链表的倒序输出
采用递归,设置一个明确的终点,一次次往下遍历,如果最后为NULL,就是遍历到头了。
#include<stdio.h>
typedef struct node {
int value;
struct node* pNext;
}List;
List* Create()
{
int len;
int num;
List* pHead = NULL;
List* pTail = NULL;
List* pTemp = NULL;
printf_s("输入链表长度\n");
scanf_s("%d", &len);
while (len--)
{
pTemp = (List*)malloc(sizeof(List));
scanf_s("%d", &num);
pTemp->value = num;
pTemp->pNext = NULL;
if (pHead == NULL)
pHead = pTemp;
else
pTail->pNext = pTemp;
pTail = pTemp;
}
return pHead;
}
//递归法
List* Reprint(List* pHead)
{
//如果为空那就遍历到头了
if (pHead == NULL) return;
Reprint(pHead->pNext);
printf_s("%d ", pHead->value);
}
int main()
{
List* pHead = NULL;
pHead=Create();
Reprint(pHead);
return 0;
}链表倒置
A->B->C->D变为D->C->B-A
使用头插法:
首先我们设置一个新的头节点,NewHead指向新的头节点,然后我们把A B之间断开,把A带走,A是带走的节点Take指向A,B是被断开的节点Broke指向B。

然后把下面三个指针平移,继续做同样操作


到最后我们只要把,C D连接上就行,而且当Broke指向NULL时,倒置完毕

步骤:
(1)没有或者一个节点
(2)NewHead Take Broke 创建及指向
(3)改变指向,标记位置迭代
#include<stdio.h>
typedef struct node
{
int value;
struct node* pNext;
}List;
List* Create()
{
List* pHead = NULL;
List* pTail = NULL;
List* pTemp = NULL;
int len;
scanf_s("%d", &len);
while (len--)
{
int num;
scanf_s("%d", &num);
pTemp = (List*)malloc(sizeof(List));
pTemp->pNext = NULL;
pTemp->value = num;
if (pHead == NULL)
pHead = pTemp;
else pTail->pNext = pTemp;
pTail = pTemp;
}
return pHead;
}
List* reList(List* pHead)
{
//若为空,或者只有一个数字
if (pHead == NULL || pHead->pNext == NULL) return pHead;
List* newHead = NULL;
List* pTake = pHead;
List* pBroke = pHead->pNext;
//反转
while (1)
{
//改变方向
pTake->pNext = newHead;
if (pBroke == NULL) return pTake;
newHead = pTake;
pTake = pBroke;
pBroke = pBroke->pNext;
}
}
void Print(List* pHead)
{
while (pHead)
{
printf("%d ", pHead->value);
pHead = pHead->pNext;
}
}
int main()
{
List* pHead = NULL;
pHead = Create();
pHead = reList(pHead);
Print(pHead);
return 0;
}两链表合并
两条有序链表合并成一条链表
1->3->6
2->4->7->8
先两个表表头比较 ,1<2,1成为新的表头,1现在是tail也是head,然后1的下一个3和2比较,让1指向2,表尾更新为2,然后让2的下一个4和3比较,表尾更新为3,然后往后继续比较,直到其中一个链表空了,如果有一个链表不为空,把剩下的添加到tail后面。
步骤:
(1)先确定新链表表头
(2)循环比较
(3)将有剩余部分连接
#include<stdio.h>
typedef struct node
{
int value;
struct node* pNext;
}List;
List* Create()
{
List* pHead = NULL;
List* pTail = NULL;
List* pTemp = NULL;
int len;
printf_s("输入链表长度\n");
scanf_s("%d", &len);
while (len--)
{
int num;
scanf_s("%d", &num);
pTemp = (List*)malloc(sizeof(List));
pTemp->pNext = NULL;
pTemp->value = num;
if (pHead == NULL)
pHead = pTemp;
else pTail->pNext = pTemp;
pTail = pTemp;
}
return pHead;
}
List* Merage(List* pHead1, List* pHead2)
{
if (pHead1 == NULL) return pHead2;
if (pHead2 == NULL) return pHead1;
List* pnewHead = NULL;
List* pTail = NULL;
//先找头节点
pnewHead = ((pHead1->value) < (pHead2->value)) ? pHead1 : pHead2;
pTail = pnewHead;
if (pnewHead == pHead1) pHead1 = pHead1->pNext;
else pHead2 = pHead2->pNext;
//循环比较
while (pHead1!=NULL && pHead2!=NULL)
{
pTail->pNext = ((pHead1->value) < (pHead2->value)) ? pHead1 : pHead2;
pTail = pTail->pNext;
if (pTail == pHead1) pHead1 = pHead1->pNext;
else pHead2 = pHead2->pNext;
}
//检测是否有剩余
if (pHead1 != NULL)pTail->pNext = pHead1;
else pTail->pNext = pHead2;
return pnewHead;
}
void Print(List* pHead)
{
while (pHead)
{
printf("%d ", pHead->value);
pHead = pHead->pNext;
}
}
int main()
{
List* pHead1 = NULL;
List* pHead2 = NULL;
pHead1 = Create();
pHead2 = Create();
List* pHead = NULL;
pHead = Merage(pHead1, pHead2);
Print(pHead);
return 0;
}跳表(SkipList)
跳表的前提是为有序链表服务的,是redias底层五种数据结构之一。
跳表的查询增删时间复杂度O(logn)。
我们这里用有5个节点的链表举例,我们现在做查询操作,类似于二分。
因为我们有5个节点,要3层(log5),随机决定长不长上一层(如果像二分一样均分,增删是致命的,要删了某一个整个表都得动),构成类似于简单网状结构。
花费空间:O(n) n/2+n/4+n/8.......
如果查询13,那么L2层它的范围就是哨兵->18,L1层12->18,由于没有13所以查找失败。
如果插入15,那就找15的前一个节点,L2层它的前一个节点是哨兵,L1层它的前一个节点是12,L0层它的前一个节点是12。文章来源:https://www.toymoban.com/news/detail-831684.html
------------------------------明天还是会更新其余链表类型题和相应知识点及思路------------------------------文章来源地址https://www.toymoban.com/news/detail-831684.html
到了这里,关于链表及跳表详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[数据结构]——链表详解](https://imgs.yssmx.com/Uploads/2024/02/709350-1.png)