大家好,我是 Enovo飞鱼,今天继续分享一个爬虫案例,爬取高清4K图片,加油💪。
文章来源地址https://www.toymoban.com/news/detail-831872.html
文章来源:https://www.toymoban.com/news/detail-831872.html
目录
前言
增加异常处理
增加代码灵活性
基本环境配置
爬取目标网站
分析网站页面
具体代码实现
图片下载示例
感谢支持🙇+👍
前言
上篇内容,我们已经了解并惊叹于5行Python代码的强大,今天我们会继续挖掘,并且在原有的基础上进行不断地完善
我们将考虑到多方面的内容,例如,增加异常处理,增加代码灵活性,加快爬取速度……
-
增加异常处理
由于爬取上百页的网页,中途很可能由于各种问题导致爬取失败,所以增加了 try except 、if else 等语句,来处理可能出现的异常,让代码更健壮。
-
增加代码灵活性
初版代码由于固定了 URL 参数,所以只能爬取固定的内容,但是人的想法是多变的,一会儿想爬这个一会儿可能又需要那个,所以可以通过修改 URL 请求参数,来增加代码灵活性,从而爬取更灵活的数据。
基本环境配置
-
版本:Python3
-
系统:Windows
-
相关模块:requests,lxml
-
开发工具:Pycharm
在这里我使用的是 anaconda ,众所周知这是一个大软件,但是它的环境是比较全面的,在之前的学习中,我们用的是这个软件。
anconda,可以理解成运输车,每当下载anconda的时候,里面不仅包含了python,还有180多个库(武器)一同被打包下载下来
下载完anconda之后,再也不用一个个下载那些库了。
爬取目标网站

分析网站页面
有一说一是真的多,看这惊人的页数

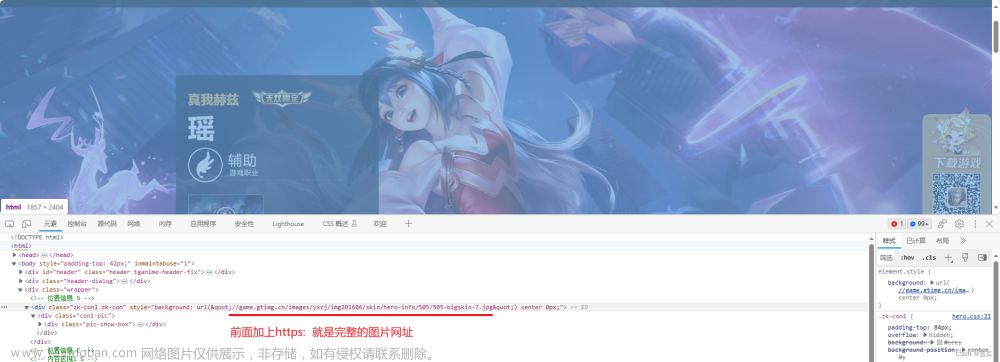
接下来就该看看怎么拿到表情包图片的 url 了,首先打开谷歌浏览器,然后点 F12 进入爬虫快乐模式
然后完成下图的操作,先点击1号箭头,然后再选中一个表情包即可,红色框中就是我们要爬取的对象,其中表情包的src就在里面
如下图:

现在我们就搞清楚了怎么拿到表情包的url了,下一步我们复制 Xpath ,
不了解Xpath的小伙伴们可以去学习一下,也是非常好用的在 XML 文档中查找信息的语言。
如下图,

至此,我们可以写代码了!!!
具体代码实现
相关代码:
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0'
}
x = input('输入页数: ')
for page in range(1, int(x)):
if page == 1:
url = 'https://pic.netbian.com/4kyingshi/'
else:
url = 'https://pic.netbian.com/4kyingshi/index_' + str(page) + '.html'
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk' # 或者gb2312
page_text = response.text
tree = etree.HTML(page_text)
# 以下三种均可
# li_list = tree.xpath('//div[@id="main"]/div[3]/ul/li[1]/a/img')
#li_list = tree.xpath('//div[@class="slist"]/ul/li')
li_list = tree.xpath('//div[@id="main"]/div[@class="slist"]/ul/li')
for li in li_list:
img_src = 'https://pic.netbian.com/' + li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/b/text()')[0] + '.jpg'
img = requests.get(url=img_src, headers=headers).content
with open('./wwww/' + img_name, 'wb') as fp:
fp.write(img)
print(img_name + '保存')
# //*[@id="main"]/div[3]/ul/li[1]/a
# copy xpath
到现在为止,已经拿到了所有的图片的链接和名字,那么就可以开始下载了
运行代码,输入你需要下载的页数即可🐒
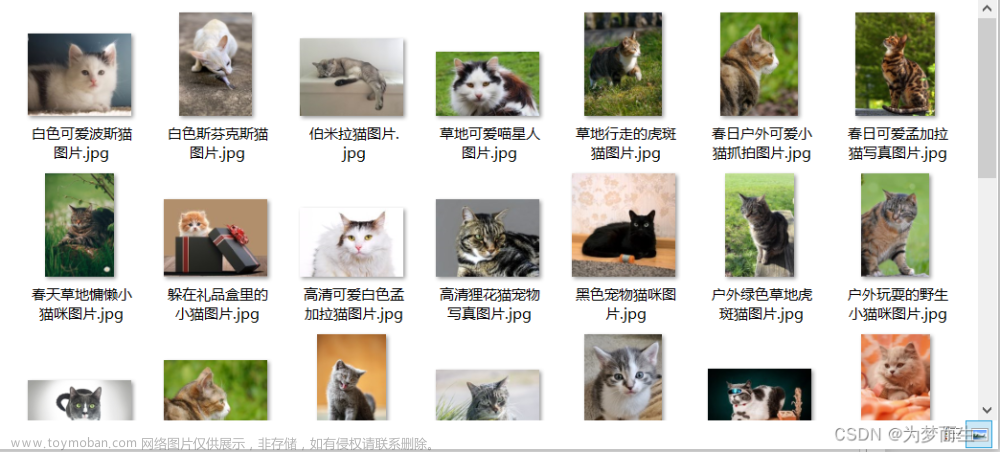
图片下载示例
总共是爬了两页图片,做个示例
见下图 ↓


感谢支持🙇+👍
到了这里,关于爬虫实例(二)—— 爬取高清4K图片的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)