1. 认知科学和心理语言学的发展与任务
认知科学和心理语言学是两个密切相关的领域,它们研究认知过程和语言使用是如何相互作用的。
1.1 认知科学和心理语言学的历史发展
在历史上,这两个领域的发展经历了几个重要的阶段:
1.1.1 19世纪晚期(内省法)
Wundt 和其他德国心理学家使用一种叫做内省法的研究方法。内省法是一种主观的方法,研究者通过自我观察和分析个人的思维过程来研究心理现象。这种方法高度依赖于个体的自我报告,因此在客观性上存在限制。
1.1.2 20世纪20年代(行为主义)
Watson 和其他美国心理学家提出了行为主义。行为主义者拒绝发展任何关于心智操作的理论,他们只观察可见的行为,并尝试通过刺激与反应之间的关系来解释这些行为。这个阶段标志着心理学研究从内部心理过程的探究转向了对外在行为的观察和分析。
1.1.3 二战后(心理语言学)
认知心理学受到信息论(由Shannon提出)、人工智能(Minsky的研究)和生成语言学(Chomsky的工作)的影响。这一时期,心理学家开始关注心智如何处理信息,包括记忆、思维、解决问题等认知过程。心理语言学作为心理学和语言学交叉的一个分支,专注于研究语言获取、语言理解和语言产生的心理机制。
1.1.4 在最近几十年(大脑在进行认知活动时的活动模式)
新的洞察来自于神经生理技术的发展,如功能性磁共振成像(Functional Magnetic Resonance Imaging, FMRI)、正电子发射断层扫描(Positron Emission Tomography, PET)、磁脑电图(Magnetoencephalography, MEG)等。这些技术使得科学家能够直接观察大脑在进行认知活动时的活动模式,从而提供了关于认知过程和语言处理的新见解。
总的来说,认知科学和心理语言学是通过不断发展的研究方法和技术,从不同角度探索人类认知和语言能力的领域。随着时间的推移,这些领域在理论和实践上都取得了显著的进展。
1.2 心理语言学的主要任务
心理语言学涉及到语言产生、理解和加工等多个方面。这一领域旨在解析个体是如何规划、产出、理解语言的,以及这一过程中所涉及的认知机制和大脑活动。以下是主要任务:
1.2.1 规划语句(Planning Utterances)
探讨个体如何组织和规划要表达的思想和信息,包括选择合适的语言结构和词汇来传达意图。
1.2.2 寻找词汇(Finding Words)
分析语言用户如何从其词汇库中选择恰当的词汇来表达思想,包括词汇检索的过程和机制。
1.2.3 构建词汇(Building Words)
研究词汇的形成过程,包括词形变化和词汇的组合,以及这一过程对语言产出的影响。
1.2.4 监控和修正(Monitoring and Repair)
讨论个体如何在语言产出过程中监控和评估自己的语言,以及在发现错误时如何进行修正。
1.2.5 手势的使用(The Use of Gesture)
分析手势如何与言语交互作用,支持语言的表达和理解,以及手势在沟通中的作用。
1.2.6 语言的感知(Perception for Language)
探索大脑如何处理和理解语言信号,包括听觉和视觉信息的接收和加工。
1.2.7 口语词汇识别(Spoken Word Recognition)
研究个体如何识别和理解口语中的词汇,包括声音信号的处理过程。
1.2.8 视觉词汇识别(Visual Word Recognition)
探讨如何通过视觉加工识别书写文字,包括阅读过程中的字形和词汇处理。
1.2.9 句法句子处理(Syntactic Sentence Processing)
分析个体如何理解句子的结构,以及如何通过句法规则构建意义。
1.2.10 解释句子(Interpreting Sentences)
讨论在语境中理解和解释句子含义的过程,包括推断和语境效应。
1.2.11 建立连接(Making Connections)
探索个体如何将新的语言信息与已有知识联系起来,以及这一过程对理解和记忆的影响。
1.2.12 语言处理系统的架构(Architecture of the Language Processing System)
综合讨论语言加工的整体结构和组织,包括认知和神经机制,以及不同加工层面之间的交互。
这个计划提供了一个全面的框架,用于探索心理语言学中的关键议题和研究方向,旨在深入理解语言的认知基础和加工机制。
2. 规划语句(Planning Utterances)(1.2.1中提及)
2.1 规划语句
在心理语言学中,规划语句(Planning Utterances)是一个复杂的过程,涉及从最初的想法到最终的语言表达的多个阶段。这一过程通常包括以下几个步骤:
2.1.1 概念化(Conceptualization)
概念化是一个前语言阶段,在这一阶段,我们组织和安排自己的想法,构建一个前言语消息。这个过程发生在我们的内心,使用的是一种被称为心智语言(mentalese,或 mentalais)的内部过程,这种过程并不依赖于任何具体的自然语言形式。
在概念化过程中,我们决定要传达的信息内容,这包括选择相关的概念、想法和意图。
2.1.2 语法编码(Grammatical Encoding)
语法编码是将前言语消息转换为特定语言表达的过程。这个阶段可以进一步分为四个子步骤:
a.词汇选择(Lexical Selection):从我们的词汇库中选择合适的词汇来表达我们的想法。
b.功能分配(Function Assignment):确定各个词汇在句子中的语法角色,比如主语、宾语等。
c.位置处理(Positional Processing):安排词汇在句子中的顺序。
d.成分组装(Constituent Assembly):将选定的词汇和短语组装成完整的句子结构。
2.1.3 音韵编码(Phonological Encoding)
在音韵编码阶段,已经编码的语言内容被进一步处理为内部语音形式。这一步骤涉及到音节和音位的选择,为即将发出的语言制定一个内部的声音计划。
2.1.4 发音(Articulation)
最后一步是发音,即实际产生语言声音或书写文字的过程,属于外部语言/书写。在这个阶段,内部语音形式转化为实际的语音动作,通过口部和发声器官的运动来产出声音,或者通过手部动作在书写媒介上形成文字。
这一连串的过程展示了从最初的思想到实际语言表达的完整转化路径。每个阶段都是高度协调和精细调控的,体现了语言产生过程的复杂性和动态性。
2.2 心智语言(2.1.1中提及)
在规划语言表达的过程中,心智语言(Mentalese)是一个关键的概念,它代表了我们在内心用来组织和加工想法的非言语形式的思维方式。在这一框架下,想法被用来构建一个心理模型,这个模型是通过各种主题角色(如施事者、受事者、行动等)来组织的。这种组织方式有助于我们理解和规划即将进行的语言表达。以下是这一过程中的一些关键点:
2.2.1 心理模型的构建
在心智语言中,我们利用想法构建一个心理模型,该模型包含了我们想要表达的信息的所有相关方面。这个模型是高度抽象的,不依赖于任何具体的自然语言。
心理模型按照主题角色进行结构化,这些角色定义了句子中各个元素的功能和相互关系。例如,施事者(agent)是执行动作的实体,受事者(patient)是动作影响的对象,而行动(action)则描述了发生的具体事件。
2.2.2 语言规划的层次
通过研究说话时的停顿(包括发音停顿、界定性停顿、生理性停顿即呼吸),我们了解到语言规划包含宏观规划(macroplanning)和微观规划(microplanning)两个层次。
宏观规划涉及到整体目标的设定,即我们想要通过语言表达实现的全局目标。
微观规划则关注每一个言语行为,包括如何表达具体的想法、选择恰当的词汇和语法结构等。
2.2.3 说话的流畅性变化
在规划语言表达时,说话可能会更加犹豫,这是因为我们在进行心理模型的构建和细节的规划。这一阶段,说话者可能会频繁地停顿,以组织思路和选择适当的表达方式。
随着言语的继续和规划过程的推进,说话变得更加流畅。这表明说话者已经完成了大部分规划工作,可以较为顺畅地进行语言表达。
这些过程揭示了人类在进行语言表达前的复杂心理活动,包括如何从一系列抽象的想法中构建出有意义的、组织良好的语言输出。通过理解这些过程,我们能够更好地认识到语言产生的复杂性以及人类如何有效地进行沟通。
2.3 语法编码(Grammatical Encoding)(2.1.2中提到)
在语言学中, 功能分配(选择词语的功能)和位置处理(即排序)是两个专门的术语,它们描述了我们在生成语言时大脑内部的两个分离的过程。
2.3.1 位置处理(排序)
这是指在我们说话或写作时,如何决定单词的顺序。在英语中,通常的顺序是主语-动词-宾语,但其他语言可能有不同的顺序。位置处理确保我们把词放在正确的位置,使句子有意义。
2.3.2 功能分配(选择词语的功能)
这是指如何决定每个词在句子中的语法角色。比如在“猫坐在垫子上”这句话中,“猫”是主语,“坐”是动词,“垫子”是宾语。
2.3.3 言语错误
言语错误(如将单词放在错误的位置或使用错误的单词形式)可以帮助我们了解这些过程。例如,如果某人想说“a floor full of holes”(一个满是洞的地板),但不小心说成了“a hole full of floors”(一个满是地板的洞),这个错误可能表明,在他们的大脑中,单词的排序(位置处理)和它们的功能(功能分配)是分开考虑的。这是因为“floor”和“hole”可以在句子中扮演同样的语法角色(都可以做主语),所以它们更容易被交换。
2.3.4 语法启动
语法启动是另一个例证。它是指人们在说过一句话之后,如果要描述一个场景,他们倾向于使用刚才说过的那种句子结构,即使新的场景和之前说的句子内容不相关。这表明,之前的语言结构影响了后来的语言产出,说明位置处理和功能分配是分开进行的,因为人们在没有意识到的情况下就重复了之前的句子结构。
通过这些现象,我们可以了解到,当我们构建句子时,单词的顺序(位置处理)和单词的语法角色(功能分配)是通过不同的心理语言机制来实现的。
3. 寻找单词(1.2.2中提到)
在语言产生过程中寻找单词的两个阶段,即词汇化(lexicalization)的过程:
3.1 找到单词(finding words)
概念(concept)是语言产生的起点,即你想要表达的基本概念或思想。
接下来,你从心智词汇表中检索与该概念相关的抽象形式:词元(lemma)。词元是单词的基本形式,通常是字典中的查找形式,例如动词的原形。
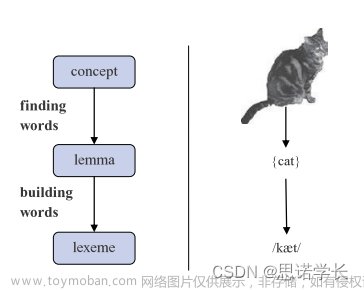
3.2 构建单词(building words)
你构建具体的单词形式变为词位(lexeme),这是词元的具体语音实现,也就是我们说或写的实际单词形式。
在单词选择和语音编码过程中考虑的其他因素:
寻找合适的单词时,会考虑词频(frequency)和可预测性(predictability)。例如,在短语“too many cooks spoil the broth”中,由于短语的固定性和预期性,下一个单词很容易预测。
功能词(function words,如冠词、介词、连词等)在心智词汇表的不同部分,并在构建语法句子框架时变得可用。
整个过程强调了从有一个想法到说出或写出具体单词之间的转换,以及在这个过程中涉及的不同认知步骤。
3.3 心理语言学领域中的词元(lemma)、词位(lexeme)和词素(morpheme)
在心理语言学领域(例如Warren的研究),词元(lemma)、词位(lexeme)和词素(morpheme)是三个重要概念,它们用来描述语言中不同层次的语言单位。
3.3.1 词元(Lemma)
词元(Lemma)通常指的是一组词的词典形式或基本形式,用于代表该单词的所有变化形式。在多数情况下,词元是指动词的不定式形式、名词的单数形式等。例如:英语的 transform 和法语的 superviser 都是词元。这就像是你在字典里查找的单词的“原型”。比如说,动词“run”在字典里只有一个形式,不论它是用在过去时(ran)、现在分词(running)还是其他时态中。中文里的例子就像是“跑”,不管它是“跑步”还是“跑了”。
3.3.2 词位(Lexeme)
词位(Lexeme)是指一个单词的具体形式,是抽象的语言单位,指的是一组具有相同核心意义和用法的词的集合,不考虑时态、数、性等语法变化。例如:
英语的“transformed”和法语的“supervisâmes”都是词位。 它是指单词的具体形式,包括它所有的变化。比如说,“run”这个词位就包括了“run”, “runs”, “ran”, “running”等所有形式。中文里的例子就像是“跑”,“跑了”,“跑步”都属于“跑”这个词位的不同形式。在YH24的定义中,词位与词元(lemma)等同,都指的是词的基本形式。
3.3.3 词素(Morpheme)
词素(Morpheme)是语言中意义的最小单位,不能再分割成更小的有意义部分。语素包括词根、前缀、后缀等形式。例如:英语中的“trans”,“form”,和“-ed”,以及法语中的“super”,“vis”,和“-âmes”都是词素,它们分别代表前缀、词根和表示过去时的后缀。这是语言中最小的意义单位,不能再分割。比如英文中的“un-”(不),“-ed”(过去式标记),中文中的“子”,“们”等等。它们自己不能单独成词,但可以加到其他词素上,给词带来新的意义。
总结来说,词元(lemma)是指词的基本或字典形式,词位(lexeme)是表示一个概念的抽象单位,而语素(morpheme)是构成词的最小有意义单位。这些概念帮助我们从不同角度分析和理解词汇及其结构。
3.3.4 词汇学中的词
词位(Lexeme)被视为词汇学中的基本单位,这与心理语言学中的词元概念相似。
例如:
英语的 transformed 和法语的 supervisâmes 被视为 词 ,它们是具体使用的单词形式。
英语的 transform 和法语的 superviser 在这里被视为词位,相当于心理语言学中的词元(lemma)。
这表明在不同的语言学子领域或不同的理论框架下,相同的术语可能会有不同的定义。在心理语言学中,区分这些概念有助于研究者理解语言处理的不同阶段,这些术语有助于我们理解人们是如何在大脑中处理和产生语言的。比如说,当我们要说一个词的时候,我们的大脑首先会想到这个词的基本意思(词元),然后再找到这个词的具体形式(词位),最后可能会根据需要添加不同的词素来表达不同的时态或者数等语法信息。
而在词汇学中,这些术语的定义和用法可能更加侧重于单词的形态和用法。
3.4 言语错误
在语言学中,研究言语错误可以帮助我们理解寻找单词的机制。言语错误可以被看作是一种学科或爱好,但是它们并不总是可靠的,因为它们可能是口误或者听觉上的错误。言语错误的类型包括:
3.4.1 错误选择(Mis-selection)
替换(Substitution):用一个错误的词替换了原本的词。比如,“Must you leave? It’s still so *late”中的“late”可能本意想说“early”。
混合(Blend):两个词混合成了一个新词。例如,“*buggage”可能是“bag”和“luggage”的混合。
3.4.2 错误排序(Mis-ordering)
预期(Anticipation):一个词出现得太早了。例如,“I’m not a candidate for the cabinet”说成了“I’m not a *cabinet…”。
持续(Perseveration):一个词稍后又重复出现了。比如,“How many pints in a *pint… liter”。
交换(Exchange):两个词的位置被交换了。例如,“Just *piece a *put of cardboard in it”应该是“Just put a piece of cardboard in it”。
3.4.3 遗漏(Omission)
某个词被遗漏了。例如,“It’s an extremely *∅ project”中,可能遗漏了“important”这个词。
3.4.4 添加(Addition)
添加了不必要的词。比如,“He behaved *as like a fool”中的“as”是多余的。
这些错误提供了关于语言生成过程的线索,尤其是在单词选择和语法结构生成方面。通过分析这些错误,语言学家可以更好地理解我们大脑如何在说话时搜索和组织语言。
3.5 大脑内部的不同层次的关系和活动
在寻找单词的过程中,我们大脑内部的不同层次参与了不同的关系和活动:
3.5.1 概念层次关系(Concept-level relationships)
这涉及到语言之前的抽象思想。例如,baggage和luggage虽然意思相近,但不完全相同,人们有时会混合两个词来创造一个新词,如buggage(baggage和luggage的混合词),这种现象称为混合词(blends)。
3.5.2 词元层次关系(Lemma-level relationships)
这些关系是基于联想的。单词之间的联想有时是因为它们常常一起出现(搭配,collocations),但也可以是因为它们是反义词或对立词。
3.5.3 激活联想的因素
词汇的使用频率和可形象化程度(imageability)可能会影响联想的激活。高频词更容易被想到,而那些能够唤起具体形象的词也同样容易激活相关联想。
3.5.4 语音接近性
有时词汇的选择也受到它们语音相近的影响,这可以导致 马拉普罗普主义(malapropism),即错误地使用听起来相似但意义不同的词。这个术语来源于Sheridan的《竞争者》(The Rivals, 1775)中的Mrs Malaprop这一角色,她经常错误地使用词语,比如说epitaphs(墓志铭)来代替“epithets”(形容词)。
3.5.5 错误排序(Mis-orderings)
当词位被选中但被分配到错误的位置时,就会发生错误排序。这种错误通常会被随后纠正。例如,某人可能预期地使用了一个词,或者在一个句子中重复了一个词,或者交换了两个词的位置。
这些认知和语言现象帮助我们了解在生成语言时大脑如何在不同的层次上工作,以及如何处理和选择单词。
4. 建造词汇(Building Words)
4.1 建造词汇的概念
想象一下单词是一座由不同的小砖块(词素)建造的房子。这些建筑的小砖块可以是单个的意义单位,比如不(不开心中的“un-”)、快乐(不开心中的happy)和状态(不开心中的-ness)。而音素就像是这些砖块的颜色和形状,它们告诉我们如何发出这些词素的声音。字素则是这些砖块的书写形式,它们告诉我们如何写下这些声音。
研究发现,当我们建造单词的时候,我们大脑里关于砖块(词素)的组合和它们的颜色形状(音素)的处理是同时发生的。这就像是在我们脑海中同时想象砖块的摆放和它们的外观。
当我们说话或写作时犯错误,比如把不同的砖块(词素)放错地方,这通常发生在一个小区域内,比如我们可能会把“满是洞的地板”说成“满是地板的洞”。
当我们把声音搞混,比如“停车场”说成“车停场”,这也通常发生在我们讲一个小部分内容时。
当我们把整个单词放错位置,比如在描述一个完整的情景时把两个单词完全调换了位置,这通常是在我们脑海中处理更大区域的内容时发生的。
在我们大脑的不同部分,有的地方负责处理整个单词(比如“快乐”这个整体),有的地方负责处理单词的小部分(比如“不”和“状态”这样的小砖块)。当我们说话或写作时,大脑中的这些部分需要协同工作,才能正确地构建和组织我们想说的话。
4.2 "尖端舌头现象"(Tip-of-the-Tongue,简称TOT)
4.2.1 尖端舌头现象(Tip-of-the-Tongue,TOT)
尖端舌头现象(Tip-of-the-Tongue,TOT)是一种我们都有过的体验:当你想说一个词,但是怎么也想不起来,感觉就像词就在嘴边,但就是说不出来。这种体验帮助我们了解心理词汇表的工作方式。例如,我们可能记得想说的词的第一个音,最后一个音,音节的多少,或者是词的哪个部分被强调了。
4.2.2 失名症(anomia)
失名症(anomia)像是一直处于TOT状态,患有这种病的人很难找到对的词来表达他们的想法。
4.2.3 复杂词汇的问题
接下来是关于复杂词汇的问题。复杂的词汇是指由几个不同部分组成的词。比如,英文中的单词 unhappiness 就包含了三个部分:un-(表示“不”)、happy(表示“快乐”)和-ness(一个后缀,用来表示名词)。问题是这些复杂的词汇是不是在我们需要它们的时候现场组装的,还是已经预先准备好的。
答案是,那些用来表示词汇变化的部分(比如变成复数或者过去时)通常是在我们说话的时候加上去的。而对于那些不按常规变化的词汇,我们也是根据需要来现场组装的。比如,在说过去时时,我们可能会不自觉地把过去时的概念加到一个词上,而不是加一个特定的后缀。
wug测试,它表明即使是孩子们也能用他们知道的语言规则来创造新词。在测试中,孩子们会看到一个叫做“wug”的虚构生物,当问他们如果有两个这样的生物应该怎么说时,大多数孩子都会正确地说“wugs”,就像他们用“dog”变成“dogs”一样。这说明我们可以用语言规则来创造我们从未听过的词。

4.3 形态学
形态学(morphology)处理晚期的一些论据,通过词素变化错误来阐述,触及了形态学在语言学中的一个重要领域。形态学研究词的结构和构成,是语言学的一个分支,它帮助我们理解词是如何通过各种形式变化来表达不同的语法功能和意义的。
在形态学中,派生形态学(derivational morphology)和屈折形态学(inflectional morphology)是两个核心子领域。派生形态学关注于如何通过添加词缀(如前缀、后缀)来创建新词或改变词的词性。例如,从动词“run”(跑)派生出名词“runner”(跑者)就是通过添加后缀“-er”。派生形态学不仅增加词汇量,也丰富了语言的表达能力。
屈折形态学则关注于词的形态变化,这种变化不会改变词的词性,但会表达语法关系,如时态、人称、数等。例如,英语中动词的过去式“walked”(走过)就是通过添加“-ed”后缀来表达时间上的变化,而这种变化不改变词的基本意义。
词素变化错误(morpheme shift errors)通常指在使用词素进行派生或屈折时发生的错误,这可能是因为语言学习者对语言规则的掌握不充分,或是由于语言内部规则的复杂性导致的。这类错误在语言学习和语言处理研究中是一个重要的考察点,因为它们可以揭示人们在学习和使用语言时的心理过程及其可能的误区。
通过研究词素变化错误,研究人员可以更好地理解语言的形态学规则,以及人们如何学习和处理这些规则。这对于语言教学、语言恢复治疗和语言技术开发等领域都有重要意义。
4.3.1 词素变化错误
当我们尝试构造词语时,有时会错误地组合词素(语言的最小意义单位)。例如,“pointed out”(指出)错误地变成了“*point outed”,这种错误显示我们在形成词汇时,有时会错误地处理词素顺序或结构。正确的做法是将“point out”作为一个整体理解和使用,而不是分开处理“point”和“out”。
4.3.2 派生形态学中的错误
派生形态学是通过添加前缀或后缀来改变词语的意义。错误地改变这些词素,如把“I regard this as imprecise”(我认为这不准确)错误地改为“I *disregard this as *precise”(我忽略这是准确的),展示了在尝试改变词义时可能犯的错误。这个错误改变了原本的意思,表明了在词义变化过程中的一些挑战。
4.3.3 派生错误与屈折错误
有时派生形态学(改变词的意义)和屈折形态学(改变词的形式以适应语法功能)之间的错误看起来很相似。例如,“Fancy getting your *model *renosed”试图通过添加前缀来创造新词,但这样的尝试可能不符合语言规则,显示了在创新词汇时的挑战。
4.3.4 词素的独立性和生产性
当词素(如后缀“-er”)可以自由地与新词结合时,显示了语言的创造性。例如,“to *spling”虽然不存在,但我们可以理解“a *splinger”意指从事“spling”活动的人。这表明了语言中形态元素的弹性和创造性。
总的来说,这段文字讲述了在语言形态学处理中,如何通过添加、变化或组合词素来创造或改变词汇,以及在这一过程中可能遇到的错误和挑战。
4.4 词语构建的步骤和可能出现的错误类型
在语言产生过程中,特别是在达到语音编码阶段时,词语构建的步骤和可能出现的错误类型。总的来说,这段文字揭示了在语音编码阶段构建词语时的顺序和可能出现的错误,强调了在语音计划生成过程中考虑内容和上下文的重要性,以及错误类型的多样性和它们出现的条件。
4.4.1 语音编码阶段的步骤(说话前的准备步骤)
选择词形: 当我们开始说话时,首先确定要使用的词的基本形式,比如我们想说的动词、名词等。
添加功能词和语法元素: 接着,我们加入如介词、连词等功能词,以及表示时态、数量等的语法元素。
制定语音计划: 然后,我们在脑中制定一个计划,确定如何发音,包括每个词的音节和声调。
执行发音: 最后,根据这个计划,我们的发音器官动作,开始说出这些词。
4.4.2 错误的类型
错误选择(mis-selection)或替换(substitution):选择了错误的词语或语素。有时候,我们可能会说错词,比如想说 cat (猫)却说成了 dog(狗)。
错序(mis-ordering)包括预期(anticipation)、坚持(perseveration)、交换(exchange):词语或语音单元出现在错误的位置。我们可能会把词语或音节顺序弄错,比如把“请给我”说成了“给请我”
省略(omission)和添加(addition):遗漏了应该出现的元素或增加了不应该出现的元素。有时我们可能遗漏某些词或音节,或者在不应该的地方加入额外的词或音节。
4.4.3 错序的原因
错序通常发生在压力(重读)相同的音节上,比如两个都是重读或都不重读的音节可能会被颠倒或混淆。错序通常涉及来自于两个压力相同(要么都重读,要么都不重读)的音节的元素,如“*sedden *duth”。
这段文字解释了在人们说话时,大脑如何准备和组织语音,以及在这个过程中可能出现的错误。以下是一个简化和解释的版本:通过这个过程的描述,我们可以更好地理解说话时脑中发生的复杂过程,以及为什么有时会出现说错词或语序混乱的情况。
4.5 两种典型语言错误
人们在说话时可能犯的两种典型错误,这些错误虽然是无意的,但仍然遵循一定的语言规则:
4.5.1 音节结构的遵循(斯普纳利斯姆)
这是一种将句子中两个词的首个音节部分不小心调换的错误。例如,“The Lord is a *shoving *leopard”实际上是把原本的“loving shepherd”(爱护的牧羊人)调换了音节,导致意思完全改变,变成了“推搡的豹子”。这种错误以经常犯此类口误的威廉·斯普纳牧师的名字命名。
4.5.2 错误的音位相似性
这种错误发生时,人们会把发音相近的音素不小心替换或混淆。比如,“*par *cark”是想说“car park”(停车场),但是把/c/和/p/这两个发音位置相近的音素颠倒了。
简单来说,这段文字说明了即使在说话过程中犯错误,人们仍然会不自觉地遵循语音学的一些基本规则,比如音节的结构和音素的相似性。
4.6 将单词转换成声音的过程、发音错误和研究这些错误的方法
这段文字解释了人们在说话时将单词转换成声音的过程,以及可能出现的发音错误和研究这些错误的一种方法:
4.6.1 单词转换成声音
当我们说一个单词时,我们的大脑会根据这个单词的特定结构(比如它的音节和韵律结构)来安排它的发音。简单来说,就是我们按照每个单词的规则来发出正确的声音。
4.6.2 发音可能出错
当我们同时说很多单词时,这些单词的声音可能会错位,意味着有时候我们可能会把它们发错,因为同时处理多个单词的正确发音挺难的。
4.6.3 错误通常产生真实单词而非无意义的发音
当我们发音错误时,倾向于产生真正的单词,而不是没有意义的声音。这是因为我们的大脑尝试找到最接近的、有意义的单词来匹配我们试图发出的声音。
4.6.4 用绕口令研究发音错误
绕口令是一种特殊设计的句子,用来挑战我们的发音能力,因为它们包含很多容易混淆的音节。通过研究人们在念绕口令时的错误,我们可以更好地了解人们在说话时如何处理和发出单词的声音。例如,英语中有一个绕口令是关于想象中的动物园管理员,法语和捷克语中也有类似的绕口令来测试发音能力。
简而言之,这段文字讲的是我们如何把单词变成声音,为什么有时会出错,以及如何通过绕口令来研究这些错误。
5. 监控和纠正
这段文字讨论了说话者如何自我监控和纠正发音错误,即使没有听众的反馈,以及一些有关发音错误的实验发现和禁忌词汇的处理方式。
5.1 发音错误的实验发现
有实验通过推动参与者犯错来研究发音错误。实验结果显示:
当产生真实单词时,大约20%的错误是斯普纳利斯姆(即音节或音素颠倒的错误);
当产生非词(没有实际意义的词)时,错误比例下降到6%;
当涉及禁忌词(比如“duck fate”这样故意颠倒以避免说出的不雅词汇)时,错误比例进一步下降到4%。
人们在说话时如何自己发现并改正自己的错误,即使别人没有指出来。实验显示当人们说错话时,错误的类型和频率会根据说的是真实的单词、没有意义的假词,还是禁忌词(比如脏话)而变化。实验发现,说真实单词时错误最多,说假词时错误减少,说禁忌词时错误最少。
5.2 禁忌词的处理
法语中的contrepetrie这个概念,这是一种文字游戏,通过调换句子中的字母或音节,使得原本正常的句子变成有趣或者有双关意思的新句子,但听起来很相似。例如,来自Rabelais的《Pantagruel》(1532年)和Gérard Jugnot(1985年)的作品中有使用这种技巧的例子。
À Beaumont le Vicomte这句话可以通过调换音节变为含有性暗示的句子,展示了在文学和日常语言中对禁忌词的巧妙处理。展示了这种文字游戏如何创造出有趣的语言效果。
人类在语言使用中的自我监控能力和创造性,通过实验数据和“contrepetrie”这样的文字游戏,展示了语言的复杂性和趣味性。
5.3 自我监控和修正
说话者在说话过程中会自我监控,如果发现错误,即使没有人指出,他们也会自行纠正。说话者在察觉到自己的发音错误时,进行自我监控和修复的三个阶段:
5.3.1 中断
自我中断可能非常迅速,以至于在错误部分发出之前就发生了,这称为隐性修复(covert repair),占所有中断的25%。
5.3.2 编辑
编辑阶段使用编辑表达式(如“uh”,“eh”等),这些表达式帮助说话者在进行修复之前暂停和组织思维。
5.3.3 修复
修复从编辑后的重新开始(restart)进行。我们通常关注显性修复(overt repairs),即明显地停下来更正错误的那一部分。
编辑表达式和填充暂停(filled pauses,说话时的“嗯”、“啊”这样的停顿声)中的声音没有区别,它们都用于说话过程中的自然停顿。
在重新开始(restart)时,说话者会根据需要回溯到适当的位置:
如果在自我中断之前有一个相同的单词,则回溯到那个单词重新开始;
如果没有相同的单词,则回溯到一个类似类别的单词。
这个过程帮助说话者在不影响交流流畅度的情况下,纠正自己的语言错误。
5.4 修正内容必须符合语法结构
我们进一步讨论说话过程中的自我监控和修正机制,强调了修正内容必须符合语法结构,以及一些相关的发现和练习建议。
5.4.1 修正的部分必须语法正确
修正后的句子部分需要保持语法上的正确性。例如,“Should I go right, I go left?”这样的句子因为语法错误而不会出现在修正中。
5.4.2 词汇错误的修正常常带有韵律标记
修正词汇错误时,通常会通过韵律(语调和节奏)来标记,而声音错误(如发音错误)则不常这样处理。
5.4.3 神经影像学的发现
神经影像学研究表明,无论是内部的还是外部的自我监控,以及听别人说话,我们使用的是大脑中相同的区域。
5.4.4 监控主要是词汇性的
监控过程主要关注词汇,因为非词(不存在的词汇)作为错误出现的频率更低。
5.4.5 未发出的禁忌词引起的情绪反应
通过皮肤电反应(galvanic skin response)的测试显示,即使是未发出的禁忌词也能引起情绪上的反应。
5.4.6 练习建议
对比单词内部的修正和法语中包容性形式的使用,例如“charmant·e·s fonctionnaires territoriaux·ales”。这个练习要求考虑如何在保持语言流畅性和语法正确性的同时,使用包容性形式来反映性别多样性。法语中的包容性形式通过在词尾添加中点和相应的性别标记(如男性和女性复数形式),来确保语言表达的性别包容性。
这些讨论和练习突出了语言使用中的自我监控和修正机制的复杂性,以及语言学研究如何揭示我们处理语言的细节。
6 手势的使用(1.2.5中提到)
6.1 从两个角度探讨手势的使用
在探讨手势的使用时,可以从两个角度来看:心理分析角度和语言学/心理语言学角度。
6.1.1 心理分析角度
从这个角度看,手势被视为揭示个人的心理或情感状态的一种方式。例如,当一个人紧张时,他们可能会不自觉地摩擦手或玩弄手指,这些手势可以被视为内心情绪的外在表现。心理分析家可能会关注这些非言语行为,以理解个人的内在状态。
6.1.2 语言学/心理语言学角度
在这个视角下,手势被认为是交流过程中的一个额外的信息渠道。它不仅仅是言语的附属物,而是与言语并行的一个独立的信息轨道。这个角度强调手势在语言表达中的功能性和补充性,例如,在讲述一个故事或解释一个概念时,手势可以帮助更清晰地传达信息或强调某些点。在这种理解下,交流可以被看作是双轨制的:一条是管理轨道,涉及到如何组织和调整交流流程(例如,通过使用手势来指示轮到谁说话,或来修正先前的说法);另一条是内容轨道,涉及到交流的实际内容。
在内容管理方面,手势可以作为一种编辑表达的工具,类似于口头语言中的修正词汇,帮助说话者管理和调整对话的流程。例如,在一个对话中,使用手势可以指示需要暂停、更正或强调某个点,这属于管理轨道的功能。
综上所述,手势的研究提供了一个理解人类交流多维度的视角,不仅涵盖了言语交流的内容,也包括了对交流过程管理的分析。这种理解强调了非言语行为在人类交流中的重要性,展示了手势如何在揭示个人内心世界和促进复杂的信息传递中发挥作用。
6.2 皮尔斯的符号学三角模型
在探讨手势的使用时,可以参考皮尔斯的符号学三角模型,这个模型将手势分为三类:符号(象征)、指示和图标。
6.2.1 符号(象征)
这类手势具有约定俗成的社会文化意义,它们代表了一种特定的信息或情感,但这种表示并不直接与其形态相关。例如,点头(表示同意)、摇头(表示不同意)、竖起大拇指(表示好或支持)、竖起大拇指向下(表示不好或不支持)、挥手打招呼等,都是符号性手势。这些手势依赖于文化背景,不同文化中的意义可能不同。除了视觉象征,还有听觉象征,如拍手、嘘声、舌头点击声等,它们在不同文化中也承载特定的意义。
6.2.2 指示
指示性手势用于引导观察者的注意力,它们通过指向、点头或目光等方式实现。这类手势通常伴随语言使用,并且需要恰当的时机。例如,用食指指向某物以引起注意,通过点头或目光交流来引导对方注意力。指示性手势同样受文化影响,不同文化中的使用和理解可能有所不同。
6.2.3 图标
图标性手势通过视觉相似性来描述对象或动作。这类手势模仿了它们所代表的对象或动作的形状或特性,因此即便在没有视觉联系的情况下(例如,通过电话交流时)也能被理解。图标性手势的关键在于它们与所描述的对象或动作之间存在直观的相似性,使得即使在缺乏直接视觉线索的情况下,接收者也能理解手势的含义。
综合来看,这三类手势在人类交流中扮演着不同但互补的角色。符号性手势依赖于文化约定,是一种共享的社会符号系统;指示性手势引导注意力,强调交流的方向性;而图标性手势通过模仿增强了表达的直观性。这三种手势的使用丰富了人类的非言语交流,使得沟通变得更为多维和深刻。
6.3 手势在话语管理中发挥的作用
手势在话语管理中发挥着重要作用,它们不仅限于说话者,听众也通过手势参与交流。手势可以用来管理对话的流程、强调话语中的关键点,甚至在非言语层面上表达同情和理解。以下是几种常见的用于话语管理和强调的手势:
6.3.1 话语传递
通过特定的手势向其他人示意“你,继续说”,这种手势有助于顺利地在对话参与者之间转移说话权。
6.3.2 引用
手势可以用来指示“正如你之前所说”,通过这种方式,说话者可以在不打断话语流的情况下引用对方或自己先前的话语。
6.3.3 寻求反馈
说话者可能通过目光接触寻求听众的反应或答案,例如,在提出问题后看向对方,等待回答。
6.3.4 轮换发言权
手势可以用来示意发言权的转移,例如,通过某个手势表示“我说完了,轮到你了”,有助于平滑地在对话中交换发言权。
6.3.5 听众的手势
研究表明,听众也会使用手势来表达他们的反应或情感,如实验中观察到的当设备掉落在手指上时听众做出的同情性皱眉表情,这表明手势也是情感共鸣和同情表达的一种方式。
6.3.6 强调手势(Batonic或节拍手势)
这些手势通常与语言中的重音音节同步,用以加强语言的强调效果。比如,在强调某个词或短语时,说话者可能会伴随着重音节用手指敲打或做出节拍动作,增强言语的强调和表达力。
这些手势的使用不仅丰富了人类的交流方式,还提高了交流的效率和表达的准确性。它们展示了非言语交流在人类相互作用中的复杂性和多样性,以及在维持对话流畅性和增强言语表达中的关键作用。
6.4 手势在语言表达过程中的桥梁角色
手势在语言表达过程中扮演着桥梁的角色,特别是在帮助说话者建立从词元(lemmas)到词位(lexemes)的连接上。这一过程涉及到语言生成的多个层面,包括思维、规划和表达。以下是一些关键观点,概述了手势如何在这一过程中发挥作用:
6.4.1 手势与语言生成的连接
词元是指概念的抽象表达,而词位则是这些概念的具体语言形式。在语言产生过程中,说话者需要从一个抽象的概念(词元)转换到具体的词汇表达(词位)。手势可以帮助说话者在这一转换过程中建立联系,通过非言语的方式辅助思维和语言的表达。
6.4.2 标志性手势与言语的时序关系
研究表明,标志性(图标性)手势往往在与之相关的口语材料之前大约一秒发生。这意味着,当说话者开始进入词汇化过程(即从概念选择具体词汇的过程)时,手势就已经启动。这种时序关系表明手势不仅伴随着言语的产生,而且可能在认知处理中起到预备或促进的作用。
6.4.3 手势的启动与词汇化过程
手势的发起标志着说话者进入了词汇化过程,这个过程包括从思维到语言形式的转换。手势的出现可以看作是说话者在寻找恰当的词汇表达自己的思想时的一个外在指标。
6.4.4 手势持续时间的变异性
手势的持续时间与词汇搜索的长度有关。这意味着,当说话者在寻找合适的词汇进行表达时,伴随的手势可能持续的时间更长。这种变异性反映了词汇搜索过程的复杂性和个体之间的差异。
这些观点强调了手势在语言产生和认知处理中的重要作用。手势不仅是与言语并行的信息渠道,而且在帮助说话者进行思维到语言的转换过程中起到关键的辅助作用。通过研究手势和言语的交互作用,我们可以更深入地理解人类语言和认知的复杂性。
7. 语言的感知(1.2.6中提到)
在语言感知过程中,当感官(如眼睛、耳朵、手指)接收到信号时,接收者必须经历几个步骤:首先识别这些信号为语言信号,然后判断这是他们能理解的语言,最后寻找这些信号的意义。人类对语言有特殊的感知机制,包括大脑半球的专门化分工,其中左半球主要负责语言处理,这种现象在语言的感知和理解中尤为明显。
7.1 大脑半球的专门化
研究表明,人类的大脑半球对于处理不同类型的信息有着专门化的功能。语言处理主要由大脑的左半球负责,这种分工是人类语言感知特化的一部分。
7.2 右耳优势(REA)
右耳优势是指人们倾向于使用右耳接收和处理语言信息的现象。这是因为大脑的左半球负责语言处理,而从右耳接收到的声音信号直接传送到左半球。REA在词汇层面尤为明显,表明在理解单词和词汇时,右耳和左半球的协作对于语言的处理尤为重要。
7.3 启动效应
启动是一种心理学现象,指通过一个与目标刺激相关的刺激来预处理目标刺激,从而影响个体对目标刺激的反应。在语言感知中,通过相关刺激的启动可以减弱右耳优势。这意味着,如果先给出与目标词汇相关的刺激,可以增加左耳(因而是大脑右半球)处理语言信息的能力,从而在一定程度上平衡两耳对语言信息的处理能力。
人类对语言的感知不仅仅是一个简单的物理过程,而是涉及到复杂的大脑功能和心理机制。大脑半球的专门化、右耳优势以及启动效应等现象展示了人类大脑在处理语言信息时的特殊能力和策略。这些机制确保了人类能高效、准确地感知和理解语言信息。
7.4 多种感知信息
语言感知的机制,包括视觉和听觉输入如何处理语言信息,以及人类如何通过多种感知信息理解语言。
7.4.1 视觉输入
视觉输入涉及对字形(graphemes)、字形特征、单词形状的处理。这意味着在阅读时,我们不仅识别单个字母或符号,而且还识别它们的组合方式、形状和排列,以理解单词和句子的意义。例如,我们可以通过单词的外形迅速识别出单词,即使其中的一些字母模糊不清。
7.4.2 听觉输入
听觉输入处理音素(phonemes)、音位特征、语调(prosody)等。这说明我们在听人说话时,不仅识别出不同的声音单元和它们的变化(如音高、强度、节奏),还能通过这些特征理解语言的意图和情感。
7.4.3 输入的可变性
输入的可变性表明我们接收的语言信号可能会因环境、说话者的特点等因素而有所不同。因应这种可变性,我们的记忆系统能够存储给定语言单位的多种表示形式及其相关的元数据,以便更好地理解和处理不同的语言输入。
7.4.4 语音的频率范围
人类语音的频率范围大约在600 Hz到4 kHz之间,这个信息有助于我们理解人类听觉系统对于语言信号的敏感范围。
7.4.5 区分语言和非语言信号
人类的感知系统能够区分语言信号和非语言信号,这使我们能够在复杂的听觉环境中专注于语言信息,忽略背景噪音等非语言因素。
7.4.6 音素恢复效应
音素恢复效应是指我们利用各种线索(包括听觉和视觉线索)来补全听不清或看不见的语音。例如,即使在嘈杂的环境中,我们也能通过上下文或读唇等方式理解对方的话。
7.4.7 视觉线索在语音理解中的作用
除了听觉线索外,视觉线索(如读唇、McGurk效应)也对语音理解至关重要。McGurk效应展示了听觉和视觉信息如何相互作用,影响我们对语音的感知。例如,视觉信息可以改变我们对听觉信息的解读,如一个看起来像是发出/b/音的动作,如果伴随着一阵气流(通常与/p/音相关),可能会被感知为/p/音。
这些机制共同工作,使我们能够在多变的环境中有效地理解和处理语言信息,展示了人类对语言的复杂和高度适应性的感知能力。
7.5 语言感知中的现象
这段文字探讨了语言感知中的几个有趣现象,说明了人类大脑如何以灵活和效率的方式处理语言信息。
7.5.1 信号的连续性
在语言感知中,信号的连续性非常重要。这意味着人类大脑能够从连续的语言流中提取信息,即使在信息中断或信号不完整的情况下也能理解语言。
7.5.2 鸡尾酒会效应
这是一种注意力分配现象,当我们被指示专注于一侧耳机的声音时,如果声音从左耳机转到右耳机或反之,则倾向于继续在转向的耳机上听到声音。这表明我们的注意力可以被特定的语言信号引导,即使在多个信号同时存在的环境中。
7.5.3 剑桥大学的研究现象
这个例子说明了字母顺序对于单词识别的重要性不如我们想象的那么大。只要单词的首尾字母正确,中间的字母即使顺序颠倒,我们也能理解单词的意思。这反映了人类大脑处理语言信息的灵活性和上下文依赖性。
7.5.4 词汇优越效应
这个效应指出,当字母出现在单词中时,比出现在非词(即没有意义的字母组合)中时更容易被识别。这说明了上下文对于语言感知的重要性,以及单词作为一个整体相对于单个字母或音素的优势。
这些现象共同揭示了人类大脑处理语言的复杂机制,包括对信号的灵活解读、在复杂背景下的注意力分配、对单词结构的高效处理,以及上下文在语言理解中的核心作用。这些能力使得人类能够在多变和嘈杂的环境中有效地沟通和理解语言。
7.6 视觉信息处理的步骤以及词汇识别所需的时间
7.6.1 初始视觉分析
这是感知语言的第一步,涉及对视觉输入(如文字和字符)的初步分析。在这一阶段,信息被捕捉并转化为某种可以进一步处理的形式。
7.6.2 输入转移到缓冲区
经过初步分析的信息随后被转移到一个缓冲区,这个缓冲区可能是指视觉信息的短暂存储,为进一步的处理做准备。
7.6.3 在工作记忆中进一步分析
信息从缓冲区转移到工作记忆后,进行更深入的分析。工作记忆是一个活跃处理信息的阶段,涉及对词汇、句法等语言成分的识别和理解。
7.6.4 与文本的语言和认知解释整合
分析后的输入被与已有的语言知识和认知框架整合,以对文本进行理解。这一步骤是语言感知过程中的高级阶段,涉及对信息的全面解释和融合。
7.6.5 词汇识别所需时间
人们只需要大约50毫秒就能识别出一个词汇,但在阅读过程中,每个词的处理时间大约是250毫秒。这个延迟主要是因为信息从视觉缓冲区转移到工作记忆所需的时间,以及进一步的分析和整合过程。
这一描述揭示了人类在阅读和理解语言时所经历的复杂过程,强调了视觉信息处理、工作记忆的角色,以及语言理解所需的时间。这个过程显示了人类大脑处理语言信息的高效性和复杂性,以及在短时间内完成从视觉感知到认知理解的转换能力。
7.6.5 阅读过程
在阅读过程中,我们的眼睛会进行两种主要的动作:注视和扫视。注视是眼睛停留在某一点上大约250毫秒,这个时候我们主要是在识别文字或信息。扫视是眼睛快速移动到下一个注视点的过程,持续时间大约为10-20毫秒,每次移动大约覆盖8-9个字符。

= 代表我们眼睛注视的点,也就是我们正在集中注意力的地方。
WI 代表“词汇识别”,意味着我们在这个注视点上识别出了单词。
BL 代表“开始字母被识别”,说明我们识别了单词开始的几个字母。
LF 表示“接下来的几个字母的特征可辨”,意味着我们可以辨认出紧跟在已识别字母后面的几个字母的特征。
WL 意味着“可以判断注视点右侧单词的相对长度”,即我们能够判断出眼睛注视点右侧单词的长度。
a.在每个注视点(以“=”标记),我们可以看到“WI”(词汇识别),表示在这个点上读者正在识别整个单词。
b.BL(开始字母被识别)和“LF”(接下来的字母特征可辨)出现在注视点的右侧,这表示读者能够识别注视点开始的几个字母,并对接下来的几个字母有一定的了解。
c.WL(可以判断注视点右侧单词的相对长度)出现在注视点远端的右侧,表示读者能够判断注视点右侧单词的长度。
每一行显示了在不同的注视点进行阅读时,这些处理过程如何被执行。在从左到右的阅读模式中(如英语),我们可以看到注视点主要集中在句子的左侧,而信息处理的范围则延伸到了注视点的右侧。这反映了知觉跨度的不对称性,即我们在注视点右侧能够处理更多的信息,这与英语等从左到右阅读的语言的阅读习惯一致。
总结起来,说明了在静默阅读(即心里阅读,不出声地阅读)时,人们是如何通过注视和扫视来处理文字信息的。这是一个复杂的过程,涉及到对单词的快速识别和对周围文本的感知,以便连贯地阅读下去。
7.7 范畴感知
语言感知中有一个非常有趣的现象叫做“范畴感知”(Categorical perception),这是指我们倾向于将听到的声音归类为特定的范畴X或范畴Y,而不是两者之间的某个连续状态。例如,在听到不完全清晰的声音时,我们通常会根据经验将其归为最接近的语音类别。
有趣的是,婴儿在出生后不久就能展示出范畴感知的能力。研究表明,即使是三个月大的婴儿也能做到这一点。研究者们使用一种叫做 高振幅吸吮 (High Amplitude Sucking, HAS)的技术来测量婴儿的感知能力。具体来说,当婴儿听到一个声音刺激时,它会开始吸吮。如果婴儿认为同样的刺激在重复,它就会感到厌烦,吸吮的力度会减弱;如果刺激发生变化,它则会更加努力地吸吮。
1980年,Ganong提出了一个效应,即 Ganong效应 ,这个效应表明音素类别之间的边界是受到语言信息影响的。例如,在/d/与/t/声音连续体中,对于刺激词/?ask/,我们辨识的边界更倾向于/d/这一端;而对于刺激词/?esk/,辨识的边界则更倾向于/t/这一端。这意味着我们对声音的感知并不是完全客观的,而是会受到我们对语言的知识和预期的影响。
简而言之,我们对声音的分类并不是基于声音本身的物理属性,而是基于我们对声音的心理感知和语言经验,这种感知从婴儿时期就开始形成,并且会受到我们对语言的认知和理解的影响。
8. 口语词汇识别
在口语词汇识别方面,这是我们在母语中的一项令人惊奇的能力。尽管我们大约知道20,000个左右的词汇,但我们几乎可以立即意识到某些词,比如 splundle 或法语中的 trigner ,并不存在。那么,我们是如何识别口语中的单词的呢?
8.1 口语词汇的识别步骤
8.1.1 前词汇分析(Pre-lexical analysis)
在这个阶段,我们识别的是音素(phonemes)而不是整个词汇,以及音素的特征、双音节(diphones)和音节(尤其是重音音节)。我们识别单词的过程并不是一次性直接完成的,而是通过识别单词中的各个音素和音节来逐步进行的。
例如,当我们听到单词 soon 时,即使/n/音还没发出来,我们也能通过/u/音的鼻化特征(nasalization)预测出来。
双音节识别:这是前词汇分析的一部分,是我们如何通过前面的音来预测后面的音。这种预测能力是因为某些音节或音素通常以特定的方式组合。
重音音节:在英语中,90%的实义词(content words)首音节是重音。这是词汇切分策略(metrical segmentation strategy,MSS)的一个基础,MSS认为每当遇到一个重音音节时,就会开始一个新的词汇搜索。这意味着,重音音节在我们识别和理解语言的过程中扮演着关键角色。
通过这些步骤,我们的大脑可以快速有效地识别和处理口语词汇,即使是在词汇流中也能做到。这种能力是语言理解和快速交流的基础,反映了人类语言处理系统的复杂性和高效性。
8.1.2 接触(Contact)
这一步将前词汇分析的输出映射到脑中的心理词典中存储的形式上。研究表明,这一搜索过程是并行的,而不是串行的。这意味着大脑可以同时考虑多个可能的词汇匹配项,而不是一个接一个地检查每个单词。
单词的激活程度会随着它的初始部分越来越多地与心理词典中的条目匹配而上升。这允许部分匹配,也允许从发音错误中恢复过来。例如,即使单词发音不完全正确,我们也可能通过已经识别的部分来猜测整个单词。
8.1.3 选择(Selection)
一旦接触到可能的单词候选,就必须通过某种选择过程在它们之间做出选择。这里有一个独一无二的识别点,也就是唯一性点,在这一点之后单词就被识别出来了。
对于不存在的词(nonwords),应用相同的过程,但会有一个偏离点,即在这一点之后,我们就知道这个词并不存在于我们的心理词典中。当我们听到一个词的开头部分与心理词典中的词汇逐渐匹配时,激活程度会上升,但如果随后的音节与所有已知词汇都不匹配,那么激活程度就会下降,我们会意识到这是一个不存在的词。
这些步骤共同构成了口语词汇识别的复杂过程。在这个过程中,我们的大脑不仅要快速地处理声音信号,还要在数以万计的已知词汇中进行搜索和匹配,最后做出选择。这个过程非常迅速和高效,通常在我们意识到之前就已经完成了。
8.1.4 识别(Recognition)
有时候,单词可以在其唯一性点之前就被识别出来,这通常是由于上下文信息排除了其他的候选词汇。例如,在句子 The poacher was found guilty of tres- 中,即便未完成的词汇 tres- 还没有达到唯一性点,上下文信息已经足以让我们排除掉“tress”和“trestle”这样的其他候选词。
在上下文信息以外,还有其他因素参与到词汇的识别过程中:
语义关系:单词之间的意义联系可能会促进或阻碍某个单词的识别。
频率:我们更容易识别出常见的单词。
最近效应:我们最近听到或使用的单词更容易被识别。
邻域:与目标词汇只有一个音素不同的词汇。
邻域密度:邻近词汇的数量和频率,高邻域密度意味着有许多类似的词汇,这可能会影响识别过程。
一些学者提出,形态分解(morphological decomposition)也是识别过程的一部分。在形态分解中,我们可能会将单词分解为词根和词缀来识别。例如,在阿拉伯语中,由于词汇结构的复杂性,形态分解在词汇识别过程中尤为重要。
研究还表明,单词的识别频率统计不仅仅基于其基本形式,而是基本形式及其变形形式的综合。这意味着我们在识别单词时会考虑到单词的各种变化形态。
这一识别过程涉及到大脑中一个非常复杂的神经网络,它能够迅速地处理大量的信息,并在短时间内做出反应。这就是为什么我们可以在听到部分发音的情况下,通过上下文线索和其他线索迅速识别出一个单词。
8.2 识别单词的机制的两种主流的理论
在口语词汇识别领域,关于我们是如何识别单词的机制,有两种主流的理论:
8.2.1 基于规则的系统(Rule-based system)
这个系统主张我们在识别规则性形式的单词时,比如规则动词的过去式(例如英语中通过添加-ed来构成的过去式),会激活大脑中与规则处理有关的区域。例如,当我们听到一个单词,我们会使用语言规则来解析其可能的不同形态。
8.2.2 完全列举系统(Full-listing system)
这个系统认为我们通过激活与词汇存储有关的大脑区域来识别不规则形式的单词,即这些单词是以其完整形式存储在记忆中的。不规则动词的过去式(比如“go”和“went”)就是在没有明显规则可以应用的情况下识别的。
8.2.3 ERP(事件相关电位)
ERP(事件相关电位)研究表明,当我们处理规则形式的单词时,确实会激活与规则处理相关的脑区,而不规则形式的单词则会激活与词汇存储相关的脑区。
在衍生词的识别上,我们区分透明和不透明的衍生关系。透明的衍生关系意味着词汇之间有清晰的联系,比如“mature”和“maturity”互相促进(prime each other),因为它们有明显的词源关联。而不透明的衍生关系,比如“casual”和“casualty”,则因为它们之间的联系不明显,不会互相促进。
至于词缀,前缀词通常会互相促进,比如“remount”和“dismount”,但是后缀词(如“maturation”和“maturity”)之间的促进作用就要小得多。
所以,当我们考虑是使用基于规则的系统还是完全列举系统时,答案可能是两者都有。在日常语言处理中,我们可能同时使用这两种系统。对于规则性的单词变形,我们可能依赖规则来生成或识别;而对于不规则变形,我们可能依赖于词汇记忆。实际上,语言处理的机制可能比这更为复杂,涉及这两种系统的交互和其他认知过程。
9. 视觉词汇识别
在视觉词汇识别方面,我们是如何识别书面单词的?这个过程有点类似于口语词汇识别,但又有所不同。视觉词汇识别中也存在着所谓的 单词优越效应 (word superiority effect),这里的比较等级是:单词 > 合法非词(legal nonword)> 非法非词(illegal nonword)。
9.1 影响视觉单词识别的因素
单词长度:在3-5个字母符号的范围内,识别速度逐渐加快;在5-8个字母符号的范围内,识别速度基本保持恒定;在8-13个字母符号的范围内,识别速度逐渐减慢。
单词频率效应(Zipf law):这是指常见词汇比罕见词汇更容易被识别。Zipf定律表明,在自然语言中,单词的使用频率与其在频率排名中的位置成反比。
规则性效应:这涉及到音素与字母符号(phoneme ↔ grapheme)之间的对应关系。在像英语这样的语言中,规则性对于单词的识别非常重要。
一致性:我们是否知道其他看起来相似的情况?这可以帮助我们更快地识别单词。
邻域密度:这里的 邻居 是指拼写模式几乎相似的单词,而 密度 是指这些邻居是多是少,以及它们出现的频率。
在进行视觉词汇识别时,我们的大脑会利用这些因素快速地过滤和识别单词。这个过程在我们阅读时是非常迅速和自动化的,大脑中的认知机制能够高效地处理这些视觉信息,使我们能够理解和吸收书面材料。
9.2 视觉词汇识别的两种模型
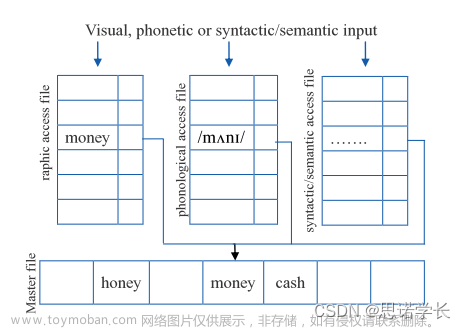
9.2.1 Forster的搜索模型(1976年)
这是一个串行模型,它包含了视觉、音韵、句法和语义输入的并行处理。模型提议在我们阅读单词时,我们的大脑并行处理多种类型的信息。比如当我们看到单词 money 时,我们不仅识别它的视觉形式,还同时处理它的发音、它在句子中的功能以及它的意义。
每个输入列表提供了一个索引的部分。这意味着,当我们阅读时,不同的词汇特征(如视觉特征、音韵特征等)会被存储在不同的索引列表中。当我们尝试识别一个单词时,我们的大脑会在这些列表中进行搜索,以找到匹配的输入。
像是数据库查询。不同输入如何在数据库中被搜索和匹配。例如,当输入是视觉、音韵或句法/语义的,可能会有不同的匹配结果,而且这些结果可能有助于我们识别和理解单词。
9.2.2 交互激活模型(Interactive Activation Model)
9.2.2.1 交互激活模型的特点
这是一个由字母特征、字母、单词(以及语义和句法属性)之间相互作用的图表示的模型。它认为这些不同层次的特征之间不是单向的,而是相互影响的。
在模型中,字母特征是单词识别的基础,它们激活与之相关的字母节点。
字母节点进一步激活单词节点,如果一个字母节点被激活,它会增加使用该字母的所有单词节点的激活状态。
同时,字母节点和单词节点之间的连接有的是兴奋性的(excitatory),有的是抑制性的(inhibitory)。兴奋性连接增强关联节点的激活,而抑制性连接减弱或抑制其他潜在的候选节点的激活。
9.2.2.2 交互激活模型举例
例如,当我们看到字母 C 时,这个字母的特征将激活字母 C 的节点,然后字母 C 的节点将增加 CAT 、 CAR 等单词的激活状态,但同时也可能抑制与 C 不相关的单词的激活。
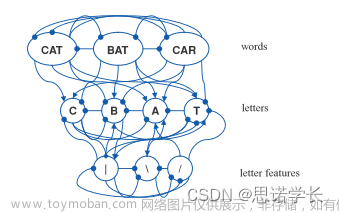
我们可以看到字母特征、字母和单词之间通过线连接。这些线代表不同层次之间的相互作用,其中一些线连接表示兴奋性作用,而另一些表示抑制性作用。
交互激活模型反映了我们在视觉词汇识别过程中,不仅依赖于字母特征和单词的视觉形态,还涉及到字母和单词之间的复杂相互作用。这个模型帮助我们理解了为何单词的识别不仅仅是简单的视觉处理,而是一个涉及多个层次、高度交互的认知过程。
9.2.3 亚声音化
关于视觉词汇识别,特别是在静默阅读(即不大声朗读时的阅读)中是否需要亚声音化(即在大脑中模拟发音过程,也就是虽然不发声,但大脑中仍然经历音素的过程),语言学家们有不同的观点。一些极端的语言学家认为这是必要的,而一些不那么极端的语言学家则认为不必要。
一个有力的效应是伪同音效应(pseudohomophone effect),这是指那些拼写形式类似于真实单词但实际并不存在的单词,比如 blud (如果发音的话,听起来像是一个真实的单词“blood”)。在词汇决策任务中,人们拒绝这些伪同音词的时间比拒绝其他非词汇要长。不过,这一效应是否出现还取决于读者是否曾经接触过这些字母组合:比如“beaf”(类似于“beef”)就能起作用,而“befe”则不行。
这表明在阅读过程中可能存在两条路径:一条是通过字母-音素转换进行的,另一条是直接从单词到发音的。这种发现引发了关于学校应该如何教授阅读的讨论。有的教学方法强调拼读(即通过字母-音素转换),而有的教学方法强调整体识字(即直接识别单词的整体形状和意义)。
这个话题在语言教学和认知科学领域都是一个非常有趣的讨论点,它关系到我们如何理解大脑处理语言的机制,以及我们如何基于这些知识来制定教育策略。
10. 句法句子处理
在句法句子处理中,“解析”(Parsing)一词来源于传统的拉丁语或古希腊语教学,当时的文本会给学生进行语法结构分析(来自拉丁语“pars orationis”,意为“言语的部分”)。
10.1 分句假说
分句假说(The clausal hypothesis):主张句子中的从句是语言理解中的基本分析单位。从句是包含动词的句子部分,可以视为句子的建构块。例如,“We’re going always.” 这个句子结构并不标准,但它包含了一个动词。
有限从句(Finite clauses):具有带有时态和数的标记的动词,比如“John walked”,这里的动词“walked”表明了时态(过去时)和数(单数)。而在 非有限从句(non-finite clauses)中,这样的标记是不可能的,例如“to leave work early”,这里的“to leave”没有标明时态和数。
分句假说是分块处理(chunking process)的一个特例。分块处理是一种记忆策略,通过将信息分成小块来提高记忆效率。比如,记忆分成块的数字“2282 654”比连在一起的“2282654”更容易。在语言理解中,我们的大脑使用分句假说来分块处理句子,这样我们就可以更容易地理解和记忆句子的意义。
10.2 点击定位实验
在句法句子处理的研究中,有一个经典的实验叫做点击定位实验(click location experiment),首次进行于1965年。在这个实验中,参与者看到一些句子的同时听到这些句子被朗读出来,但句子中的某个词会伴随一个点击声。然后参与者被要求在纸上标出他们认为点击声出现的位置。实验观察到,参与者倾向于系统地将点击声放在从句的边界上。
使用眼动追踪技术的研究表明,明确的句法标记可以使语言处理变得更容易。比较以下两句话:
I told Mark the woman I met had red hair(我告诉马克,我遇到的那个女人有红头发)
I told Mark that the woman who I met had red hair(我告诉马克,我遇到的那个女人有红头发)
在第二句中,“that”和“who”作为句法标记,帮助明确了句子的结构,从而使得理解变得更加容易。
另外,语调(prosody)也是帮助理解句子结构的一个重要因素,它可以通过标点符号来标示。比如,逗号和句号可以帮助我们区分句子中的不同成分和停顿,从而理解句子的意义。类似地,诗歌和其他形式的写作中的换行也会影响我们对语言的处理,就像路标一样,告诉我们何时停下来,何时继续前进。这些视觉和听觉上的线索共同帮助我们处理和理解语言。
10.3 句法句子处理
句法句子处理是理解语言的一个重要方面,它涉及如何解析和理解句子结构。在这个过程中,我们的大脑会遇到各种现象和策略:
10.3.1 花园路径现象(Garden Path Phenomenon)
这是一个句法处理的现象,指的是读者或听者在句子理解过程中,最初采取了一个看似合理的解释路径,但随着句子进展,这个解释却变得不可行,于是不得不回溯并重新解析句子。例如, Two sisters reunited after 18 years in checkout queue(两姐妹在结账队伍中18年后重逢)一句,一开始可能会误解为两姐妹在队伍中待了18年,而实际上意思是两姐妹18年后在队伍中重逢。
10.3.2 三种策略
为了使句子处理尽可能简单,我们的大脑使用了多种策略来解析句子。这里介绍三种策略:
10.3.2.1 迟闭策略(Late Closure)
这一策略指的是在解析句子时,我们倾向于将新的信息附加到当前的短语或从句中,而不是创建一个新的短语或从句。例如,在“before the police stopped the driver was getting nervous”这个句子中,我们可能自然而然地将“the driver”看作是“stopped”的宾语,因为我们倾向于将信息加到最近的短语中。
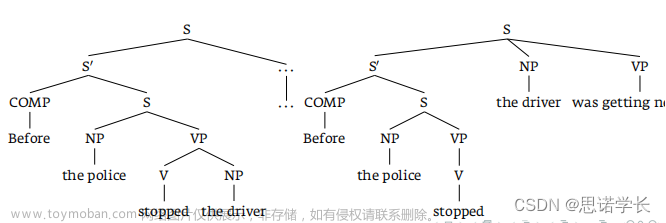
10.3.2 最小附加策略(Minimal Attachment)
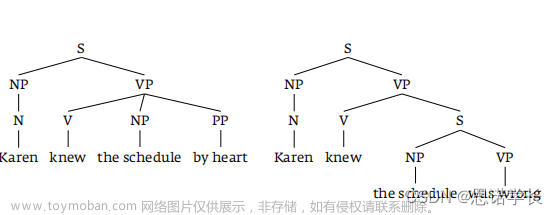
这一策略指的是在解析句子时,我们的大脑尽可能以最少的句法结构去解释句子。例如,在Karen knew the schedule by heart 这个句子中,当我们读到“the schedule”时,我们倾向于将其解释为直接宾语,因此“by heart”就被解释为动词短语的一个介词短语(PP)。如果后面出现“was wrong”,那么我们需要添加一个额外的节点来形成一个从句结构。
10.3.3 右关联策略(Right Association)
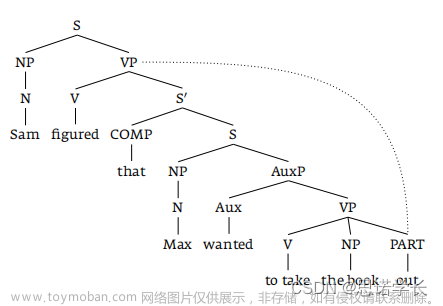
这一策略指的是在解析句子时,我们倾向于将新的信息附加到最右侧的结构。在“Sam figured that Max wanted to take the book out”这个句子中,当需要附加“out”这个词时,我们会将其附加到最右边的动词短语“to take the book”上。
这些策略帮助我们以最简单的方式解析句子,降低了理解复杂句子结构的认知负担。通过这些策略,我们能够更加迅速和准确地理解句子的意义。
这些策略和现象表明,句法解析是一个动态的过程,我们的大脑在处理语言时需要不断地调整和修正。为了最大限度地减少处理的复杂性和避免误解,我们的大脑发展出了各种策略来简化这个过程。这些策略有助于我们在阅读或听语言时迅速而准确地理解句子的意义。
10.4 不同语言之间的差异
在处理包含关系从句的句子时,例如“The journalist interviewed the daughter of the colonel who had had the accident”,不同语言的说话者可能会根据他们的语言习惯将关系从句连接到不同的名词短语(NP)上。
在英语、瑞典语、挪威语、罗马尼亚语和阿拉伯语中,人们倾向于将关系从句“who had had the accident”连接到距离它更近的第二个名词短语“the daughter of the colonel”上,意思是事故发生于上校的女儿。
而在法语、德语、荷兰语、希腊语中,关系从句通常会连接到第一个名词短语上,如法语中的“Le journaliste a interviewé la fille du colonel qui a eu l’accident”(记者采访了发生事故的上校的女儿),这里的“qui a eu l’accident”被理解为修饰“le colonel”。
这种差异可能是由两种竞争的解析策略导致的:
邻近原则(Regency Principle):这个原则指的是将新信息连接到最近的可能点。在上面的例子中,英语和其他一些语言的说话者会将关系从句连接到离它最近的名词上,即上校的女儿。
谓词接近原则(Predicate Proximity):这个原则指的是将从句连接到主句动词最近的名词。在其他一些语言中,如法语,这个原则可能会导致关系从句修饰第一个名词,即记者。
不同语言的语法和句法习惯可能影响这些原则的应用,从而导致关系从句的不同解析。这些差异体现了语言处理中的多样性和复杂性,以及在跨语言理解时可能遇到的困难。
10.5 理解上的困难
这句著名的句子“Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo”是一个语法上正确的句子,但是由于其复杂性,很多人在第一次读到它时会感到困惑。这句话利用了英语中的同音词和同形词的特性,包括地名“Buffalo”(美国纽约州的一个城市)、动物“buffalo”(水牛或美洲野牛),以及动词“to buffalo”(欺骗或恐吓)。
这句子可以被解释为:“来自Buffalo的那些水牛被其他来自Buffalo的水牛所恐吓,而这些恐吓它们的水牛也同样来自Buffalo。”这里,“Buffalo buffalo”是指来自Buffalo城的水牛,“Buffalo buffalo buffalo”是指来自Buffalo的水牛恐吓其他水牛,而整个句子表达的是这样一个意思:那些被Buffalo的水牛恐吓的Buffalo水牛,也去恐吓其他的Buffalo水牛。

您提供的另一句话“Red foxes black dogs chase eat yellow apples”同样具有语法上的歧义,因为它缺少了连接词和逗号来区分子句。正确的句子结构可能是“Red foxes, which black dogs chase, eat yellow apples”(被黑狗追赶的红狐狸吃黄苹果)。
这个例子展示了在句法句子处理中,缺乏明确的句法标记(如逗号、连接词)会如何导致理解上的困难,以及如何需要依赖于上下文和语法知识来解析句子的意思。
11. 解释句子
11.1 解释句子的研究
在解释句子时,早期的研究(1966年)探讨了可逆句子(例如“The chicken saw the horse”)和不可逆句子(例如“The girl felt hope”)的阅读时间,以及它们被动语态形式的处理时间。这些研究显示,不可逆句子由于其语义关系明确,通常比可逆句子更易于处理。在被动句子中,这种效应可能会更加显著,因为被动语态的使用可能会增加处理语句所需的时间。
诺姆·乔姆斯基(Noam Chomsky)在1957年提出了一个在句法上没有问题但在语义上却无意义的句子: Colorless green ideas sleep furiously(无色的绿色想法狂怒地睡觉)。这个例子用来说明语法结构的独立性和语义内容的区别。
对句子的解释通常遵循以下步骤:
a.首先对句子进行句法处理:大脑首先根据语法规则解析句子结构,不考虑语义内容。
b.保留一个首选结构:即使在遇到多种可能的句法结构时,大脑也会倾向于选择其中的一个作为首选解释。
c.通过独立的主题处理器生成语义解释:一旦句法结构确定,大脑会尝试赋予句子一个语义内容,这个过程是独立的。
d.然后可能回到替代结构来测试其语义解释是否更为合理:如果首选的语义解释不符合逻辑或不合理,大脑会重新考虑句法结构,尝试找到一个更合理的解释。这一步在处理花园路径句子时尤为重要,因为这类句子最初的句法解释往往会误导解释者,使其需要重新解析句子以得到正确的语义。
这个过程反映了我们的大脑在处理语言时是多么复杂和灵活,既能快速遵循句法规则,也能适应性地重新解析句子以寻求更佳的语义理解。
11.2 限制性从句与非限制性从句
在解释句子时,区分限制性从句(restrictive relatives)和非限制性从句(non-restrictive relatives)是非常重要的,因为它们对句子的意义有着根本的影响。
非限制性从句:这类从句提供了额外的信息,但并不限定主句中提到的名词。例如,“Women, who can multi-task, are good at it”(能够多任务处理的女性在这方面很擅长),这里的从句 who can multi-task 是非限制性的,它表明所有女性都能多任务处理,这是一个额外的信息,而不是对“Women”这个群体的限定。
限制性从句:这类从句限定或指定了主句中的名词。例如,“Men who can multi-task are good at it”(能够多任务处理的男性在这方面很擅长),这里的从句“who can multi-task”是限制性的,它限定了特定的一群男性,即那些能多任务处理的男性。
简化限制性从句(Reduced restrictives):这种从句形式去掉了一些词,使句子更简洁。例如,The horse raced past the barn fell(赛马过谷仓后摔倒了)。这个句子的意思是,在一群马中,那匹被赛过谷仓的马摔倒了。
与非限制性从句相同:如果我们用非限制性从句来重新表达上面的例子,The horse, which was raced past the barn, fell(那匹赛过谷仓的马摔倒了),意思相似,但这种表达方式清楚地表明只有一匹马,而且它赛过谷仓后摔倒了。
根据Crain和Steedman的指称假设(Referential Hypothesis),当我们读到简化的限制性从句时,我们假设有一组特定的对象(例如马),而我们正在讨论其中的一个。而在非限制性从句的情况下,指代的是唯一的对象。因此,我们倾向于选择更简单的解决方案,并首先考虑 raced 作为一个过去时态的动词。这种偏好影响了我们对句子的解释,显示了在解析句子时,我们如何利用语法和上下文线索来导向语义的理解。
11.3 词汇偏好和名词的活性
在解释句子时,构建句法结构通常仅依赖于每个单词的词性。然而,实际上存在词汇偏好,这会影响我们对句子的理解和处理速度。
11.3.1 词汇偏好
词汇偏好指的是某些动词倾向于接受特定类型的宾语。例如:
一些动词更倾向于接受名词短语(NP)作为宾语,如 hear (听见)、see(看见)、“read”(读)、“answer”(回答)等。这些动词通常与直接的、具体的对象相关联。
另一些动词则更倾向于接受从句作为宾语,如“claim”(声称)、“know”(知道)、“doubt”(怀疑)、“believe”(相信)等。这类动词与表达观点、知识或信念的抽象内容相关。
这种词汇偏好会影响阅读时间,因为它决定了读者在处理句子时需要考虑的可能结构的复杂性。对于直接接受名词短语的动词,句子的结构相对简单,可能更容易快速理解。而需要接受从句作为宾语的动词,句子结构更复杂,理解和处理可能需要更多时间。
11.3.2 名词的活性(animosity)
名词的活性(animosity)也是一个重要因素。例如,The defendant/archeologist examined…与“he evidence/fossil examined…的句子。前者中的名词(defendant、archeologist)具有较高的活性,暗示这些名词所指的实体具有能动性,即它们能够执行动作。而后者中的名词(evidence、fossil)则暗示所指的实体是被动的,是动作的接受者。这种区分影响我们对句子主谓关系的理解,从而影响句子的解释。
综上所述,词汇偏好和名词的活性是影响句子理解的重要因素,它们决定了我们如何构建句子的句法结构,以及如何解释句子中的动作和事件。
11.4 韵律
在解释句子时,韵律(即句子的语音节奏和抑扬顿挫)也是一个重要的因素,特别是在区分像 The lawyer heard the tape and gave his opinion 和 The lawyer heard the tape was unreliable 这样的句子时。这两个句子在书面形式中可能看起来相似,但在口语中,通过韵律的变化,可以清晰地区分两种不同的含义。
关于韵律是否从一开始就影响句子处理,还是仅在后感知分析(post-perceptual analysis)中起作用,学界有不同的观点:
无限制账户论者(Unrestricted accountists)认为,在最早的阶段,所有类型的信息(包括韵律信息)都被使用。这意味着从句子处理的一开始,韵律就是影响理解的一个因素。
弱互动账户论者(Weak interactive accountists)认为,语法和其他信息源之间的互动仅在语法分析需要时发生。按照这个观点,韵律信息可能不会在句子处理的最初阶段起作用,但在需要解决歧义或进行深入理解时,它会与语法分析相互作用。
强互动账户论者(Strong interactive accountists)认为,非语法信息源(如韵律)在句子处理中起决定性作用。这意味着,韵律和其他非语法因素从一开始就影响着句子的理解和解释。
基于约束的账户论者(Constraint-based accountists)假设采用并行处理方法,其中多个备选分析相互竞争。在这种视角下,韵律信息与语法、语义等其他信息一同影响句子的初步理解和最终解释。
综合这些观点,可以看出,韵律在句子处理中的作用可能取决于处理策略和个体对不同信息类型的利用方式。韵律信息可能在句子理解的早期阶段就开始发挥作用,特别是在需要解决句子结构歧义或强化语言意图时。
11.5 两个重要的模型
在解释含糊不清的句子时,心理语言学领域提出了几种模型来解释我们的大脑是如何处理这些句子的。其中两个重要的模型是“未注册赛模型(unregistered race model)”和“足够好模型(good-enough model)”。
11.5.1 未注册赛模型(Unregistered Race Model)
这个模型提出,当遇到一个含糊不清的句子时,不同的解析可能会参与到一场赛跑中,最先完成解析的解释被选为胜者。这意味着,我们的大脑会同时启动多个可能的句子解析路径,而最快达到一个可行解释的路径会被选为我们对句子的最终理解。这个模型强调了解析速度的重要性,表明在很多情况下,我们的大脑倾向于采用第一个达到的、足够合理的解释。
11.5.2 足够好模型(Good-Enough Model)
这个模型类似于第二语言处理中的情况,提出我们在解析句子时,并不总是寻求最完美、最精确的解释。相反,我们可能会满足于一个 足够好 的解释,尤其是在句子结构复杂或信息量大时。这个模型强调,为了效率和实用性,我们的大脑可能会接受一个近似正确但可能不完全精确的解释。这种策略在处理语言时能够节省认知资源,特别是在理解第二语言或面对复杂语言结构时尤为重要。
这两个模型都强调了在语言处理中,速度和效率的重要性,以及我们的大脑如何在追求理解精确度和节省处理资源之间寻求平衡。它们提供了有关我们如何处理和解释含糊不清句子的有力见解。
12. 建立关系
我们建立句内或句间关系的能力是理解和处理语言的核心部分。这种能力不仅涉及到将句子中的信息与已知信息相结合,还包括从所听或所读的内容中推断出额外的信息。
早期的研究显示,听众能够整合他们所听到的信息。例如,1971年的一项研究展示了以下句子:
1. 蚂蚁在厨房里。
2. 蚂蚁吃了甜果冻。
3. 果冻放在桌子上。
在听到这三个句子后,许多参与者报告说他们听到了第四句话,即:厨房里的蚂蚁吃了放在桌子上的甜果冻。尽管第四句话并未直接给出,听众通过整合前三个句子中的信息,自然而然地构建了一个更完整的场景描述。
此外,1972年的研究表明,我们能够从所听到的内容中推导出额外的信息。这种推理能力使我们能够超越文字表面的含义,理解隐含的信息或语境下的含义。例如,如果某人说“我去了图书馆后就直接回家了”,我们可能会推断这个人借了一些书,尽管这并没有直接被提及。
这些能力说明了我们在处理语言时的一些基本策略:
信息整合:我们能够将不同句子或信息片段中的信息融合成一个连贯的整体。
推理:我们能够基于所给的信息,推导出未明确表达的额外信息,这有助于我们更全面地理解语境和意图。
这些策略在日常交流中至关重要,它们使我们能够在复杂的语言环境中有效地理解和交流。
12.1 连贯性与衔接性
当我们阅读或倾听时,我们构建了一个心理模型来理解和解释信息。这个心理模型基于文本的连贯性(coherence)和衔接性(cohesion),这两个方面对于理解大段文本至关重要。
连贯性指的是句子如何彼此关联,形成一个统一的整体。连贯性涉及到文本的内容和逻辑结构,确保读者能够理解不同句子之间的关系和整个故事或论点的流程。
衔接性涉及到文本中元素之间的文本链接,如代词(例如“他”、“她”)、连接词(例如“因此”、“然而”)和指示词(例如“这个”、“那个”)。衔接性帮助读者追踪不同部分之间的关系,理解文本中不同部分是如何连接在一起的。
您提供的例子展示了变化连贯性如何影响理解:
在第二个例子中,由于“捡到一些钱”与“跳过峡谷”之间的活动通常不相关联,因此确定“他”指的是“Henry”需要更长时间。这表明,当后续事件与先前事件之间的逻辑联系不强时,理解代词指代(如“he”指“Henry”)会变得更加困难。这种情况下的连贯性较低,因为读者需要花费额外的认知资源来建立事件之间的联系。
这个例子强调了文本连贯性和衔接性在理解和解释信息时的重要性,以及读者如何依赖这些属性来构建心理模型,使得理解过程更加流畅和高效。
12.2 代词回指
在建立句子或文本之间的联系时,代词回指(anaphora)是一个常见的现象,其中一个词或短语指回文中先前提到的某个实体。然而,当回指需要额外的推理来建立联系时,这种代词回指被称为桥接代词回指(bridging anaphora)。这种情况下,理解第二句话通常需要更长的时间,因为读者需要利用额外的信息或通用知识来建立两个句子之间的联系。
您提供的例子很好地说明了这一点:
在第一个例子中,"啤酒"被直接提及,因此理解"啤酒是温的"相对容易。而在第二个例子中,"啤酒"没有直接被提及,而是隐含在"野餐用品"之中,因此需要读者进行额外的推理,从"野餐用品"中桥接到"啤酒",这增加了处理时间。
关于实例与类别的代词回指解决速度的差异:
(1) A shark has been swimming close to shore. By evening the shark had gone.
(2) A fish has been swimming close to shore. By evening the fish had gone.
1. 一条鲨鱼一直在靠近岸边游泳。到了晚上,鱼已经走了。
2. 一条鱼一直在靠近岸边游泳。到了晚上,鲨鱼已经走了。
在第一个例子中,"鲨鱼"作为一个具体的实例被提及,使得"鲨鱼已经走了"容易被追踪和理解。而在第二个例子中,"鱼"作为一个更广泛的类别,其指代可能包含更多种类的鱼,因此解决"鱼已经走了"的回指可能需要更多时间来确认具体指的是哪一种鱼。
在建立文本之间的联系时,句子的处理速度也受到句子构成元素之间的语义关系的影响。如你所示的例子,说明了这一点:第一个例子比第二个例子更容易处理,因为“鱼”可以被看作是“鲨鱼”的一个泛化类别,而从“鱼”转换到“鲨鱼”则需要一个更大的语义跳跃。然而,当动词与主语之间有强烈的语义关联时,这两个句子的处理速度相同:
(1) A shark attacked the swimmer. By evening the fish had gone.
(2) A fish attacked the swimmer. By evening the shark had gone.
1. 一条鲨鱼攻击了游泳者。到了晚上,鱼已经走了。
2. 一条鱼攻击了游泳者。到了晚上,鲨鱼已经走了。
在这种情况下,由于“攻击”这个动作与“鲨鱼”和“鱼”都有强烈的语义关联(尽管通常我们会更多地将“鲨鱼”与“攻击”联系起来),因此两个句子可以以相同的速度处理。
此外,提及一个词语的首次与后续出现之间存在韵律差异(如重音),这对于指代消解和信息处理也很重要。首次提及通常需要更多的韵律突出以引入新的概念或实体,而后续提及则可以通过较少的韵律强调进行,因为听者或读者已经对该概念或实体有所了解。
这些观察结果强调了在语言处理中,句子元素之间的语义关系、代词回指的使用以及语言的韵律特征是如何交织在一起,共同影响我们对信息的理解和处理速度。
这些例子展示了在语言理解过程中,如何依靠文本信息和背景知识来建立句子之间的联系,以及这些不同类型的代词回指如何影响理解和处理速度。
13 语言处理系统的架构
语言处理系统的架构是否是模块化的,是认知科学和心理语言学领域内长期讨论的话题。这个讨论涉及到我们大脑如何组织和处理语言信息的基本方式。
13.1 模块论者(Modularists)
模块论者认为语言处理是模块化的。这意味着大脑中存在专门负责语言处理的独立模块,每个模块处理特定类型的信息并执行特定的功能。这些模块可以独立于其他模块工作,不受其他认知过程的干扰。模块化的特点包括:
信息封装:每个模块都有特定的输入和输出,它们处理特定类型的信息,并不直接受到其他模块信息的影响。
自动性:一旦一个模块接收到输入,它就会自动地生成输出。这个过程不需要意识控制,是快速和自动的。
13.2 非模块论者(Non-modularists)
非模块论者则认为语言处理不完全是模块化的。他们认为,不同的语言处理部分之间存在交互,来自一个部分的知识和信息可以提高其他部分的效率。这种观点强调了语言处理的整体性和上下文依赖性,认为语言理解涉及到广泛的认知资源和多种信息的综合处理。
13.3 斯特鲁普效应(Stroop Effect)的启示
斯特鲁普效应是一个展示自动性的经典例子,当测试中 GREEN 这个词以红色呈现时,尽管任务是识别字体颜色,人们仍然会自动识别单词的语义内容(即“绿色”),这会干扰到颜色识别的任务。这种效应暗示了某些认知过程的自动性,支持模块化理论中关于模块自动处理输入的观点。
13.4 结论
关于语言处理是否模块化,目前还没有一个统一的答案。不同的理论和研究结果支持不同的观点。模块化理论强调了认知过程的专业化和自动性,而非模块化理论强调了认知过程的整体性和相互依赖性。实际上,语言处理可能同时包含模块化和非模块化的元素,不同的任务和条件下,这两种机制可能各自发挥作用。
13.5 句法和语义信息独立性的证据
大脑损伤患者提供了句法和语义信息独立性的证据,尤其是在布洛卡失语症(Broca's aphasia)和韦尼克失语症(Wernicke's aphasia)患者中的表现。
13.5.1 布洛卡失语症(Broca's Aphasia)
布洛卡失语症患者的特点是语言表达困难,尤其是在句子构造上。这些患者往往会产生语法错误,比如词序错乱,这主要影响到句法结构(句法轴)。这表明句法处理能力受损,但患者往往在理解语言的基本意义上仍然保持相对完好,显示出句法和语义信息处理的独立性。
13.5.2 韦尼克失语症(Wernicke's Aphasia)
与布洛卡失语症相反,韦尼克失语症患者主要表现为语义理解障碍。这些患者可能会流畅地产生语言,但语言内容缺乏意义,或使用了不恰当的词汇和短语,这主要影响到语义选择(范畴轴)。这种类型的失语症显示了患者在产生语义相关的内容时存在困难,而句法结构可能相对保留。
13.5.3 句法和语义信息的大脑定位
研究还发现,功能词(如介词、冠词等,主要承担句法功能)在大脑的处理中主要定位于左半球的句法区域,而内容词(如名词、动词等,承载主要的语义信息)的处理则涉及到右半球的区域。这种分布进一步支持了句法和语义信息处理在大脑中的独立性和专门化。
这些观察结果表明,句法和语义信息在语言处理系统中被相对独立地处理,而特定类型的大脑损伤可以独立地影响这两种能力。这为理解语言处理的模块化提供了支持,显示了大脑在处理语言时如何分工协作,以及不同语言组成部分如何在大脑中有不同的神经基础。
13.6 语言处理系统模型
13.6.1 简化模型
提出了一个关于语言处理的简化模型,以解释听觉和语言产出如何结合在一起。模型分为几个阶段:
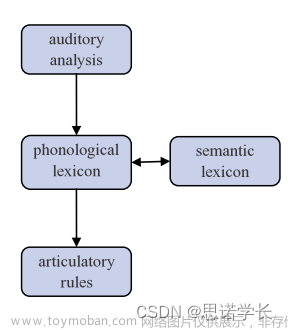
听觉分析(Auditory Analysis):这是处理听到的语言的第一步。它涉及到解析声音的物理属性,如频率和振幅。
语音词汇(Phonological Lexicon):在这一步,解析后的声音被映射到我们所知道的语音模式上,这些模式储存在我们的语音词汇库中。
语义词汇(Semantic Lexicon):在识别了语音模式之后,模型展示了从语音词汇到语义词汇的连接。这意味着我们开始理解单词和短语的意义。
发声规则(Articulatory Rules):这涉及到语言产出的过程。一旦一个词在语音词汇中被识别,就会使用发声规则来生成说话的动作。
大脑成像研究表明,当听或说单词时,大脑中的不同区域会被激活。此外,理解和产出口语单词之间存在重叠,因为当我们刚听到一个与之音韵相关的词时,产出一个词会变得更容易。
这个模型虽然简化,但提供了一个起点,帮助我们理解复杂的语言处理过程。它强调了理解和产出过程之间的交互作用,并暗示了这些过程可能共享某些神经结构。这种模型有助于解释为什么我们能够迅速回应我们所听到的言语,以及这个过程是如何高效地被大脑执行的。
13.6.2 关注失名症语言处理的模型
一个关于语言处理的模型,特别关注了失名症(anomia)患者的病理情况。失名症是一种神经病理状况,患者在寻找命名物体的词汇时遇到困难,但他们能够理解其他人说的这些词。
失名症患者在找到命名对象的词汇时存在困难,但能够理解当别人说出这些词汇时的含义。
这表明存在两种词汇系统:一种用于输入(可能是音素),另一种用于输出(可能是音节)。
新的模型考虑到了这一点,区分了语音输入词汇和语音输出词汇。
失名症患者的损伤可能位于从语义词汇到语音输出词汇的输出路径上。
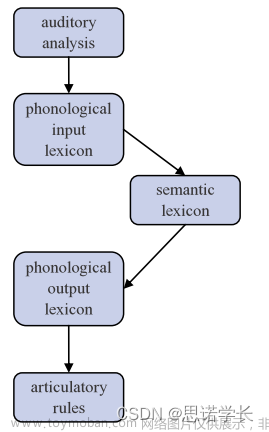
模型包含以下部分:
听觉分析(Auditory Analysis):处理听到的声音,识别语言的声学特征。
语音输入词汇(Phonological Input Lexicon):储存听到的词汇的音素形式,协助理解语言。
语义词汇(Semantic Lexicon):包含词汇的意义,是理解和产出语言的中心环节。
语音输出词汇(Phonological Output Lexicon):储存用于说话的词汇的音素形式。
发声规则(Articulatory Rules):指导如何将语音输出词汇转化为口头语言的实际发声。
根据这个模型,一个可能的解释是,失名症患者的障碍可能发生在从语义词汇到语音输出词汇的转换过程中。即使他们能够理解词汇的含义,但他们在尝试说出这个词时遇到难题,因为这需要从语义存储转换到合适的语音形式,这一转换过程可能受损。
这个模型强调了语言理解和产出之间的区别,以及语言处理中各个组成部分如何相互作用。通过了解这些不同的语言处理阶段,我们可以更好地理解失名症等语言障碍的潜在机制。
13.6.3 关注失名症语言处理的模型
一个更复杂的语言处理模型,并讨论了“词盲症”(word deafness)患者的情况。词盲症是一种罕见的疾病,患者能够阅读和写作,但无法理解或重复他人对他们说的话。
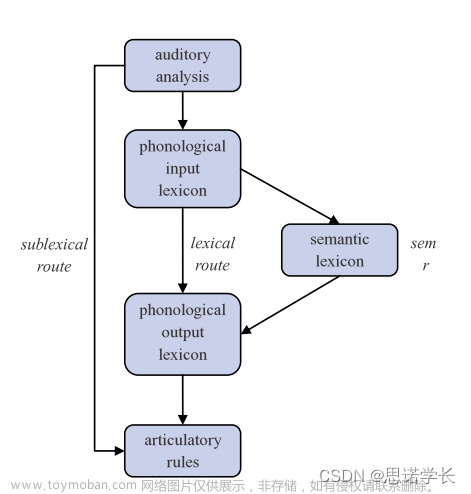
听觉分析(Auditory Analysis):这是语言处理的第一步,涉及到声音信号的分析。
语音输入词汇(Phonological Input Lexicon):这里存储了我们听到的词的音素模式,帮助我们理解语言的声音部分。
语义词汇(Semantic Lexicon):这是存储单词意义的部分,关键于理解语言的含义。
语音输出词汇(Phonological Output Lexicon):这里存储了用于产生语言的词的音素模式。
发声规则(Articulatory Rules):这部分指导如何将语音输出词汇转化为实际的口头语言。
还提出了三条不同的路线:
次词素路线(Sublexical Route):用于重复非词语素(如“krkzb”),这涉及到声音的直接模仿,而不需要理解这些声音的意义。
词汇路线(Lexical Route):用于重复和识别词汇,即使这些词汇的意义没有被理解(如“desummation”)。
语义路线(Semantic Route):包括理解单词的含义。
词盲症患者的情况表明,尽管听觉分析和发声规则可能保持完好,但语音输入词汇到语义词汇的路线可能受到了损害。这可能导致患者在听到话语时无法理解其含义,尽管他们能够阅读和写作,这表明了语言理解和产出在神经机制上的不同路径。这样的模型有助于我们理解语言处理的多模块性,以及不同模块在语言理解和产出中的作用。
上传的幻灯片探讨了语言处理系统的结构,并且说明了当这个系统的不同部分受损时可能导致的各种语言障碍。幻灯片描述了几个组成部分:听觉分析、语音输入词汇库、语义词汇库、语音输出词汇库和发声规则。
13.6.3.1 三种不同类型的病例
不能重复非词汇但能理解和重复真实单词的患者。这表明左侧路径可能受损,这条路径负责处理新的音位模式,这些模式并不储存在语音输入词汇库中,但在重复非词汇时需要用到。
可以重复非词汇和单词但不理解它们的患者。这表明右侧路径受损,其中从语音输入词汇库到语义词汇库的路径出现了问题,影响了单词的理解。
不能重复非词汇,可以重复单词,但不理解它们的患者。这种情况暗示左侧和右侧路径都受损,只有中央路径完好无损。这些患者可能完全依赖于语音输入词汇库和语音输出词汇库之间的直接连接,绕过了语义理解。
这个模型表明,语言处理系统涉及多条路径,不同类型的语言信息在其中并行处理。它还指出,某些路径专门负责语言的某些方面,例如重复已知单词或生成新的单词形式。理解这些路径及其相互作用可以帮助我们深入了解大脑中的语言处理方式,以及如何因特定的语言网络部分受损而产生不同的语言障碍。
13.6.4 更复杂架构
语言处理模型及其与特定语言障碍患者的关联。模型展示了语言处理的不同组件及其相互作用,包括听觉分析、语音输入词汇库、语义词汇库、语音输出词汇库、书写识别、正字形输入词汇库、正字形输出词汇库、发声规则和字母到声音的规则。
13.6.4.1 症状
有些患者在被展示辣椒时会说“朝鲜蓟”(artichoke),但写出“番茄”(tomato)。这可能表明他们在视觉和语音信息之间的联系方面存在障碍。
其他患者能够给出物体的书面名称,但不能口头表达。这可能意味着他们的语音产出受损,但书写能力保持完好。
还有患者可以书写下他们既不理解定义也不会发音的单词。这表明他们可以在视觉识别和手动书写方面进行语言处理,但语义理解受损。
有些患者能够根据听写完美书写单词,包括不规则单词,但他们不理解自己所听到的内容。这种情况可能涉及到从听觉到语义理解的路径受损,而听觉到语音输出的路径可能保持完好。
13.6.4.2 模型解读
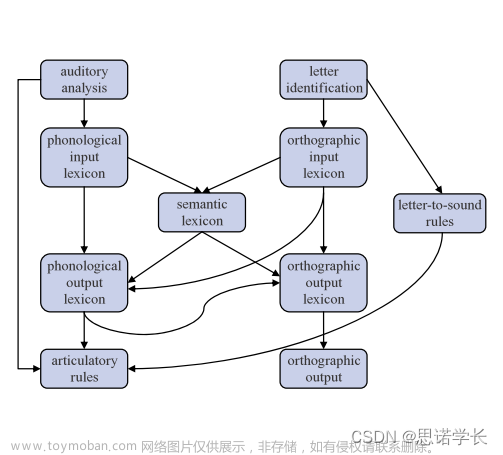
一个用于解释语言处理的模型,并讨论了不同类型的大脑损伤患者的语言障碍情况。我将基于图片中的信息, 解释模型中的各个模块:
听觉分析(Auditory Analysis):这是语言处理的初始阶段,涉及对声音信号的物理特性进行解析,识别不同的语音音素。
语音输入词汇库(Phonological Input Lexicon):在此阶段,解析的声音信号被识别,并与已知的语音模式匹配,这些模式存储在大脑的语音输入词汇库中。
正字形输入词汇库(Orthographic Input Lexicon):这个模块涉及视觉识别字母和单词的形状,将视觉信息转换为可以理解的文字形式。
语义词汇库(Semantic Lexicon):该模块存储单词和短语的意义,是理解和产出语言的核心环节。
语音输出词汇库(Phonological Output Lexicon):此模块负责从语音输入词汇库中提取单词的音素模式,以用于语言产出。
正字形输出词汇库(Orthographic Output Lexicon):在书写过程中,这个模块提供正确的字母和单词形式,以便将其转换为书面文字。
发声规则(Articulatory Rules):这些规则指导如何将语音信息转换为口头语言的实际发声动作。
字母识别(Letter Identification):这涉及到识别书写或打印的字母,是阅读过程的一个部分。
字母到声音的规则(Letter-to-Sound Rules):这套规则将视觉文字形式转换为其对应的语音形式,是阅读过程中将书面语言转换为口头语言的一个重要步骤。
患者表现出了不同程度的语言处理障碍,这揭示了语言处理系统中各个模块的相互依赖和独立性。例如,有些患者可能在听觉分析和语义词汇库之间的连接受损,导致他们听到单词但无法理解其含义,而通过书写他们可以绕过这一障碍,利用视觉信息来理解单词。
这个模型强调了语言处理是一个涉及多个途径和处理阶段的复杂过程,而且不同类型的脑损伤可以影响到特定的处理途径,从而导致不同类型的语言障碍。通过了解这些不同的语言处理阶段,我们可以更好地理解大脑如何处理语言,以及如何因特定的语言网络部分受损而产生不同的语言障碍。文章来源:https://www.toymoban.com/news/detail-831985.html
在有些情况下,词盲症患者能够写下他们听到的词汇并通过阅读来理解它,尽管他们不能通过听觉来理解。这表明了语言处理的多个不同阶段,以及视觉和听觉通道在理解语言中的不同作用。这个模型和对词盲症的观察提供了语言处理是如何在大脑中进行,以及各个组成部分是如何相互作用的深入见解。研究在这一领域仍在继续,以进一步解开语言处理的复杂性。文章来源地址https://www.toymoban.com/news/detail-831985.html
到了这里,关于自然语言处理(NLP) —— 心理语言学的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!