本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。
大家好,我是水滴~~
本文主要对 Stable Diffusion WebUI 的界面进行简单的介绍,让你对该 WebUI 有个大致的了解,为后面的深入学习打下一个基础。主要内容包括:Stable Diffusion 模型(Stable Diffusion checkpoint)、文生图(txt2img)、图生图(img2img)、附加功能(Extras)、图片信息(PNG Info)、模型合并(Checkpoint Merger)、训练(Train)、设置(Settings)、扩展(Extensions)等。
Stable Diffusion 模型(Stable Diffusion checkpoint)
Stable Diffusion 模型(Stable Diffusion checkpoint):用于选择使用大模型,通过【下拉列表】可以选择不同的模型,不同的模型也具有不同的绘图风格。如果有新的模型文件,点击后面的【刷新】按钮,可以加载到【下拉列表】中,无需重启 WebUI。
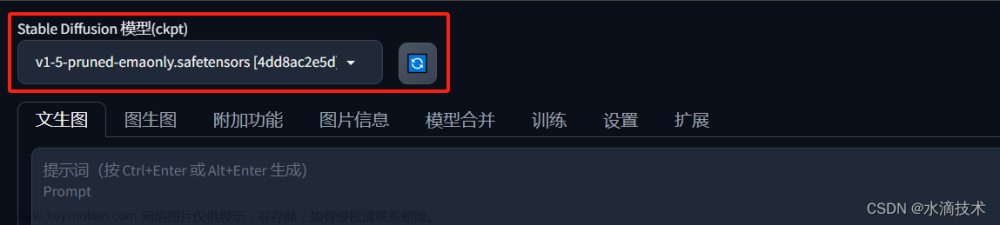
安装好 Stable Diffusion WebUI 时,后自动下载 SD1.5 基础模型:v1-5-pruned-emaonly.safetensors,所以下拉列表中只有这一个模型。
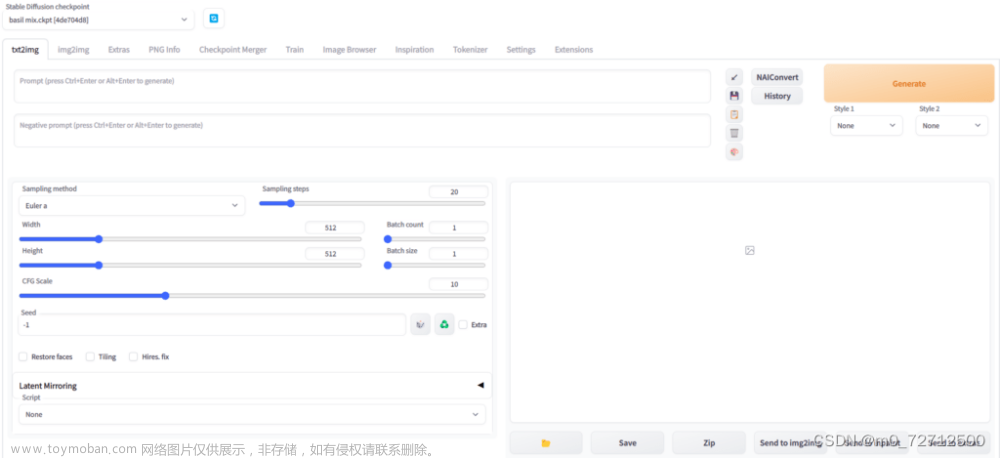
文生图(txt2img)
文生图(txt2img):是 Stable Diffusion WebUI 启动后的默认界面,可以通过文字描述(提示词)来生成图片。

-
提示词(Prompt):又叫正向提示词,即想让图片中出现的内容。使用英文,多个提示词使用英文逗号分隔。
-
负面提示词(Negative Prompt):不想让图片中出现的内容。使用英文,多个负面提示词使用英文逗号分隔。
-
生成参数(Generation):用于选择采样器、设置采样迭代步数、图片的宽度等。
-
生成(Generate):点击生成按钮,会根据提示词和生成参数来生成图片。
图生图(img2img)
图生图(img2img):可以根据参考图片来生成图片,并可以结合提示词一起使用,用于完善图片的细节。


附加功能(Extras)
附加功能(Extras):主要用于放大图片,还可以指定目录来批量处理。

图片信息(PNG Info)
图片信息(PNG Info):用于提取图片的生成信息,如提示词、采样器|、随机种子等。
注:经过二次处理的图片是无法提取生成信息的。

模型合并(Checkpoint Merger)
模型合并(Checkpoint Merger):用于将两个或三个模型进行合并,这样就可以在多个模型的基础上生成图片了。

训练(Train)
训练(Train):用于训练嵌入式(Embedding)或者超网络(Hypernetwork)。

设置(Settings)
设置(Settings):用于设置 Stable Diffusion WebUI,设置好后,需要先【保存设置】再【重启 WebUI】才能生效。。

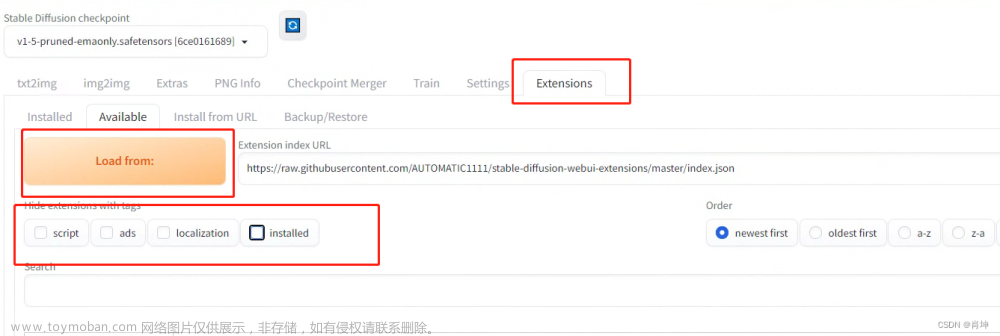
扩展(Extensions)
扩展(Extensions):用于安装插件,安装好插件后,点击【应用并重启用户界面】即可生效。文章来源:https://www.toymoban.com/news/detail-832212.html
 文章来源地址https://www.toymoban.com/news/detail-832212.html
文章来源地址https://www.toymoban.com/news/detail-832212.html
到了这里,关于Stable Diffusion WebUI 界面介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!