目录
最小生成树
Kruskal(克鲁斯卡尔)(以边为核心)
9) 不相交集合(并查集合)
基础
Union By Size
图-相关题目
4.2 Greedy Algorithm
1) 贪心例子
Dijkstra
Prim
Kruskal
最优解(零钱兑换)- 穷举法 Leetcode 322
最优解(零钱兑换)- 贪心法 Leetcode 322
3) Huffman 编码问题
问题引入
Huffman 树
Huffman 编解码
4) 活动选择问题
无重叠区间-Leetcode 435
5) 分数背包问题
贪心法
6) 0-1 背包问题
贪心法
7) Set cover problem
4.3 Dynamic-Programming
1) Fibonacci
降维
2) 最短路径 - Bellman-Ford
3) 不同路径-Leetcode 62
降维
4) 0-1 背包问题
5) 完全背包问题
降维
6) 零钱兑换问题-Leetcode322
零钱兑换 II-Leetcode 518
7) 钢条切割问题
降维
类似题目 Leetcode-343 整数拆分
8) 最长公共子串
类似题目 Leetcode-718 最长重复子数组
两个字符串的删除操作-Leetcode 583
10) 最长上升子序列-Leetcode 300
11) Catalan 数
Leetcode-22 括号生成
买票找零问题
其它问题
12) 打家劫舍-Leetcode 198
13) Travelling salesman problem
其它题目
组合总和 IV-Leetcode 377
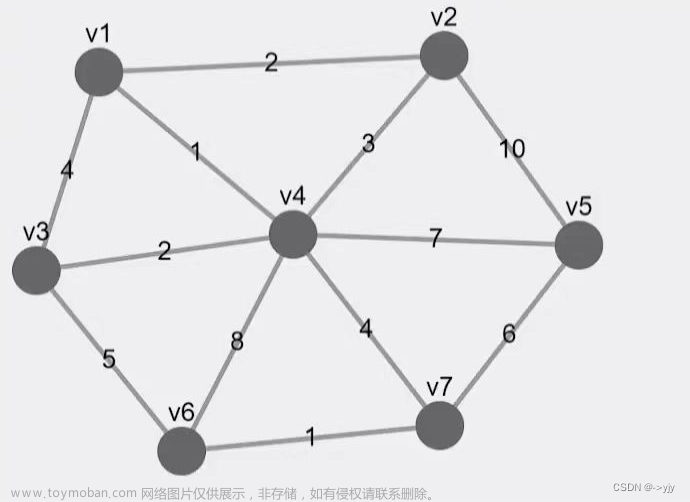
最小生成树
Prim
public class Prim {
public static void main(String[] args) {
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
Vertex v5 = new Vertex("v5");
Vertex v6 = new Vertex("v6");
Vertex v7 = new Vertex("v7");
v1.edges = List.of(new Edge(v2, 2), new Edge(v3, 4), new Edge(v4, 1));
v2.edges = List.of(new Edge(v1, 2), new Edge(v4, 3), new Edge(v5, 10));
v3.edges = List.of(new Edge(v1, 4), new Edge(v4, 2), new Edge(v6, 5));
v4.edges = List.of(new Edge(v1, 1), new Edge(v2, 3), new Edge(v3, 2),
new Edge(v5, 7), new Edge(v6, 8), new Edge(v7, 4));
v5.edges = List.of(new Edge(v2, 10), new Edge(v4, 7), new Edge(v7, 6));
v6.edges = List.of(new Edge(v3, 5), new Edge(v4, 8), new Edge(v7, 1));
v7.edges = List.of(new Edge(v4, 4), new Edge(v5, 6), new Edge(v6, 1));
List<Vertex> graph = List.of(v1, v2, v3, v4, v5, v6, v7);
prim(graph, v1);
}
static void prim(List<Vertex> graph, Vertex source) {
ArrayList<Vertex> list = new ArrayList<>(graph);
source.dist = 0;
while (!list.isEmpty()) {
//选取当前顶点
Vertex min = chooseMinDistVertex(list);
//更新当前顶点
updateNeighboursDist(min);
//移除当前顶点
list.remove(min);
min.visited = true;
System.out.println("---------------");
for (Vertex v : graph) {
System.out.println(v);
}
}
}
private static void updateNeighboursDist(Vertex curr) {
for (Edge edge : curr.edges) {
Vertex n = edge.linked;
if (!n.visited) {
int dist = edge.weight;
if (dist < n.dist) {
n.dist = dist;
n.prev = curr;
}
}
}
}
private static Vertex chooseMinDistVertex(ArrayList<Vertex> list) {
Vertex min = list.get(0);
for (int i = 1; i < list.size(); i++) {
if (list.get(i).dist < min.dist) {
min = list.get(i);
}
}
return min;
}
}
初始

 DIJKSTRA算法
DIJKSTRA算法
Kruskal(克鲁斯卡尔)(以边为核心)

public class Kruskal {
static class Edge implements Comparable<Edge> {
List<Vertex> vertices;
int start;
int end;
int weight;
public Edge(List<Vertex> vertices, int start, int end, int weight) {
this.vertices = vertices;
this.start = start;
this.end = end;
this.weight = weight;
}
public Edge(int start, int end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
@Override
public int compareTo(Edge o) {
return Integer.compare(this.weight, o.weight);
}
@Override
public String toString() {
return vertices.get(start).name + "<->" + vertices.get(end).name + "(" + weight + ")";
}
}
public static void main(String[] args) {
Vertex v1 = new Vertex("v1");
Vertex v2 = new Vertex("v2");
Vertex v3 = new Vertex("v3");
Vertex v4 = new Vertex("v4");
Vertex v5 = new Vertex("v5");
Vertex v6 = new Vertex("v6");
Vertex v7 = new Vertex("v7");
List<Vertex> vertices = List.of(v1, v2, v3, v4, v5, v6, v7);
PriorityQueue<Edge> queue = new PriorityQueue<>(List.of(
new Edge(vertices,0, 1, 2),
new Edge(vertices,0, 2, 4),
new Edge(vertices,0, 3, 1),
new Edge(vertices,1, 3, 3),
new Edge(vertices,1, 4, 10),
new Edge(vertices,2, 3, 2),
new Edge(vertices,2, 5, 5),
new Edge(vertices,3, 4, 7),
new Edge(vertices,3, 5, 8),
new Edge(vertices,3, 6, 4),
new Edge(vertices,4, 6, 6),
new Edge(vertices,5, 6, 1)
));
kruskal(vertices.size(), queue);
}
static void kruskal(int size, PriorityQueue<Edge> queue) {
List<Edge> result = new ArrayList<>();
DisjointSet set = new DisjointSet(size);
while (result.size() < size - 1) {
Edge poll = queue.poll();
int s = set.find(poll.start);
int e = set.find(poll.end);
if (s != e) {//未相交
result.add(poll);
set.union(s, e);//相交
}
}
for (Edge edge : result) {
System.out.println(edge);
}
}
}
9) 不相交集合(并查集合)
基础

public class DisjointSet {
int[] s;
// 索引对应顶点
// 元素是用来表示与之有关系的顶点
/*
索引 0 1 2 3 4 5 6
元素 [0, 1, 2, 3, 4, 5, 6] 表示一开始顶点直接没有联系(只与自己有联系)
*/
public DisjointSet(int size) {
s = new int[size];
for (int i = 0; i < size; i++) {
s[i] = i;
}
}
// find 是找到老大
public int find(int x) {
if (x == s[x]) {
return x;
}
return find(s[x]);
}
// union 是让两个集合“相交”,即选出新老大,x、y 是原老大索引
public void union(int x, int y) {
s[y] = x;
}
@Override
public String toString() {
return Arrays.toString(s);
}
}

 路径压缩 直接改成老大
路径压缩 直接改成老大
public int find(int x) { // x = 2
if (x == s[x]) {
return x;
}
return s[x] = find(s[x]); // 0 s[2]=0
}UnionBySize



Union By Size
public class DisjointSetUnionBySize {
int[] s;
int[] size;//顶点个数多的当作老大比较合适 新的数组记录个数
public DisjointSetUnionBySize(int size) {
s = new int[size];
this.size = new int[size];
for (int i = 0; i < size; i++) {//初始化
s[i] = i;
this.size[i] = 1;
}
}
// find 是找到老大 - 优化:路径压缩
public int find(int x) { // x = 2
if (x == s[x]) {
return x;
}
return s[x] = find(s[x]); // 0 s[2]=0
}
// union 是让两个集合“相交”,即选出新老大,x、y 是原老大索引
public void union(int x, int y) {
//x 新老大 y新小弟
// s[y] = x;
if (size[x] < size[y]) {
//y 老大 x小弟
// s[x] = y;
// size[y] = size[x] + size[y];//更新老大的元素个数
int t = x;
x = y;
y = t;
}
s[y] = x;
size[x] = size[x] + size[y];//更新老大的元素个数
}
@Override
public String toString() {
return "内容:"+Arrays.toString(s) + "\n大小:" + Arrays.toString(size);
}
public static void main(String[] args) {
DisjointSetUnionBySize set = new DisjointSetUnionBySize(5);
set.union(1, 2);
set.union(3, 4);
set.union(1, 3);
System.out.println(set);
}
}图-相关题目
| 题目编号 | 题目标题 | 算法思想 |
|---|---|---|
| 547 | 省份数量 | DFS、BFS、并查集 |
| 797 | 所有可能路径 | DFS、BFS |
| 1584 | 连接所有点的最小费用 | 最小生成树 |
| 743 | 网络延迟时间 | 单源最短路径 |
| 787 | K 站中转内最便宜的航班 | 单源最短路径 |
| 207 | 课程表 | 拓扑排序 |
| 210 | 课程表 II | 拓扑排序 |
4.2 Greedy Algorithm
1) 贪心例子
称之为贪心算法或贪婪算法,核心思想是
-
将寻找最优解的问题分为若干个步骤
-
每一步骤都采用贪心原则,选取当前最优解(局部最优->全局最优)
-
因为没有考虑所有可能,局部最优的堆叠不一定让最终解最优
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法。这种算法通常用于求解优化问题,如最小生成树、背包问题等。
贪心算法的应用:
-
背包问题:给定一组物品和一个背包,每个物品有一定的重量和价值,要求在不超过背包容量的情况下,尽可能多地装入物品。
-
活动选择问题:在一个活动集合中,每次只能参加一个活动,问如何安排时间以最大化所有活动的收益。
-
编辑距离问题:给定两个字符串,求它们之间的最小编辑距离(即将一个字符串转换为另一个字符串所需的最少操作次数)。
-
网络流问题:给定一张有向图和一些起点和终点,求最大流量。
-
找零问题:给定一定数量的硬币和需要找零的金额,求使用最少的硬币数。
常见问题及解答:
-
贪心算法一定会找到最优解吗? 答:不一定。贪心算法只保证在每一步选择中都是最优的,但并不能保证整个问题的最优解。例如,背包问题中的贪心算法可能会导致最后一个物品没有被装入背包。
-
如何判断一个问题是否适合用贪心算法解决? 答:一个问题如果可以用递归的方式分解成若干个子问题,且每个子问题都有明确的最优解(即局部最优),那么这个问题就可以用贪心算法解决。
-
贪心算法的时间复杂度是多少? 答:贪心算法的时间复杂度取决于问题的规模和具体实现。一般来说,对于规模较小的问题,贪心算法的时间复杂度可以达到O(nlogn)或O(n^2);对于规模较大的问题,可能需要O(n^3)或更高。
几个贪心的例子
Dijkstra
// ...
while (!list.isEmpty()) {
// 选取当前【距离最小】的顶点
Vertex curr = chooseMinDistVertex(list);
// 更新当前顶点邻居距离
updateNeighboursDist(curr);
// 移除当前顶点
list.remove(curr);
// 标记当前顶点已经处理过
curr.visited = true;
}
-
没找到最短路径的例子:负边存在时,可能得不到正确解
-
问题出在贪心的原则会认为本次已经找到了该顶点的最短路径,下次不会再处理它(curr.visited = true)
-
与之对比,Bellman-Ford 并没有考虑局部距离最小的顶点,而是每次都处理所有边,所以不会出错,当然效率不如 Dijkstra
Prim
// ...
while (!list.isEmpty()) {
// 选取当前【距离最小】的顶点
Vertex curr = chooseMinDistVertex(list);
// 更新当前顶点邻居距离
updateNeighboursDist(curr);
// 移除当前顶点
list.remove(curr);
// 标记当前顶点已经处理过
curr.visited = true;
}
Kruskal
// ...
while (list.size() < size - 1) {
// 选取当前【距离最短】的边
Edge poll = queue.poll();
// 判断两个集合是否相交
int i = set.find(poll.start);
int j = set.find(poll.end);
if (i != j) { // 未相交
list.add(poll);
set.union(i, j); // 相交
}
}
其它贪心的例子
-
选择排序、堆排序
-
拓扑排序
-
并查集合中的 union by size 和 union by height
-
哈夫曼编码
-
钱币找零,英文搜索关键字
-
change-making problem
-
find Minimum number of Coins
-
-
任务编排文章来源:https://www.toymoban.com/news/detail-832227.html
-
求复杂问题的近似解文章来源地址https://www.toymoban.com/news/detail-832227.html
### 2) 零钱兑换问题
#### 有几个解(零钱兑换 II)Leetcode 518
```java
publi到了这里,关于数据结构高级算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!