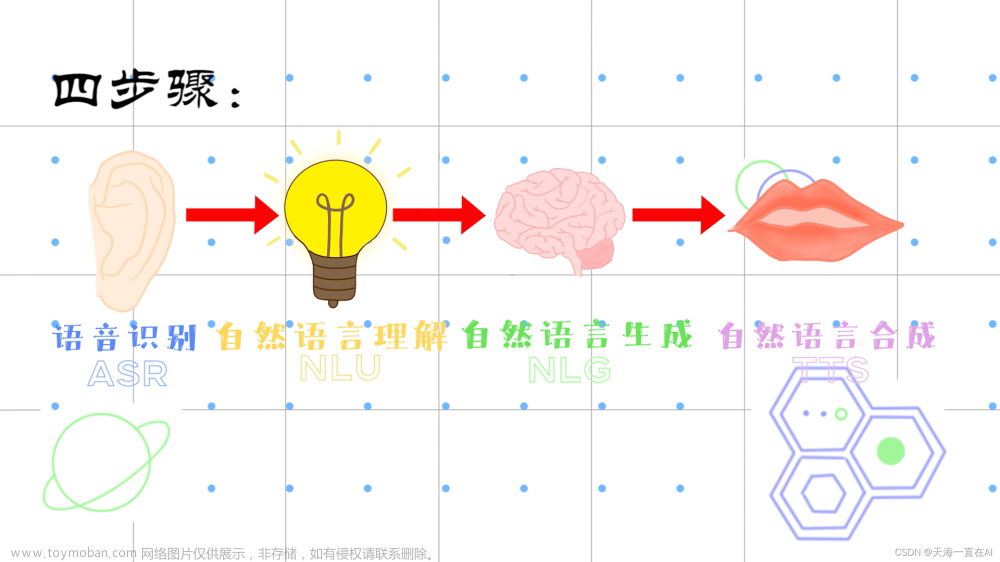
个人认为,主要是两个难点:
1.语料,通常的语料很好解决,用爬虫从互联网上就可以采集和标注训练。但是我们接触很多项目和客户需求都是专业性很强的,例如:航天材料、电气设备、地理信息、化学试剂 等等。往往很多素材和语料都是很宝贵的,而且都是这些企业的内部资料。同时,客户是对技术算法和模型不懂的,我们的工程师对客户业务一窍不通,双方一开始的时候都不知道怎么分类和标注及训练等等,更不要说让机器能听懂人的指令了。也就意味着,我们要有一帮苦逼的项目经理、产品经理、工程师、测试人员要把客户资料学一遍,再去做标注和分类。例如:需要抽取航天材料资料里面的数据,得知道哪些数据是有用的,以及数据之间的对应关系。再说了,客户本来希望通过我们帮助他们的高级人才节省时间,我们总不能让那些博士、专家帮我们做标注训练吧,实际场景下是行不通的,只能我们自己学一遍,自己干。
btw:有人会说用大模型解决...就算ChatGPT再强大,他也不是万能什么都懂的,而且很多数据都在客户内网环境。
2.语境,不同的环境以及不同人说的话,实际场景中意义是不同的,例如:证监会网站的服务器被攻击了。这句话对于股票市场的涨跌幅没有任何影响。再例如:宝马车很好,奔驰车很拉胯。这句话到底是正面还是负面呢?要看说这个话的让和说这个话当时的场景是什么?
其次,传统的自然语言处理(NLP)技术,就像是我们让电脑去理解人类的语言,但这个任务其实挺难的。首先,电脑虽然能听懂一些话,但要完全理解我们说话的上下文和背后的深层含义,它还是有点儿吃力。其次,世界上的语言千奇百怪,电脑得学会适应各种不同的说话方式,这可不是件容易的事。
电脑要学说话,得有好的教材,也就是大量的数据。但这些数据有时候质量参差不齐,有时候还带有偏见,而且电脑学的东西越多,需要的存储空间和计算能力也就越大。而且,电脑学说话的过程就像是个黑盒子,我们很难知道它是怎么做出决定的。
电脑学语言的方式也很重要。有时候,我们得给它设定一大堆规则,但这些规则可能不够灵活。有时候,我们用统计的方法让电脑自己从数据里学习,但这样又可能遇到新情况时不知所措。
自然语言本身就很灵活,有时候一句话可以有多种意思,这让电脑很头疼。而且,电脑还得学会处理那些专业领域的术语,这就需要它懂得更多。最后,电脑还得学会和人实时对话,这要求它反应快,还得能跟上对话的节奏。

同时给大家推荐一个开源项目
多模态AI能力引擎平台: 免费的自然语言处理、情感分析、实体识别、图像识别与分类、OCR识别、语音识别接口,功能强大,欢迎体验。https://gitee.com/stonedtx/free-nlp-api文章来源:https://www.toymoban.com/news/detail-832300.html
.文章来源地址https://www.toymoban.com/news/detail-832300.html
到了这里,关于【经验分享】自然语言处理技术有哪些局限性和挑战?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!