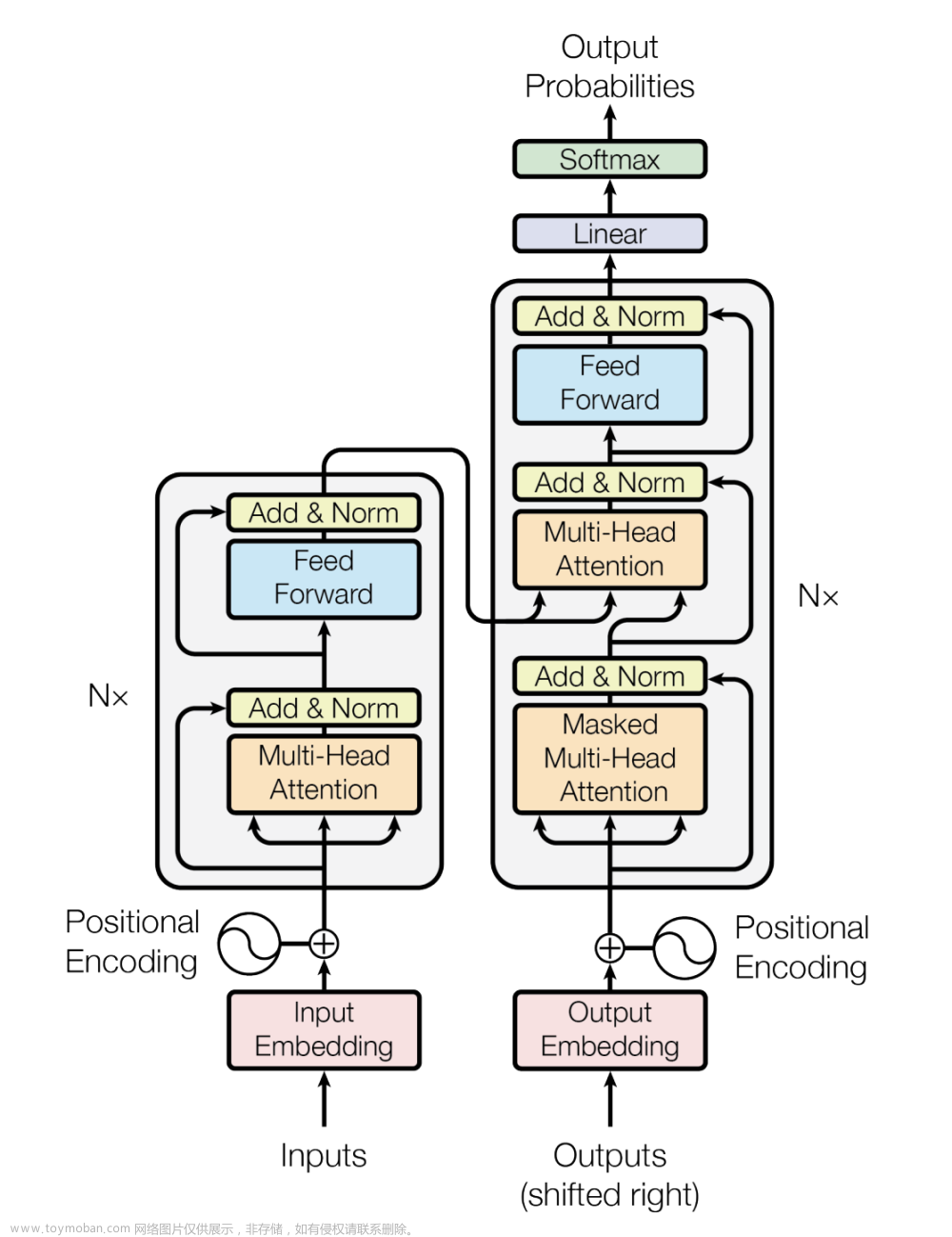
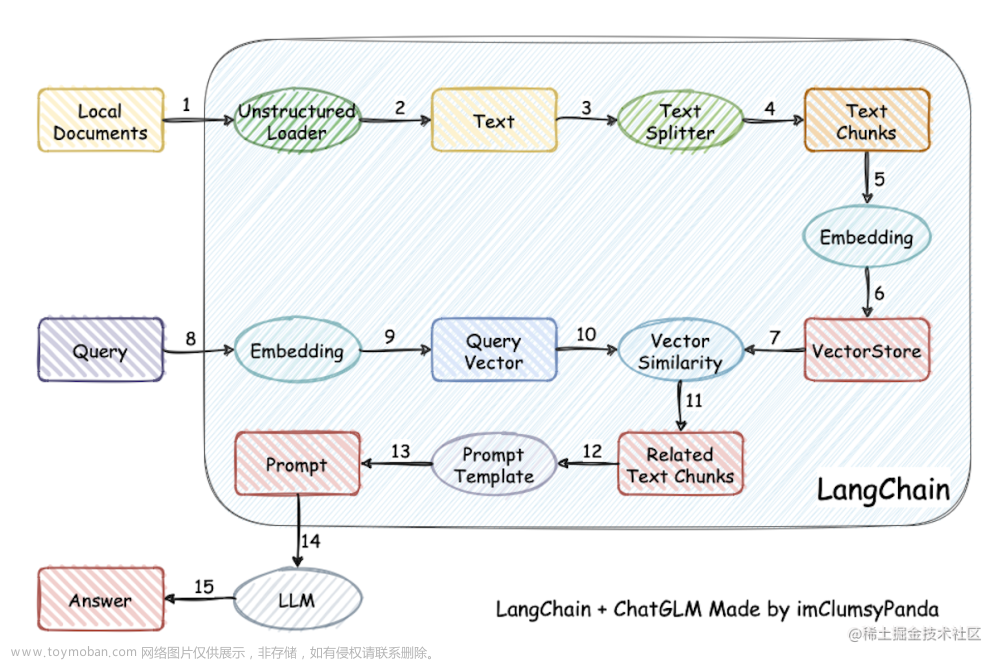
本项目使用Langchain 和 baichuan 大模型, 结合领域百科词条数据(用xlsx保存),简单地实现了领域百科问答实现。文章来源地址https://www.toymoban.com/news/detail-832318.html
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings, SentenceTransformerEmbeddings
from langchain_community.vectorstores import Chroma, FAISS
from langchain_community.llms import OpenAI, Baichuan
from langchain_community.chat_models import ChatOpenAI, ChatBaichuan
from langchain.memory import ConversationBufferWindowMemory
from langchain.chains import ConversationalRetrievalChain, RetrievalQA
#import langchain_community import chat_models
#print(chat_models.__all__)
import streamlit as st
import pandas as pd
import os
import warnings
import time
warnings.filterwarnings('ignore')
# 对存储了领域百科词条的xlsx文件进行解析
def get_xlsx_text(xlsx_file):
df = pd.read_excel(xlsx_file, engine='openpyxl')
text = ""
for index, row in df.iterrows():
text += row['title'].replace('\n', '')
text += row['content'].replace('\n', '')
text += '\n\n'
return text
# Splits a given text into smaller chunks based on specified conditions
def get_text_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(
separators="\n\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunks
# 对切分的文本块构建编码向量并存储到FASISS
# Generates embeddings for given text chunks and creates a vector store using FAISS
def get_vectorstore(text_chunks):
# embeddings = OpenAIEmbeddings() #有经济条件的可以使用 opanaiembending
embeddings = SentenceTransformerEmbeddings(model_name='all-MiniLM-L6-v2')
vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)
return vectorstore
# Initializes a conversation chain with a given vector store
# 对切分的文本块构建编码向量并存储到Chroma
# Generates embeddings for given text chunks and creates a vector store using Chroma
def get_vectorstore_chroma(text_chunks):
# embeddings = OpenAIEmbeddings()
embeddings = SentenceTransformerEmbeddings(model_name='all-MiniLM-L6-v2')
vectorstore = Chroma.from_texts(
texts=text_chunks, embedding=embeddings)
return vectorstore
def get_conversation_chain_baichuan(vectorstore):
memory = ConversationBufferWindowMemory(
memory_key='chat_history', return_message=True) # 设置记忆存储器
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=Baichuan(temperature=temperature_input, model_name=model_select),
retriever=vectorstore.as_retriever(),
get_chat_history=lambda h: h,
memory=memory
)
return conversation_chain
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"
# langchain 可以通过设置环境变量来设置参数
os.environ['BAICHUAN_API_KEY'] = 'sk-88888888888888888888888888888888'
temperature_input = 0.7
model_select = 'Baichuan2-Turbo-192K'
raw_text = get_xlsx_text('领域文件/twiki百科问答.xlsx')
text_chunks = get_text_chunks(raw_text)
vectorstore = get_vectorstore_chroma(text_chunks)
# Create conversation chain
qa = get_conversation_chain_baichuan(vectorstore)
questions = [
"什么是森林经营项目?",
"风电项目开发过程中需要的主要资料?",
"什么是ESG"
]
for question in questions:
result = qa(question)
print(f"**Question**: {question} \n")
print(f"**Answer__**: {result['answer']} \n")
文章来源:https://www.toymoban.com/news/detail-832318.html
到了这里,关于【Langchain】+ 【baichuan】实现领域知识库【RAG】问答系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!