1.背景介绍
1. 背景介绍
Apache Flink 是一个流处理框架,用于实时数据处理和分析。它支持大规模数据流处理,具有高吞吐量和低延迟。Flink 可以处理各种数据源和数据接收器,如 Kafka、HDFS、TCP 流等。
时间序列分析是一种用于分析时间序列数据的方法,用于发现数据中的趋势、季节性和随机性。时间序列分析在各种领域都有应用,如金融、生物、气候等。
本文将介绍 Flink 的流式数据处理与时间序列分析,包括核心概念、算法原理、最佳实践、应用场景和工具推荐。
2. 核心概念与联系
2.1 Flink 流处理
Flink 流处理是一种处理实时数据流的方法,可以实时计算和分析数据。Flink 流处理包括以下核心概念:
- 数据流(DataStream):数据流是 Flink 中用于表示不断到来的数据的抽象。数据流可以包含各种数据类型,如基本类型、复合类型和用户定义类型。
- 数据源(Source):数据源是 Flink 中用于生成数据流的组件。数据源可以是本地文件、网络流、数据库等。
- 数据接收器(Sink):数据接收器是 Flink 中用于接收处理结果的组件。数据接收器可以是本地文件、网络流、数据库等。
- 数据操作(Transformation):数据操作是 Flink 中用于对数据流进行转换的操作。数据操作包括各种基本操作,如映射、筛选、连接等。
2.2 时间序列分析
时间序列分析是一种用于分析时间序列数据的方法,用于发现数据中的趋势、季节性和随机性。时间序列分析在各种领域都有应用,如金融、生物、气候等。
时间序列分析包括以下核心概念:
- 趋势(Trend):趋势是时间序列中长期变化的一种。趋势可以是线性的、指数的或其他形式的。
- 季节性(Seasonality):季节性是时间序列中短期变化的一种。季节性通常与时间单位(如月、季度、年)相关。
- 随机性(Randomness):随机性是时间序列中不可预测的一种。随机性通常由噪声、观测误差等因素引起。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 流式数据处理算法原理
Flink 流式数据处理的核心算法原理是基于数据流图(Dataflow Graph)的计算模型。数据流图是一种抽象,用于表示 Flink 流处理应用的计算逻辑。数据流图包括数据源、数据接收器和数据操作组件。
数据流图的计算过程可以分为以下步骤:
- 构建数据流图:首先,需要构建数据流图,包括数据源、数据接收器和数据操作组件。数据流图可以通过 Flink API 进行定义。
- 分配任务:接下来,需要将数据流图分配到 Flink 集群中的各个任务节点。Flink 使用资源调度器(Resource Scheduler)来分配任务。
- 执行计算:最后,需要执行数据流图中的计算。Flink 使用数据流计算引擎(DataStream Engine)来执行计算。数据流计算引擎根据数据流图中的数据操作组件,对数据流进行转换和计算。
3.2 时间序列分析算法原理
时间序列分析的核心算法原理是基于时间序列模型的建立和拟合。时间序列模型是一种用于描述时间序列数据的模型。时间序列模型可以是线性模型、非线性模型、随机模型等。
时间序列分析的核心算法原理可以分为以下步骤:
- 数据预处理:首先,需要对时间序列数据进行预处理。数据预处理包括数据清洗、数据转换、数据差分等。
- 模型建立:接下来,需要根据时间序列数据的特点,选择合适的时间序列模型。时间序列模型可以是自回归(AR)模型、自回归移动平均(ARIMA)模型、季节性自回归移动平均(SARIMA)模型等。
- 模型拟合:最后,需要根据时间序列数据,对选定的时间序列模型进行拟合。模型拟合可以使用最小二乘法(Least Squares)、最大似然法(Maximum Likelihood)等方法。
4. 具体最佳实践:代码实例和详细解释说明
4.1 Flink 流式数据处理最佳实践
以下是一个 Flink 流式数据处理的代码实例:
```java import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.SourceFunction;
public class FlinkStreamingJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SourceFunction<String> source = new SourceFunction<String>() {
@Override
public void run(SourceContext<String> ctx) throws Exception {
for (int i = 0; i < 10; i++) {
ctx.collect("Event " + i);
}
}
};
DataStream<String> stream = env.addSource(source);
stream.print();
env.execute("Flink Streaming Job");
}} ```
4.2 时间序列分析最佳实践
以下是一个时间序列分析的代码实例:
```java import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.SinkFunction; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class FlinkTimeSeriesAnalysisJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Double> stream = env.fromElements(1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0);
stream.window(Time.minutes(1))
.apply(new CalculateAverage())
.addSink(new PrintSink());
env.execute("Flink Time Series Analysis Job");
}} ```
5. 实际应用场景
Flink 流式数据处理可以应用于各种场景,如实时监控、实时分析、实时推荐等。时间序列分析可以应用于金融、生物、气候等领域。
5.1 Flink 流式数据处理应用场景
- 实时监控:Flink 可以用于实时监控系统性能、网络性能、设备性能等。实时监控可以帮助发现问题,提高系统稳定性。
- 实时分析:Flink 可以用于实时分析用户行为、商品销售、网络流量等。实时分析可以帮助发现趋势,提前做出决策。
- 实时推荐:Flink 可以用于实时推荐用户个性化内容、商品推荐、广告推荐等。实时推荐可以提高用户满意度,增加用户粘性。
5.2 时间序列分析应用场景
- 金融:时间序列分析可以用于分析股票价格、债券利率、外汇汇率等。时间序列分析可以帮助金融机构做出投资决策。
- 生物:时间序列分析可以用于分析生物数据,如基因表达、蛋白质定量、细胞分裂等。时间序列分析可以帮助生物学家发现生物过程中的规律。
- 气候:时间序列分析可以用于分析气候数据,如温度、雨量、湿度等。时间序列分析可以帮助气候学家预测气候变化。
6. 工具和资源推荐
6.1 Flink 流式数据处理工具和资源
- Flink 官方文档:Flink 官方文档提供了详细的 Flink 流式数据处理的概念、API、示例等。Flink 官方文档地址:https://flink.apache.org/docs/stable/
- Flink 社区资源:Flink 社区提供了大量的 Flink 流式数据处理的示例、教程、博客等。Flink 社区资源地址:https://flink.apache.org/community.html
- Flink 学习课程:Flink 学习课程提供了系统的 Flink 流式数据处理的知识、技巧、实践等。Flink 学习课程地址:https://flink.apache.org/training.html
6.2 时间序列分析工具和资源
- Python 时间序列分析库:Python 时间序列分析库提供了多种时间序列分析算法的实现,如 ARIMA、SARIMA、Exponential Smoothing 等。Python 时间序列分析库地址:https://docs.scipy.org/doc/scipy/reference/tutorial/statsmodels.tsa.html
- R 时间序列分析包:R 时间序列分析包提供了多种时间序列分析算法的实现,如 ARIMA、SARIMA、Exponential Smoothing 等。R 时间序列分析包地址:https://cran.r-project.org/web/views/TimeSeries.html
- 时间序列分析教程:时间序列分析教程提供了详细的时间序列分析的概念、算法、应用等。时间序列分析教程地址:https://otexts.com/fpp2/index.html
7. 总结:未来发展趋势与挑战
Flink 流式数据处理和时间序列分析是两个具有挑战性和未来发展潜力的领域。Flink 流式数据处理可以应用于各种场景,如实时监控、实时分析、实时推荐等。时间序列分析可以应用于金融、生物、气候等领域。
未来,Flink 流式数据处理和时间序列分析将面临以下挑战:
- 大规模数据处理:随着数据规模的增加,Flink 流式数据处理和时间序列分析将面临大规模数据处理的挑战。未来,Flink 需要优化算法和架构,以支持更大规模的数据处理。
- 实时性能:随着数据速率的增加,Flink 流式数据处理和时间序列分析将面临实时性能的挑战。未来,Flink 需要优化网络和计算资源,以提高实时性能。
- 智能分析:随着数据的复杂性和多样性增加,Flink 流式数据处理和时间序列分析将面临智能分析的挑战。未来,Flink 需要开发新的算法和模型,以支持智能分析。
8. 附录:常见问题与解答
8.1 Flink 流式数据处理常见问题与解答
Q:Flink 流式数据处理与批处理有什么区别?
A:Flink 流式数据处理与批处理的主要区别在于数据处理模型。流式数据处理是对实时数据流的处理,批处理是对批量数据的处理。流式数据处理需要考虑数据到来的顺序和时间,而批处理可以考虑数据的大小和结构。
Q:Flink 流式数据处理如何处理数据丢失?
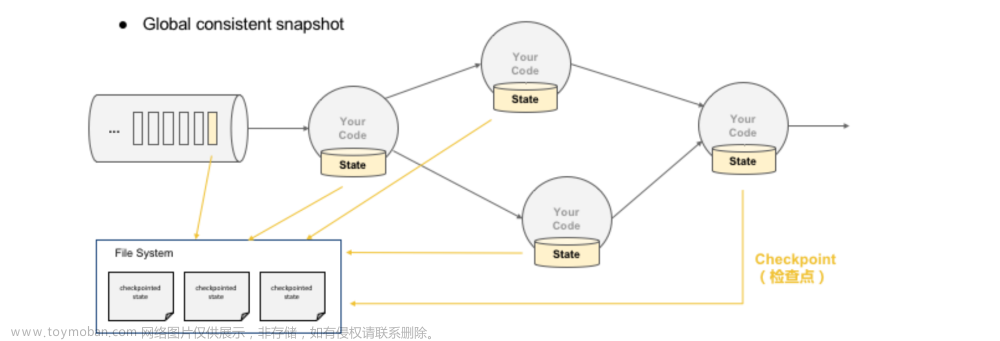
A:Flink 流式数据处理可以使用窗口和检查点机制来处理数据丢失。窗口可以将数据分组,以便在数据丢失时可以使用相邻数据填充。检查点机制可以确保数据的一致性,以便在故障时可以恢复数据。
Q:Flink 流式数据处理如何处理数据延迟?
A:Flink 流式数据处理可以使用时间窗口和时间戳机制来处理数据延迟。时间窗口可以将数据分组,以便在数据延迟时可以使用相邻数据填充。时间戳机制可以确保数据的准确性,以便在延迟时可以准确计算时间序列。
8.2 时间序列分析常见问题与解答
Q:时间序列分析如何处理缺失数据?
A:时间序列分析可以使用插值、删除、填充等方法处理缺失数据。插值可以使用近邻数据进行插值。删除可以删除缺失数据。填充可以使用近邻数据或均值填充缺失数据。
Q:时间序列分析如何处理季节性?
A:时间序列分析可以使用差分、分解、滤波等方法处理季节性。差分可以将季节性分解为趋势和季节性组件。分解可以将时间序列分解为多个组件,如趋势、季节性、随机性等。滤波可以减少季节性影响。
Q:时间序列分析如何处理随机性?
A:时间序列分析可以使用差分、滤波、模型等方法处理随机性。差分可以将随机性分解为趋势和随机性组件。滤波可以减少随机性影响。模型可以建立时间序列模型,以预测随机性。
9. 参考文献
[1] Apache Flink 官方文档。https://flink.apache.org/docs/stable/
[2] Python 时间序列分析库。https://docs.scipy.org/doc/scipy/reference/tutorial/statsmodels.tsa.html
[3] R 时间序列分析包。https://cran.r-project.org/web/views/TimeSeries.html文章来源:https://www.toymoban.com/news/detail-832402.html
[4] 时间序列分析教程。https://otexts.com/fpp2/index.html文章来源地址https://www.toymoban.com/news/detail-832402.html
到了这里,关于Flink的流式数据处理与时间序列分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!