一.背景
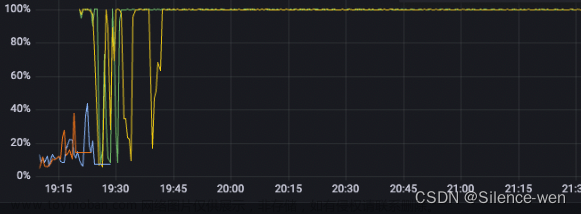
今天下午Redis的cpu占用突然异常升高,一度占用达到了90%,触发了钉钉告警,之后又回到正常水平,跟DBA沟通,他说主要是下面这个语句的问题
SCAN 0 MATCH fastUser:6136* COUNT 10000
这个语句的执行时长很短,只有10毫秒,主要是利用scan匹配redis的所有key,当时第一反应是有大key。但是查询这个语句匹配的key,发现key的数量只有4个,而且每个key的值也都不多,没有到10kb,不算大key,因为知道keys命令是会遍历查询所有key,而redis是单线程的,当redis包含数百万甚至更多的键时,keys*会导致其他命令阻塞等候,也会导致cpu异常升高。因此我们使用scan来进行匹配,但是还是出现了这种情况,当时不明白为什么会导致cpu异常升高,于是开始查阅相关资料。

二.关于redis的scan命令
1.官方文档
先查看了redis的文档中关于scan的描述
翻译一下
该
SCAN命令和密切相关的命令SSCAN,HSCAN和ZSCAN用于增量迭代元素集合。
SCAN迭代当前选定的 Redis 数据库中的键集。SSCAN迭代 Sets 类型的元素。HSCAN迭代 Hash 类型的字段及其关联值。ZSCAN迭代有序集类型的元素及其关联的分数。由于这些命令允许增量迭代,每次调用仅返回少量元素,因此它们可以在生产中使用,而不会出现类似
KEYS或SMEMBERS等命令的缺点,这些命令在针对大集合的key或元素调用时可能会阻塞服务器很长一段时间(甚至几秒钟)。然而,虽然像
SMEMBERS这样的阻塞命令能够在给定时刻提供属于 Set 的所有元素,但 SCAN 系列命令仅对返回的元素提供有限的保证,因为我们增量迭代的集合可能会在迭代过程中发生变化。请注意
SCAN,SSCAN、HSCAN和ZSCANall 的工作方式非常相似,因此本文档涵盖了所有四个命令。然而,一个明显的区别是,在 的情况下SSCAN,HSCAN第ZSCAN一个参数是保存 Set、Hash 或 Sorted Set 值的键的名称。该SCAN命令不需要任何键名参数,因为它迭代当前数据库中的键,因此迭代的对象是数据库本身。
- 可以看到,官方文档中也说明了,scan命令可以在生产中使用,不会像
keys和smembers命令一样锁住redis很长时间(甚至好几秒钟),因此网上很多文章说用scan代替keys是有一定道理的,但是文档中也说明了,scan命令并不保证能完整的获取所有的键,至于原因,后续的文档中也能知道是为什么,因为scan是分段的流式查询,在其中一次查询的时候是能保证这一次查询的这一段的正确性,但是在查询下一段的时候,可能中间已经有其他命令修改了redis中键的情况,所以多次查询之间并不保证数据是一致的,因此scan命令匹配出来的键可能会不完整。
SCAN basic usage
SCAN is a cursor based iterator. This means that at every call of the command, the server returns an updated cursor that the user needs to use as the cursor argument in the next call.
An iteration starts when the cursor is set to 0, and terminates when the cursor returned by the server is 0. The following is an example of SCAN iteration:
redis 127.0.0.1:6379> scan 0 1) "17" 2) 1) "key:12" 2) "key:8" 3) "key:4" 4) "key:14" 5) "key:16" 6) "key:17" 7) "key:15" 8) "key:10" 9) "key:3" 10) "key:7" 11) "key:1" redis 127.0.0.1:6379> scan 17 1) "0" 2) 1) "key:5" 2) "key:18" 3) "key:0" 4) "key:2" 5) "key:19" 6) "key:13" 7) "key:6" 8) "key:9" 9) "key:11"In the example above, the first call uses zero as a cursor, to start the iteration. The second call uses the cursor returned by the previous call as the first element of the reply, that is, 17.
As you can see the SCAN return value is an array of two values: the first value is the new cursor to use in the next call, the second value is an array of elements.
Since in the second call the returned cursor is 0, the server signaled to the caller that the iteration finished, and the collection was completely explored. Starting an iteration with a cursor value of 0, and calling
SCANuntil the returned cursor is 0 again is called a full iteration.SCAN基本用法
SCAN 是一个基于游标的迭代器。这意味着在每次调用该命令时,服务器都会返回一个更新的游标,用户需要在下一次调用中将其用作游标参数。
当游标设置为0时,迭代开始,当服务器返回的游标为0时,迭代终止。以下是SCAN迭代的示例:
redis 127.0.0.1:6379> scan 0 1) "17" 2) 1) "key:12" 2) "key:8" 3) "key:4" 4) "key:14" 5) "key:16" 6) "key:17" 7) "key:15" 8) "key:10" 9) "key:3" 10) "key:7" 11) "key:1" redis 127.0.0.1:6379> scan 17 1) "0" 2) 1) "key:5" 2) "key:18" 3) "key:0" 4) "key:2" 5) "key:19" 6) "key:13" 7) "key:6" 8) "key:9" 9) "key:11"在上面的示例中,第一次调用使用0作为游标来开始迭代。第二次调用使用前一次调用返回的光标作为回复的第一个元素,即 17。
正如您所看到的,SCAN 返回值是一个由两个值组成的数组:第一个值是在下一次调用中使用的新游标,第二个值是一个元素数组。
由于在第二次调用中返回的游标为 0,因此服务器向调用者发出信号,表明迭代已完成,并且集合已被完全探索。以游标值为 0 开始迭代,并调用
SCAN直到返回的游标再次为 0 称为完整迭代。

扫描保证
该
SCAN命令以及该SCAN系列中的其他命令能够向用户提供一组与完整迭代相关的保证。
- 完整迭代始终检索从完整迭代开始到结束期间集合中存在的所有元素。这意味着,如果给定元素在迭代开始时位于集合内部,并且在迭代终止时仍然存在,则在某个时刻将
SCAN其返回给用户。- 完整迭代永远不会返回从完整迭代开始到结束期间集合中不存在的任何元素。因此,如果一个元素在迭代开始之前被删除,并且在迭代持续期间从未添加回集合中,
SCAN则确保该元素永远不会被返回。然而,由于
SCAN关联的状态非常少(只有光标),因此它具有以下缺点:
- 给定元素可能会多次返回。由应用程序来处理重复元素的情况,例如,仅使用返回的元素来执行多次重新应用时安全的操作。
- 在完整迭代期间不经常出现在集合中的元素可能会返回,也可能不会:它是未定义的。
从这里也能看出,如果并不是在完整迭代持续期间一直存在的key,是不能保证一定扫描的出来的


每次 SCAN 调用返回的元素数量
SCAN系列函数不保证每次调用返回的元素数量在给定范围内。这些命令还允许返回零元素,并且只要返回的游标不为零,客户端就不应该认为迭代完成。但返回的元素数量是合理的,即在实际情况下,
SCAN在迭代大型集合时可能会返回最多几十个元素的数量,也可能会在一次调用中返回集合的所有元素当迭代集合小到足以在内部表示为编码数据结构时(这种情况发生在小集合、哈希和排序集合中)。但是,用户可以使用COUNT选项调整每次调用返回元素数量的数量级。
计数选项
虽然
SCAN不能保证每次迭代返回的元素数量,但可以凭经验调整SCAN使用COUNT选项的行为。基本上,用户可以使用 COUNT 指定每次调用时应完成的工作量,以便从集合中检索元素。这只是实现的一个提示,但是一般来说,这是您在大多数情况下可以从实现中期望得到的。
- 默认
COUNT值为 10。- 当迭代键空间,或者足够大到可以用哈希表表示的集合、哈希或有序集合时,假设没有使用MATCH选项,服务器通常会在每次调用时返回count或多于count的元素。请查看本文档后面的为什么 SCAN 可能会一次返回所有元素部分。
- 当迭代编码为 intsets(仅由整数组成的小集合)的 Sets 或编码为 ziplists 的哈希值和排序集合(由小的单个值组成的小哈希值和集合)时,通常在第一次调用中返回所有元素,
SCAN无论COUNT值如何。重要提示:无需为每次迭代使用相同的 COUNT 值。调用者可以根据需要自由地将计数从一次迭代更改为另一次迭代,只要在下一次调用中传递的光标是在上一次调用该命令时获得的光标即可。
从redis的官方文档上可以得知:
-
scan命令是基于游标的迭代器,是可以在生产上使用的,scan与keys和smembers相比,会一段一段的进行扫描,解决了key数量过多、大key时的阻塞问题 -
scan并不能保证一定扫描出所有匹配的key(如果key在整个完整迭代(full iteration)过程中一直存在则一定会扫描出来),并且有可能扫描出重复的key,需要查询出来后自己去重 -
scan扫描出来的数量不一定在count指定的范围内,即查询出来的数量有可能大于count
2.相关博客
读完官方文档后,我对scan有了个大概得了解,但是还是比较模糊,于是查阅相关的博客进行深入了解。
在文章redis应用 9: Scan中,找到了比较通俗的讲解
字典的结构
在 Redis 中所有的 key 都存储在一个很大的字典中,这个字典的结构和 Java 中的 HashMap 一样,是一维数组 + 二维链表结构,第一维数组的大小总是 2^n(n>=0),扩容一次数组大小空间加倍,也就是 n++。
img
scan 指令返回的游标就是第一维数组的位置索引,我们将这个位置索引称为槽 (slot)。如果不考虑字典的扩容缩容,直接按数组下标挨个遍历就行了。limit 参数就表示需要遍历的槽位数,之所以返回的结果可能多可能少,是因为不是所有的槽位上都会挂接链表,有些槽位可能是空的,还有些槽位上挂接的链表上的元素可能会有多个。每一次遍历都会将 limit 数量的槽位上挂接的所有链表元素进行模式匹配过滤后,一次性返回给客户端。
scan 遍历顺序
scan 的遍历顺序非常特别。它不是从第一维数组的第 0 位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
首先我们用动画演示一下普通加法和高位进位加法的区别。
img
从动画中可以看出高位进位法从左边加,进位往右边移动,同普通加法正好相反。但是最终它们都会遍历所有的槽位并且没有重复。
字典扩容
Java 中的 HashMap 有扩容的概念,当 loadFactor 达到阈值时,需要重新分配一个新的 2 倍大小的数组,然后将所有的元素全部 rehash 挂到新的数组下面。rehash 就是将元素的 hash 值对数组长度进行取模运算,因为长度变了,所以每个元素挂接的槽位可能也发生了变化。又因为数组的长度是 2^n 次方,所以取模运算等价于位与操作。
css复制代码a mod 8 = a & (8-1) = a & 7 a mod 16 = a & (16-1) = a & 15 a mod 32 = a & (32-1) = a & 31这里的 7, 15, 31 称之为字典的 mask 值,mask 的作用就是保留 hash 值的低位,高位都被设置为 0。
接下来我们看看 rehash 前后元素槽位的变化。
假设当前的字典的数组长度由 8 位扩容到 16 位,那么 3 号槽位 011 将会被 rehash 到 3 号槽位和 11 号槽位,也就是说该槽位链表中大约有一半的元素还是 3 号槽位,其它的元素会放到 11 号槽位,11 这个数字的二进制是 1011,就是对 3 的二进制 011 增加了一个高位 1。
img
抽象一点说,假设开始槽位的二进制数是 xxx,那么该槽位中的元素将被 rehash 到 0xxx 和 1xxx(xxx+8) 中。 如果字典长度由 16 位扩容到 32 位,那么对于二进制槽位 xxxx 中的元素将被 rehash 到 0xxxx 和 1xxxx(xxxx+16) 中。
对比扩容缩容前后的遍历顺序
img
观察这张图,我们发现采用高位进位加法的遍历顺序,rehash 后的槽位在遍历顺序上是相邻的。
假设当前要即将遍历 110 这个位置 (橙色),那么扩容后,当前槽位上所有的元素对应的新槽位是 0110 和 1110(深绿色),也就是在槽位的二进制数增加一个高位 0 或 1。这时我们可以直接从 0110 这个槽位开始往后继续遍历,0110 槽位之前的所有槽位都是已经遍历过的,这样就可以避免扩容后对已经遍历过的槽位进行重复遍历。
再考虑缩容,假设当前即将遍历 110 这个位置 (橙色),那么缩容后,当前槽位所有的元素对应的新槽位是 10(深绿色),也就是去掉槽位二进制最高位。这时我们可以直接从 10 这个槽位继续往后遍历,10 槽位之前的所有槽位都是已经遍历过的,这样就可以避免缩容的重复遍历。不过缩容还是不太一样,它会对图中 010 这个槽位上的元素进行重复遍历,因为缩融后 10 槽位的元素是 010 和 110 上挂接的元素的融合。
渐进式 rehash
Java 的 HashMap 在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面。如果 HashMap 中元素特别多,线程就会出现卡顿现象。Redis 为了解决这个问题,它采用渐进式 rehash。
它会同时保留旧数组和新数组,然后在定时任务中以及后续对 hash 的指令操作中渐渐地将旧数组中挂接的元素迁移到新数组上。这意味着要操作处于 rehash 中的字典,需要同时访问新旧两个数组结构。如果在旧数组下面找不到元素,还需要去新数组下面去寻找。
scan 也需要考虑这个问题,对与 rehash 中的字典,它需要同时扫描新旧槽位,然后将结果融合后返回给客户端。




再结合另外一张图就可以大概了解redis的scan的原理

三.问题分析
根据上面的资料我们可以知道,scan命令的本质,其实也是遍历扫描,用游标去迭代指定范围内所有的key,虽然这种方式比keys更平滑,keys会在一次匹配中扫描所有的key,就像一个大事务,会导致redis阻塞,而scan则像是把一个大事务拆分成多个小事务,这样就不会因为有大key或者key数量过多而阻塞redis,但是效率却还是o(n),并没有加快,因此如果频繁的使用scan去扫描key,虽然不会导致redis阻塞、响应速度变慢,但是也会导致消耗大量cpu,使cpu使用率急速飙升文章来源:https://www.toymoban.com/news/detail-832715.html
四.总结
生产可以使用scan命令,但最好用在调用不是很频繁的地方,如定时任务、后台管理、不常用功能等地方,如果用在调用频繁的功能上回导致redis服务器cpu使用频繁升高。如果有些地方有扫描多个key的地方,可以换其他方案,例如set结构的union方法可以一次查询多个key的value,批量删除也可以使用unlink等等文章来源地址https://www.toymoban.com/news/detail-832715.html
到了这里,关于redis scan命令导致cpu飙升的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!