1.背景介绍
随着数据的增长,实时数据处理变得越来越重要。传统的批处理系统已经不能满足现在的需求。因此,实时数据处理技术逐渐成为了研究的热点。Kudu和Apache Flink是两个非常重要的实时数据处理系统,它们各自具有独特的优势。Kudu是一个高性能的列式存储系统,适用于实时数据处理和分析。Apache Flink是一个流处理框架,用于实时数据处理和分析。在本文中,我们将讨论Kudu与Apache Flink的集成,以及这种集成的优势和应用场景。
2.核心概念与联系
2.1 Kudu
Kudu是一个高性能的列式存储系统,它可以处理大量的实时数据。Kudu的设计目标是为了满足数据库、数据仓库和实时分析的需求。Kudu支持多种数据类型,如整数、浮点数、字符串、时间戳等。它还支持分区和索引,以提高查询性能。Kudu的核心组件包括:
- Kudu Master:负责协调和管理Kudu集群。
- Kudu Tablet Server:负责存储和处理数据。
- Kudu Client:用于与Kudu集群进行通信。
2.2 Apache Flink
Apache Flink是一个流处理框架,它可以处理大量的实时数据。Flink支持事件时间语义和处理时间语义,以满足不同应用场景的需求。Flink还支持状态管理和检查点,以确保系统的可靠性和一致性。Flink的核心组件包括:
- Flink Master:负责协调和管理Flink集群。
- Flink Worker:负责执行任务和存储状态。
- Flink Client:用于与Flink集群进行通信。
2.3 Kudu与Apache Flink的集成
Kudu与Apache Flink的集成可以让我们充分利用它们的优势,实现高性能的实时数据处理。通过将Kudu作为Flink的状态后端,我们可以实现Flink的高可靠性和一致性。同时,通过将Flink作为Kudu的数据源和接收器,我们可以实现Kudu的高性能和高吞吐量。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 Kudu与Flink的集成算法原理
Kudu与Flink的集成算法原理如下:
- Flink作为Kudu的数据源,从Kudu中读取数据。
- Flink作为Kudu的接收器,将处理结果写入Kudu。
- Flink将其状态存储在Kudu中,以实现高可靠性和一致性。
3.2 Kudu与Flink的集成算法具体操作步骤
Kudu与Flink的集成算法具体操作步骤如下:
- 配置Flink作为Kudu的数据源,通过JDBC或ODBC连接到Kudu。
- 配置Flink作为Kudu的接收器,通过JDBC或ODBC连接到Kudu。
- 配置Flink的状态后端为Kudu,通过JDBC或ODBC连接到Kudu。
- 在Flink中定义一个Kudu数据源和接收器的函数,以实现数据的读写。
- 在Flink中定义一个状态后端的函数,以实现状态的存储和查询。
- 在Flink中定义一个Job,将数据源、接收器和状态后端函数作为参数传入。
- 启动Flink Job,开始处理数据。
3.3 Kudu与Flink的集成数学模型公式详细讲解
Kudu与Flink的集成数学模型公式详细讲解如下:
- 数据源函数:$$ F(x) = KuduDataSource(x) $$
- 接收器函数:$$ G(x) = KuduReceiver(x) $$
- 状态后端函数:$$ H(x) = KuduStateBackend(x) $$
- 数据处理函数:$$ f(x) = FlinkProcessing(x) $$
- 数据处理Job:$$ J = FlinkJob(F, G, H, f) $$
- 数据处理结果:$$ R = J(D) $$
其中,$x$表示数据,$D$表示数据集,$F$表示数据源函数,$G$表示接收器函数,$H$表示状态后端函数,$f$表示数据处理函数,$J$表示数据处理Job,$R$表示数据处理结果。
4.具体代码实例和详细解释说明
4.1 代码实例
以下是一个简单的代码实例,展示了如何将Kudu与Flink集成:
```python from pyflink.datastream import StreamExecutionEnvironment from pyflink.table import StreamTableEnvironment, DataTypes from pyflink.table.descriptors import Schema, Kudu
设置环境
env = StreamExecutionEnvironment.getexecutionenvironment() t_env = StreamTableEnvironment.create(env)
配置Kudu数据源
kudusourceconf = Schema().schema( "id INT, name STRING, age INT").previewFileSystem("kudu://localhost:9000/mytable") tenv.connect(Kudu().conf(kudusourceconf)).withFormat(DataTypes.ROWFORMATS.json()).withSchema( "id INT, name STRING, age INT").createtemporarytable("kudusource")
配置Kudu接收器
kudusinkconf = Schema().schema( "id INT, name STRING, age INT").writeTo("kudu://localhost:9000/mytable") tenv.connect(Kudu().conf(kudusinkconf)).withFormat(DataTypes.ROWFORMATS.json()).withSchema( "id INT, name STRING, age INT").insertinto("kudu_sink")
配置Kudu状态后端
kudustatebackendconf = Schema().schema( "id INT, value STRING").writeTo("kudu://localhost:9000/mystate") tenv.createtemporarystate( "mystate", DataTypes.STRING(), Kudu().conf(kudustatebackend_conf))
定义数据处理函数
def process_function(row): row["age"] = row["age"] * 2 return row
定义数据处理Job
tenv.sqlupdate( "INSERT INTO kudusink SELECT * FROM kudusource WHERE age > 100").registertemporarytable( "kudusource") tenv.sqlupdate( "UPDATE mystate SET value = 'updated' WHERE id = 1").registertemporarytable( "mystate") tenv.sqlupdate( "SELECT id, name, age * 2 as age FROM kudusource WHERE age > 100").registertemporarytable( "result") tenv.toappendstream( "SELECT * FROM result", processfunction).addsink( "INSERT INTO kudusink SELECT * FROM result").registertemporarytable( "kudu_sink")
执行Job
tenv.execute("kuduflink_integration") ```
4.2 详细解释说明
上述代码实例中,我们首先设置了环境,并创建了一个表环境。然后,我们配置了Kudu数据源和接收器,以及Kudu状态后端。接着,我们定义了一个数据处理函数,并定义了一个数据处理Job。最后,我们执行了Job。
5.未来发展趋势与挑战
未来,Kudu与Apache Flink的集成将会面临以下挑战:
- 性能优化:Kudu与Flink的集成需要进一步优化,以满足大数据应用的性能要求。
- 可靠性和一致性:Kudu与Flink的集成需要确保系统的可靠性和一致性,以满足实时数据处理的需求。
- 易用性:Kudu与Flink的集成需要提高易用性,以便更多的开发者和企业可以使用。
- 扩展性:Kudu与Flink的集成需要支持扩展性,以满足大规模数据应用的需求。
未来发展趋势包括:
- 支持其他实时数据处理系统:Kudu与Flink的集成可以扩展到其他实时数据处理系统,如Apache Kafka、Apache Storm等。
- 支持其他数据存储系统:Kudu与Flink的集成可以扩展到其他数据存储系统,如Hadoop HDFS、Apache Cassandra等。
- 支持其他状态后端:Kudu与Flink的集成可以扩展到其他状态后端,如Apache HBase、Apache Cassandra等。
6.附录常见问题与解答
Q:Kudu与Flink的集成有哪些优势?
A:Kudu与Flink的集成具有以下优势:
- 高性能:Kudu是一个高性能的列式存储系统,可以提高实时数据处理的性能。
- 高可靠性:通过将Flink的状态存储在Kudu中,可以实现高可靠性和一致性。
- 易用性:Kudu与Flink的集成提供了简单的API,使得开发者可以轻松地使用它。
- 扩展性:Kudu与Flink的集成支持扩展性,可以满足大规模数据应用的需求。
Q:Kudu与Flink的集成有哪些局限性?
A:Kudu与Flink的集成具有以下局限性:
- 性能瓶颈:由于Kudu和Flink之间的通信需要经过网络,因此可能会导致性能瓶颈。
- 一致性问题:通过将Flink的状态存储在Kudu中,可能会导致一致性问题。
- 易用性问题:Kudu与Flink的集成可能会增加开发者的学习成本。
Q:Kudu与Flink的集成如何处理故障?文章来源:https://www.toymoban.com/news/detail-832804.html
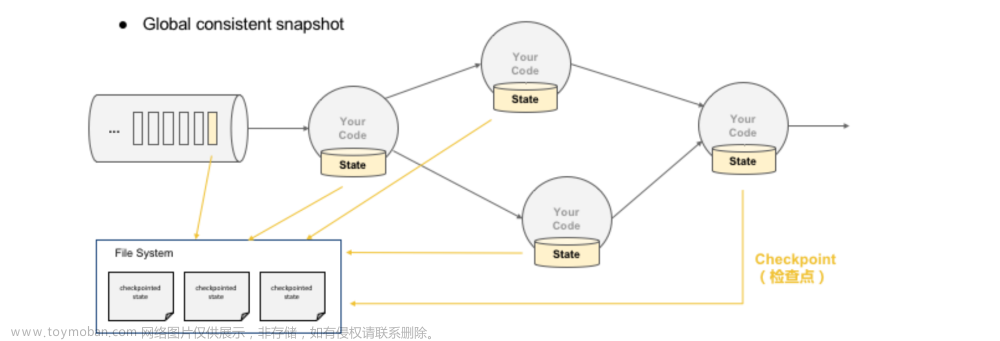
A:Kudu与Flink的集成可以通过检查点和重试机制来处理故障。当发生故障时,Flink可以从最后一次检查点的状态恢复,并重新执行失败的任务。此外,Kudu还可以通过自动故障检测和恢复来确保系统的可靠性。文章来源地址https://www.toymoban.com/news/detail-832804.html
到了这里,关于Kudu与Apache Flink的集成:实时数据处理的新方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!