英文名称: Robust Speech Recognition via Large-Scale Weak Supervision
中文名称: 通过大规模弱监督实现鲁棒语音识别
链接: https://proceedings.mlr.press/v202/radford23a.html
代码: https://github.com/openai/whisper
作者: Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever
机构: OpenAI
日期: 2022-12-06
引用次数: 1032
1 读后感
语音识别不仅用于语音输入、语音聊天,生成字幕,还在语音合成,视频分析等等领域作为工具使用,一方面需要识别不同语音,不同发音人的音频特征,还需要生成合理通顺的文本(选择多音字,标点)等等。
Whisper 是 OPENAI 提供的语音转文字的引擎,它是一个开源工具,在自己的 GPU 机器上也能搭建。Wisper 是一个多语音识别引擎,简单用过,感觉对中文识别还是很好的。下面介绍 Whisper 的实现原理。
论文使用非常大量弱监督的标注数据训练模型,这里的弱监督包含大量多语言多任务的数据,以提升语音识别的准确性和稳健性,达到与有监督微调模型同等的识别效果。其底层逻辑是使用多任务训练能提升模型的鲁棒性。
2 摘要
目标:扩展弱监督语音识别的范围,减小弱监督和有监督学习的差距。使模型不再需要根据情境精调,就可以在广泛的环境中“开箱即用”可靠地工作。
方法:通过大量多语言多任务的语音数据,利用弱监督方法,训练不需要精调的语音识别模型。
结论:当扩展到 680,000 小时的多语言和多任务监督时,生成的模型可以很好地推广到标准基准,无需任何数据集特定的微调,即可与有监督学习的结果竞争,达到了与人类接近的准确性和稳健性。
3 引言
之前的方法是使用有监督数据训练模型,约需要 1000+ 小时标注数据;而 Wav2Vec 2.0 的技术使用 1,000,000 小时的无标注数据预训练模型,再用少量标注精调模型;它的表现已经超越了之前的最好水平,特别适用在标注数据较少的情况下。
无监督数据主要训练编码器,能很好地实现音频表征,但缺乏将表征映射到可用输出的解码器,所以需要微调才能实现语音识别等任务。但在一个数据集上精调的模型往往难以泛化到其它数据集上,由此限制了模型的实用性和鲁棒性。
实验证明,与在单个数据源上训练的模型相比,在多数据集/域中以监督方式进行预训练的语音识别系统表现出更高的鲁棒性,在图像领域的应用也证明了,更大的弱监督数据集显着提高了模型的鲁棒性和泛化性。
文中提出的构建 Whisper 模型工程中,将弱监督语音识别扩展了一个数量级,达到 680,000 小时的标记音频数据。并展示了在这种规模上训练的模型可以很好地转移到现有数据集零样本,无需任何特定于数据集的微调即可获得高质量的结果。
除了数据量,训练范围还从纯英语语音识别扩展到多语言和多任务,680,000 小时的音频中,117,000 小时涵盖 96 种英语外的其他语言,以及 125,000 小时的翻译数据;并证明联合多语言和多任务训练没有缺点,甚至有好处。另外,文中 Whisper 没有使用自监督方法。
4 方法

4.1 数据预处理
利用 sequence-to-sequence 模型在语音和对应的转录文本(音频转文本)之间进行映射,训练 Whisper 模型来预测音频对应的原始文本,而无需任何显著的标准化或预处理。
多样化的数据集,涵盖了来自许多不同环境、录音设置、扬声器和语言的广泛音频分布。虽然音频质量的多样性可以帮助训练模型变得稳健,但转录质量的多样性却没有好处,因此,使用过滤方法以得到高质量的转录。例如:检测并删除机器生成的转录本;使用音频语言检测器,保证音频和文本使用的语言一致,或者作为 X->en 翻译数据使用;还使用转录文本的模糊去重复来减少训练数据集中的重复量和自动生成的内容。
将音频文件分成 30 秒的片段,并与该时间片段内发生的转录子集配对。
4.2 模型
使用现成的架构来避免将文中验证与模型改进混淆。选择了具有“编码器 - 解码器”结构的 Transformer 模型结果。
音频被重新采样到 16,000 Hz,并且在 25 毫秒窗口上以 10 毫秒的步幅计算 80 通道对数梅尔频谱图表示。对于特征归一化,将输入全局缩放到 -1 到 1 之间,预训练数据集中的均值近似为零。
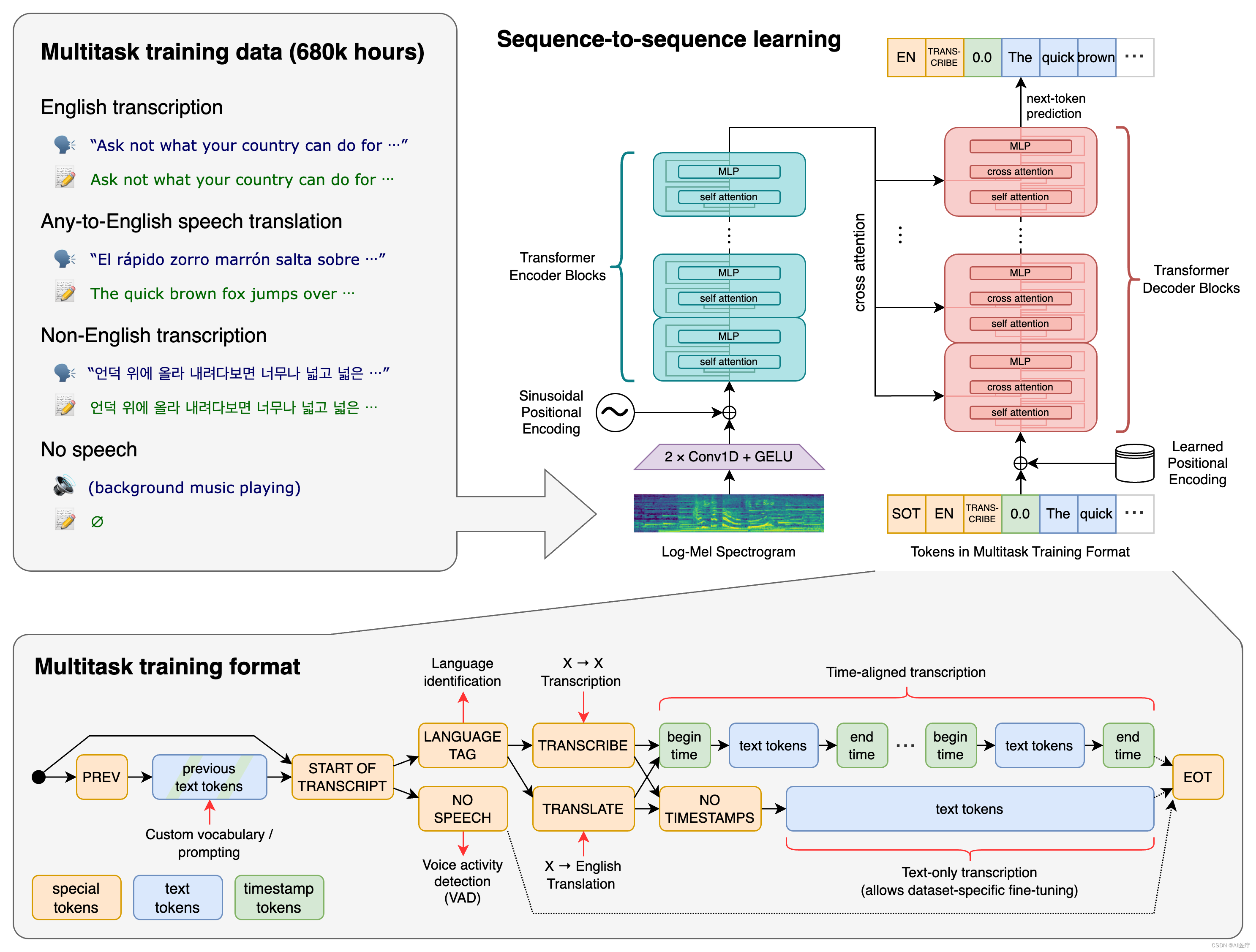
网络结构如图 -1 所示,编码器和解码器具有相同的宽度和 block 数量,音频数据转换成梅尔频谱图,再经过两个卷积层后送入 Transformer 模型。
使用 GPT-2 中的字节级 BPE 文本标记器来处理英语模型,并为多语言模型重新调整词汇表,因此也适用于其他语言。
4.3 多任务
完整的语音处理系统除了语音识别之外还涉及许多组件,从而形成一个相对复杂的交互部件系统。
由于可以对同一输入音频信号执行许多不同的任务:转录、翻译、语音活动检测、对齐和语言识别,将所有任务和条件信息指定为解码器的输入标记序列(见图 -1 右上的黄色块)。并以转录文本的历史为条件,希望它能够学习文本上下文来解决不明确的音频(Decoder 模块以之前文本作为输入)。
实际训练时,首先,使用 VoxLingua107 模型预测音频的语言,写入输入标记,加入任务标记,再指定是否预测时间戳,然后是数据。图中灰色部分展示了有时间戳处理的差异。
4.4 训练
训练了一套模型,以研究 Whisper 参数范围从 39M 到 1550M 的扩展特性。模型具体参数见论文附录,对比效果见实验部分。不使用任何数据增强或正则化,而是依靠如此大的数据集中包含的多样性来鼓励泛化和鲁棒性。
5 实验
Whisper 的目标是开发一个单一的强大语音处理系统。因此,实验的目的是检查 Whisper 是否能够很好地跨领域、任务和语言进行泛化。因此测试时不使用任何训练数据集,只在 zero-shot 设置中评估 Whisper,以衡量其强大的泛化能力。
语音识别研究通常根据词错误率(WER)指标评估系统。然而,WER 惩罚模型输出与参考文本之间的所有差异,包括文本风格上的无害差异。这个问题对于像 Whisper 这样的零样本模型尤为严重。在 WER 计算之前通过文本标准化来解决这个问题,以尽量减少非语义差异的惩罚。
人们常常需要在对所研究的特定数据几乎没有或完全没有了解的情况下完成任务。所以,人类的表现实际上是一种衡量如何在新的、未知的情况下进行推理和解决问题的能力。这就解释了为什么在特定测试中人类评分不如模型,但在实际环境中超过模型的问题。
Whisper 模型是在广泛和多样化的音频分布上进行训练并在零样本设置中进行评估的,能比现有系统更好地匹配人类行为。具有高有效鲁棒性的模型在分布外数据集上的表现优于预期,其表现取决于参考数据集上的表现,并接近于在所有数据集上表现相等的理想状态。
零样本 Whisper 模型具有与监督 LibriSpeech 模型非常不同的鲁棒性特性,并在其他数据集上远远超过所有基准 LibriSpeech 模型。与图 2 中的人类相比,最佳的零样本 Whisper 模型大致匹配其准确性和鲁棒性。


6 分析和消融
6.1 数据规模

图 -4 展示了训练规模与效果之间的关系,如在英语语音识别方面,从 3,000 小时到 13,000 小时,性能迅速提高,然后在 13,000 小时到 54,000 小时之间明显放缓。对于多语言语音识别,WER 的改进在 54,000 小时之前平稳增长,然后减少。对于 X→en 翻译,当训练 7,000 小时或更少的音频时,性能几乎为零,然后在 54,000 小时之前以大致对数线性的方式改善,之后再进一步扩展到完整数据集大小时也显示出收益递减。
6.2 模型规模
除了英语语音识别之外,多语言语音识别、语音翻译和语言识别的性能随着模型大小的增加而不断提高。英语识别的回报递减可能是由于接近人类水平表现的饱和效应所致。
6.3 多任务和多语言迁移
 文章来源:https://www.toymoban.com/news/detail-832928.html
文章来源:https://www.toymoban.com/news/detail-832928.html
对于使用适量计算资源训练的小型模型,任务和语言之间确实存在负迁移:然而,对于最大的模型来说,它们优于仅英语训练,展示了来自其他任务的正迁移。文章来源地址https://www.toymoban.com/news/detail-832928.html
到了这里,关于论文阅读_语音识别_Wisper的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!