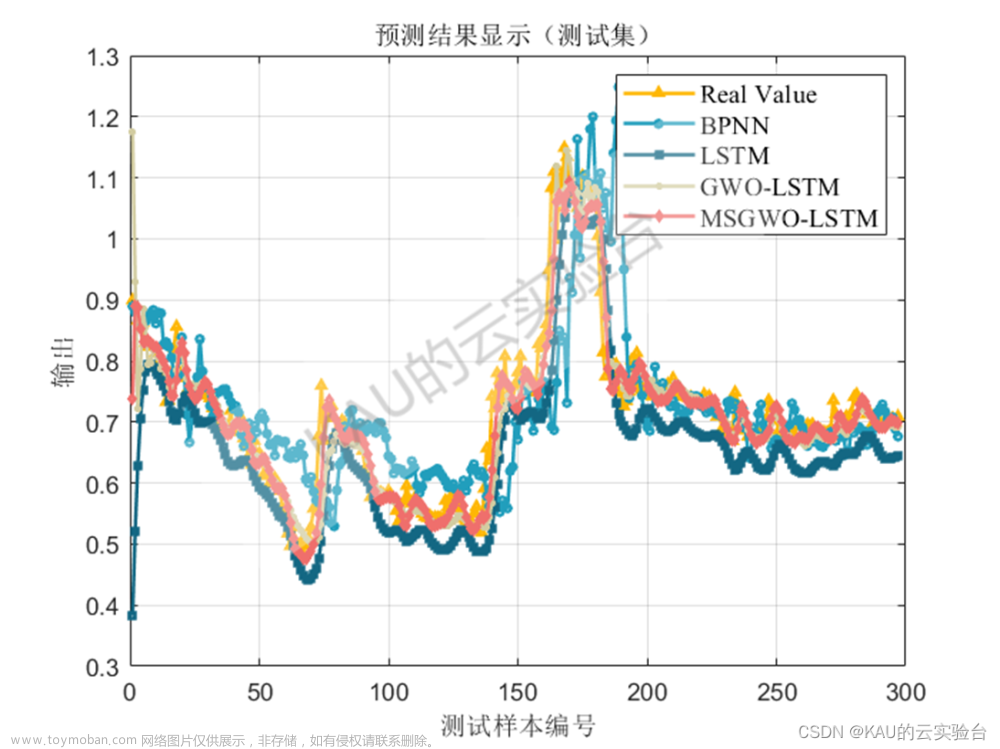
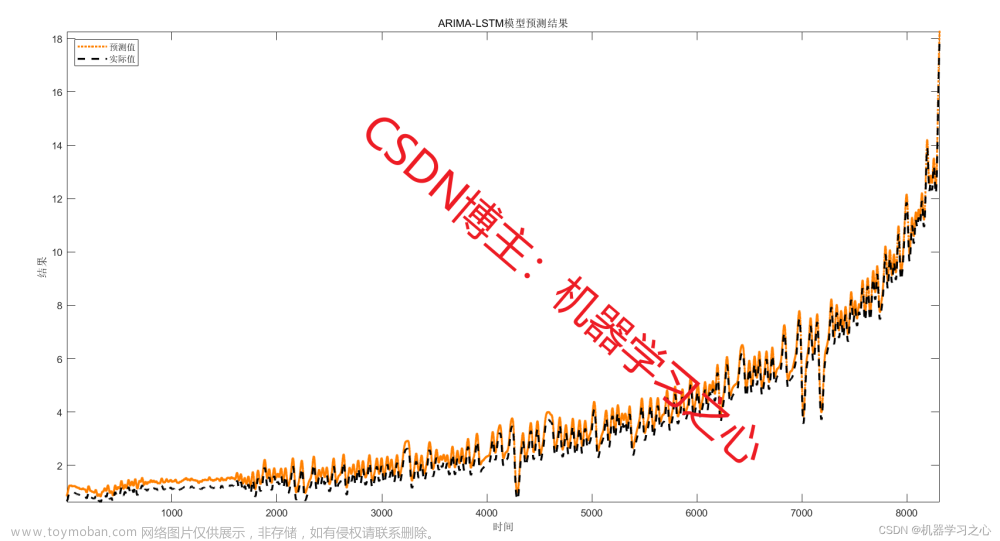
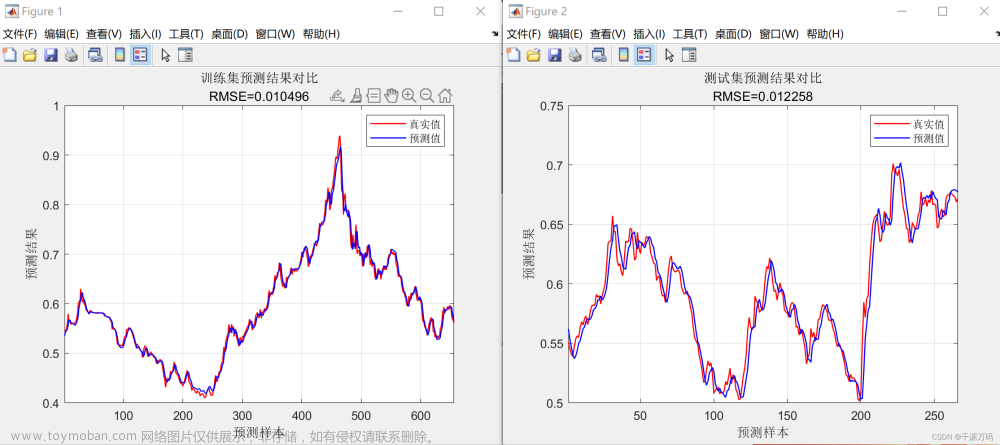
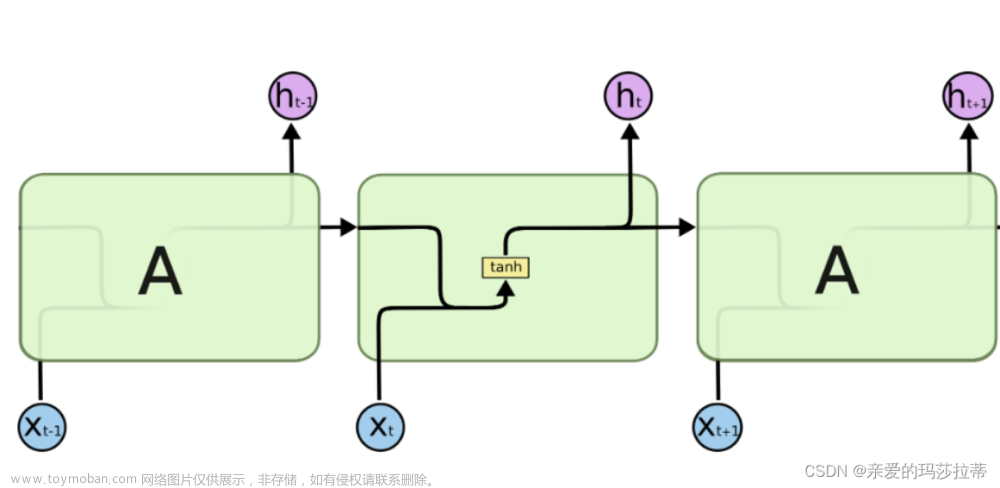
目的是将原始文本数据转换成适合LSTM模型处理的格式,并通过模型进行特征提取和分析,以完成各种自然语言处理任务:
-
原始文本(Raw Text):这是原始的文本数据,可能是一段文章、对话或任何其他形式的文本。
-
分词(Tokenization):分词是将连续的汉字序列切分成一个个独立的词或词组。由于计算机不能直接理解连续的文本,第一步是将文本分割成独立的词或标记(token)。
-
词汇编码(Dictionarization):将分词后的文本转换成数字形式,以便机器学习模型可以处理。这通常是通过创建一个词汇表(vocabulary)来实现的,词汇表中的每个词都会被分配一个唯一的数字ID。
-
填充句子到固定长度(Padding to Fixed Length):由于LSTM等循环神经网络(RNN)需要固定长度的输入,所以需要将不同长度的句子填充到相同的长度。这通常通过在句子的末尾添加填充标记(如0)来实现。
-
将词映射到词嵌入(Mapping Tokens to Embeddings):词嵌入是一种将词转换为固定大小的向量表示的技术。这些向量捕获了词之间的语义关系,每个词都被表示为一个高维空间中的点,语义上相似的词在向量空间中彼此靠近。这一步骤有助于模型理解词的意义和它们之间的关系。
-
输入到RNN(Feeding into RNN):将词嵌入作为输入传递给LSTM模型。LSTM是一种特殊的RNN,能够处理长期依赖关系,这对于处理文本数据特别重要。
-
获取输出(Getting Output):在每个时间步,LSTM都会输出一个隐状态。然而,通常我们更关心最后一个时间步的输出,因为它包含了整个序列的信息。这个输出可以用于后续的任务,如分类、回归或生成下一个词。
-
进一步处理输出(Further Processing with the Output):根据任务的不同,需要对LSTM的输出进行进一步处理。例如,对于分类任务,可以将输出传递给softmax函数以获得每个类别的概率分布。对于序列到序列的任务(如机器翻译),可以使用LSTM的隐状态来生成目标序列。文章来源:https://www.toymoban.com/news/detail-833044.html
-
简化示例(TensorFlow/Keras库):文章来源地址https://www.toymoban.com/news/detail-833044.html
import numpy as np from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Embedding, LSTM, Dense # Step 1: 原始文本 texts = [ '这是一个好的产品', '我不喜欢这个服务', '电影很糟糕', '推荐购买这本书', '这个餐厅太棒了' ] labels = [1, 0, 0, 1, 1] # 1代表正面,0代表负面 # Step 2: 分词 tokenizer = Tokenizer() tokenizer.fit_on_texts(texts) word_index = tokenizer.word_index sequences = tokenizer.texts_to_sequences(texts) # Step 3: 词汇编码 # 这里不需要额外编码,因为Tokenizer自带编码功能 # Step 4: 填充句子到固定长度 data = pad_sequences(sequences) # Step 5: 映射词到词嵌入 # 这里跳过实际的嵌入矩阵创建,直接使用随机嵌入矩阵 embedding_dim = 16 vocab_size = len(word_index) + 1 # +1 for padding token embedding_matrix = np.random.random((vocab_size, embedding_dim)) # Step 6: 喂给RNN model = Sequential() model.add(Embedding(vocab_size, embedding_dim, input_length=data.shape[1])) model.add(LSTM(32)) model.add(Dense(1, activation='sigmoid')) # 编译模型 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # Step 7: 获取输出 model.fit(data, labels, epochs=10) # Step 8: 进一步处理输出 new_sentence = '这是一个糟糕的电影' new_sequence = tokenizer.texts_to_sequences([new_sentence]) new_padded_sequence = pad_sequences(new_sequence, padding='post') # 预测情感 prediction = model.predict(new_padded_sequence) print(f"Prediction for '{new_sentence}': {np.round(prediction)}")
到了这里,关于使用LSTM(长短期记忆)模型处理文本数据的典型流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!