1. 理解分布式链路跟踪
1.1 什么是分布式链路跟踪
在分布式系统中,由于服务间的调用涉及多个节点和网络通信,出现问题时追踪问题的根源变得异常困难。分布式链路跟踪是一种技术,旨在解决这个问题。它允许开发人员追踪分布式系统中请求的流转路径,从而定位和解决性能问题、异常和错误。
1.2 分布式系统的挑战和需求
分布式系统的挑战包括但不限于网络延迟、节点故障、消息丢失等。这些挑战增加了故障排查和性能优化的复杂性。分布式链路跟踪满足了开发人员对于深入了解服务调用情况的需求,使得问题排查更加高效。
1.3 Spring Cloud Sleuth 的介绍和定位
Spring Cloud Sleuth 是 Spring Cloud 生态中的一个组件,专注于提供分布式链路跟踪解决方案。它与 Spring Cloud 的其他组件集成紧密,为开发人员提供了一种无缝地跟踪分布式系统中请求的方法。通过 Sleuth,开发人员可以轻松地监控请求的流转路径,了解请求的处理情况,并快速诊断和解决问题。同时,Sleuth 还支持与 Zipkin 等分布式跟踪系统集成,进一步提升了跟踪和监控的能力。
2. Spring Cloud Sleuth 的基础知识
2.1 分布式链路跟踪的核心概念和架构
在理解 Spring Cloud Sleuth 的基础知识之前,首先需要了解分布式链路跟踪的核心概念和架构。分布式链路跟踪通常由三部分组成:Span(跨度)、Trace(跟踪) 和 Span Context(跨度上下文)。
- Span:代表了系统中的一个操作,通常是服务调用的开始和结束,它包含了一系列的时间戳事件,描述了操作的耗时和其他属性。
- Trace:由一系列相关的 Span 组成,形成了一个完整的请求路径,用于描述整个请求的流转路径。
- Span Context:用于跨度之间的上下文传递,包含了跨度的标识符等信息,确保在不同节点间跟踪请求的一致性。
Spring Cloud Sleuth 架构上建立在这些核心概念之上,通过在服务调用时生成并传递 Span 和 Trace,实现了分布式链路跟踪的功能。
2.2 Sleuth 的跟踪模型和原理
Spring Cloud Sleuth 的跟踪模型基于 OpenTracing 标准,使用了一种称为 Brave 的库来实现。它通过在服务调用时生成 Span 和 Trace,利用 ThreadLocal 或者 MDC(Mapped Diagnostic Context)来传递跨度上下文,确保在不同节点上对请求的跟踪。Sleuth 还通过集成各种传输方式(如 HTTP、消息队列等)来传递跨度信息,确保了在分布式系统中的全链路跟踪。
2.3 Sleuth 的主要组件和功能
Spring Cloud Sleuth 提供了一系列主要组件和功能,包括:
- Trace 和 Span 的生成与传递:Sleuth 在服务调用时自动创建和传递 Span 和 Trace,无需开发人员手动介入。
- 集成支持:Sleuth 与 Spring Cloud 的各种组件集成紧密,如 Spring Boot、Spring Cloud Gateway、Spring Cloud Stream 等。
- 自定义采样率:开发人员可以根据需求自定义采样率,控制哪些请求需要进行跟踪,以减轻跟踪系统的负担。
- 集成 Zipkin:Sleuth 提供了与 Zipkin 的集成支持,将跟踪数据发送到 Zipkin 服务器进行存储和展示,从而实现了分布式链路跟踪的可视化和深度分析。
总的来说,Spring Cloud Sleuth 提供了一套完整的分布式链路跟踪解决方案,帮助开发人员轻松地实现分布式系统的监控和问题排查。
3. 集成 Spring Cloud Sleuth
3.1 在 Spring Boot 中添加 Sleuth 依赖
要集成 Spring Cloud Sleuth,首先需要在 Spring Boot 项目中添加相应的依赖。在 Maven 项目中,可以通过以下方式添加 Sleuth 依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
在 Gradle 项目中,可以通过以下方式添加 Sleuth 依赖:
implementation 'org.springframework.cloud:spring-cloud-starter-sleuth'
添加依赖后,Sleuth 将会自动启用,开始跟踪服务间的调用。
3.2 配置 Sleuth 的参数和采样率
Spring Cloud Sleuth 提供了一系列配置参数,可以根据实际需求进行定制。其中,一个重要的参数是采样率(sampling rate),它决定了哪些请求会被跟踪。可以通过配置参数来调整采样率,例如:
spring:
sleuth:
sampler:
probability: 0.5
上述配置将会以 50% 的概率采样请求进行跟踪。
3.3 搭建 Sleuth 的数据收集和存储环境
Spring Cloud Sleuth 默认集成了 Brave 库,可以方便地将跟踪数据发送到 Zipkin 服务器进行存储和展示。要使用 Zipkin,可以通过以下方式搭建环境:
- 下载并运行 Zipkin 服务器:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
- 在 Spring Boot 项目中添加 Zipkin 依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
- 配置 Zipkin 服务器地址:
spring:
zipkin:
baseUrl: http://localhost:9411
完成以上步骤后,Sleuth 将会自动将跟踪数据发送到 Zipkin 服务器进行存储和展示。
4. 实现分布式跟踪
4.1 使用 Sleuth 跟踪服务间调用
Spring Cloud Sleuth 的核心功能之一是自动跟踪服务间的调用。在微服务架构中,服务通常通过 REST API 或消息队列进行通信。Sleuth 可以在这些通信发生时自动创建并传递 Span 和 Trace,以实现全链路跟踪。
例如,在一个服务 A 中调用另一个服务 B,只需要确保 Sleuth 已经集成到两个服务中,Sleuth 就会自动在请求中创建并传递跟踪信息。
// 服务 A 的代码示例
@RestController
public class ServiceAController {
private final RestTemplate restTemplate;
public ServiceAController(RestTemplate restTemplate) {
this.restTemplate = restTemplate;
}
@GetMapping("/call-service-b")
public String callServiceB() {
return restTemplate.getForObject("http://service-b/api/resource", String.class);
}
}
// 服务 B 的代码示例
@RestController
public class ServiceBController {
@GetMapping("/api/resource")
public String getResource() {
return "Resource from Service B";
}
}
4.2 配置 Sleuth 跟踪的数据格式和标识
Spring Cloud Sleuth 支持配置跟踪数据的格式和标识,以满足不同场景下的需求。可以通过配置文件或代码来调整跟踪信息的格式和标识。
例如,可以配置 Sleuth 使用自定义的 Trace ID 和 Span ID 格式:
spring:
sleuth:
baggage-keys:
- customKey1
- customKey2
traceId128: true
spanId128: true
4.3 解析 Sleuth 跟踪的数据并进行可视化展示
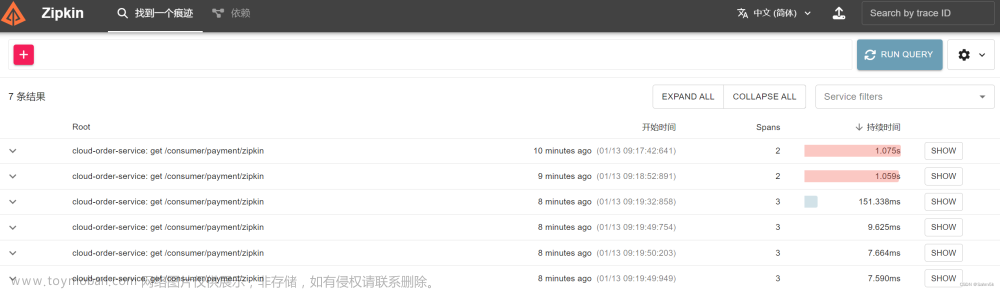
Spring Cloud Sleuth 集成了 Zipkin,可以方便地将跟踪数据发送到 Zipkin 服务器进行存储和展示。可以通过访问 Zipkin 的 Web 界面来查看跟踪数据的可视化展示,并进行深度分析和故障排查。
Zipkin 提供了丰富的查询功能,可以根据 Trace ID、时间范围、服务名等条件来搜索和过滤跟踪数据,并展示请求的完整流转路径和耗时信息。
通过分析 Zipkin 中的跟踪数据,开发人员可以快速定位和解决分布式系统中的性能问题、异常和错误。
5. 链路跟踪的优化和扩展
5.1 使用 Zipkin 进行链路数据的存储和展示
Zipkin 是一个开源的分布式链路跟踪系统,它可以帮助开发人员收集、存储和展示分布式系统的链路数据。与 Sleuth 集成后,Sleuth 会自动将跟踪数据发送到 Zipkin 进行存储和展示。Zipkin 提供了直观的 Web 界面,可以查看请求的完整流转路径、服务间的调用关系以及请求的耗时信息。
5.2 配置 Sleuth 链路跟踪的数据采集和传输
Spring Cloud Sleuth 提供了丰富的配置选项,可以根据实际需求配置链路跟踪的数据采集和传输方式。可以通过配置文件或代码来指定数据的采集频率、传输协议和目的地。例如,可以配置 Sleuth 使用 HTTP 协议将跟踪数据发送到 Zipkin 服务器:
spring:
zipkin:
baseUrl: http://zipkin-server:9411
5.3 使用 Sleuth 配合 Zipkin 实现链路数据的深度分析
Spring Cloud Sleuth 与 Zipkin 集成紧密,可以实现链路数据的深度分析。通过分析 Zipkin 中的跟踪数据,可以了解系统的请求流转路径、服务间的调用关系以及请求的处理耗时。开发人员可以利用 Zipkin 提供的丰富功能,如依赖分析、耗时统计、异常检测等,对系统的性能进行全面评估,并针对性地进行优化和改进。
6. 分布式事务和异常追踪
6.1 Sleuth 在分布式事务中的应用
在分布式系统中,分布式事务是一个常见的挑战。由于事务涉及多个服务的协同操作,因此需要对事务进行跟踪和管理,以保证事务的一致性和可靠性。Spring Cloud Sleuth 可以与分布式事务管理框架(如 Atomikos、Bitronix 等)集成,实现对分布式事务的跟踪和监控。
6.2 使用 Sleuth 追踪分布式系统的异常
异常追踪是分布式系统监控的重要组成部分。Spring Cloud Sleuth 可以帮助开发人员追踪分布式系统中的异常,及时定位并解决问题。通过 Sleuth,开发人员可以记录异常发生时的跟踪信息,包括异常所在的服务、请求的流转路径、请求参数等。这些信息可以帮助开发人员快速定位异常的原因,并进行修复。
6.3 配置 Sleuth 实现异常信息的收集和汇总
Spring Cloud Sleuth 提供了丰富的配置选项,可以根据实际需求配置异常信息的收集和汇总。可以通过配置文件或代码来指定异常信息的记录方式、存储位置和汇总策略。通过配置 Sleuth,开发人员可以实现对分布式系统异## 7. 分布式监控与性能优化
7. 分布式监控与性能优化
7.1 监控 Sleuth 的跟踪数据和性能指标
在分布式系统中,监控是保证系统稳定性和性能的关键。Spring Cloud Sleuth 提供了丰富的监控指标,可以帮助开发人员了解系统的运行情况和性能表现。可以使用监控系统(如 Prometheus、Grafana 等)来收集和展示 Sleuth 生成的跟踪数据和性能指标。
通过监控 Sleuth 的跟踪数据和性能指标,开发人员可以实时了解系统的运行状态、识别潜在的性能问题,并及时进行调优和优化。
7.2 使用 Sleuth 进行性能优化和瓶颈排查
Spring Cloud Sleuth 提供了丰富的性能数据和跟踪信息,可以帮助开发人员进行性能优化和瓶颈排查。通过分析 Sleuth 生成的跟踪数据,开发人员可以了解系统中的瓶颈所在、请求的处理耗时情况等。
可以使用 Sleuth 提供的性能数据来识别系统的性能瓶颈,并针对性地进行优化和改进。例如,通过优化服务间调用、减少网络延迟、优化数据库查询等方式来提升系统的性能。
7.3 配置 Sleuth 实现分布式系统的健康监控
除了监控跟踪数据和性能指标外,还可以配置 Sleuth 实现分布式系统的健康监控。Spring Cloud Sleuth 可以与健康监控系统(如 Spring Boot Actuator、Prometheus 等)集成,实现对系统的健康状态的实时监控。文章来源:https://www.toymoban.com/news/detail-833123.html
通过配置 Sleuth 实现健康监控,开发人员可以及时发现系统中的异常情况、预防系统的故障发生,并采取相应的措施进行处理。文章来源地址https://www.toymoban.com/news/detail-833123.html
到了这里,关于Spring Cloud Sleuth:分布式链路跟踪的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!