哈希表
概述
给美分数据分配一个编号,放入表格(数组)
建立编号与表格索引的关系,将来就可以通过编号快速查找数据
- 理想情况编号当唯一,数组能容纳所有数据
- 现实是不能说为了容纳所有数据造一个超大数组,编号也可能重复
解决
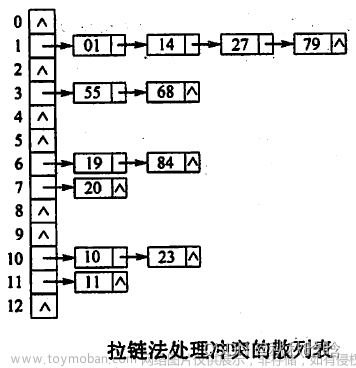
- 有限长度的数组,以[拉链]方式存储数据
- 允许编号适当重复,通过数据自身来进行区分
代码
基础代码
public class HahTable {
//节点类
static class Entry{
int hash; //哈希码
Object key; //键
Object value; //值
Entry next;
public Entry(int hash, Object key, Object value) {
this.hash = hash;
this.key = key;
this.value = value;
}
}
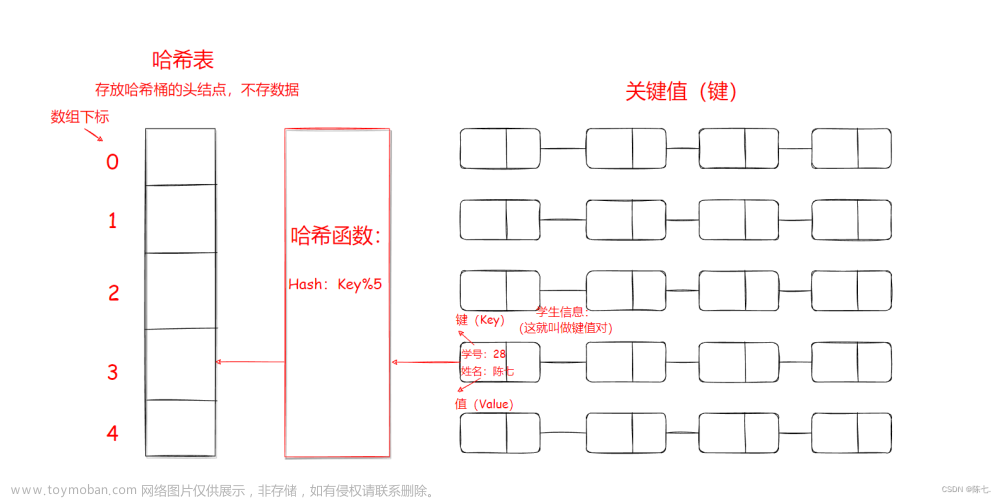
//创建一个数组,数组里面装的是Entry节点,也就是链表的头节点
Entry[] table = new Entry[16];
int size = 0; //元素个数
}获取

这里实际上可以使用取余运算,如果key值是9,8对数组的长度进行求余数,可以得出来是0,所以可以在数组0的那根链表上继续进行查找
可以看出索引3位置处就没有元素,返回的就是null
//根据hash码获取value
private Object get(int hash,Object key){
//hash码与数组的长度减一,实际上取到的就是索引值
int index = hash & (table.length - 1);
//如果数组的该索引位置处没有值的话,也不会有对应的value值,所以可以直接返回
if(table[index] == null){
return null;
}
//将table数组处index索引位置处的链表找到
Entry p = table[index];
//遍历链表
while (p != null){
//如果链表的key和传过来的key值相等的话可以直接将key值当值节点返回
if(p.key.equals(key)){
return p;
}
p = p.next;
}
//找到最后都没有的话,返回null值
return null;
}插入
插入实际上也是,索引3位置处并没有内容,所以可以直接插入,而其他索引位置处就需要找到链表进行对应的位置插入了
//向hash表存入新的key,value,如果key重复,则更新value
private void put(int hash,Object key,Object value){
//hash码与数组的长度减一,实际上取到的就是索引值
int index = hash & (table.length - 1);
//接下来会有两种情况
//第一种:index索引位置处有空位置,直接新增
if(table[index] == null){
table[index] = new Entry(hash,key,value);
}else{
//第二种:index索引位置处没有空位,沿着链表查找,有key值的话,更新,没有的话新增
Entry p = table[index];
//遍历链表
while (true){
//如果链表的key和传过来的key值相等的话可以直接将key值当值节点返回
if(p.key.equals(key)){
p.value = value;
return;
}
if(p.next == null){
break;
}
p = p.next;
}
//此时的p就是最后一个节点
p.next = new Entry(hash,key,value);
}
size++;
}删除
//根据hash码删除,返回删除的value
private Object remove(int hash,Object key){
//hash码与数组的长度减一,实际上取到的就是索引值
int index = hash & (table.length - 1);
//如果数组的index位置处为null,直接返回null
if(table[index] == null){
return null;
}
//找到数组索引位置处的链表
Entry p = table[index];
Entry prev = null;//设置删除节点的父节点
while (p != null){
if(p.key.equals(key)){
//找到了删除节点
//如果删除的是头节点的话,将数组索引位置处的元素设置为链表头节点的下一个元素
if(prev == null){
table[index] = p.next;
}else{
//如果不是的话,将父节点的next指向儿子节点的next,这样就把儿子节点忽略掉了
prev.next = p.next;
}
return p.value;
}
prev = p; //将当前节点设置称为删除节点的父节点
p = p.next;
}
return null;
}此时会出现一个问题,就是如果说元素内容并不多,但是数组长度会很长则造成了空间的浪费,如果说数组长度不长,但是元素足够多就会导致增删改查的效率变低,所以需要在合适的时候对数组进行扩容,这里就引出了一个新的名词负载因子
扩容
负载因子公式如下图所示

- 从上面可以看出n代表的是元素的个数,m代表的是数组的长度,他们的比值最好在4分之3左右
- 扩容之后一般采取的办法是容量进行翻倍

float loadFactor = 0.75f;//负载因子大小 12称为阈值
int threshold =(int) (loadFactor * table.length);//这个实际上计算的实际上就是阈值
//向hash表存入新的key,value,如果key重复,则更新value
private void put(int hash,Object key,Object value){
//hash码与数组的长度减一,实际上取到的就是索引值
int index = hash & (table.length - 1);
//接下来会有两种情况
//第一种:index索引位置处有空位置,直接新增
if(table[index] == null){
table[index] = new Entry(hash,key,value);
}else{
//第二种:index索引位置处没有空位,沿着链表查找,有key值的话,更新,没有的话新增
Entry p = table[index];
//遍历链表
while (true){
//如果链表的key和传过来的key值相等的话可以直接将key值当值节点返回
if(p.key.equals(key)){
p.value = value;
return;
}
if(p.next == null){
break;
}
p = p.next;
}
//此时的p就是最后一个节点
p.next = new Entry(hash,key,value);
}
size++;
if(size > threshold){
resize();
}
}
/**
* 扩容方法
*/
private void resize() {
Entry[] newTable = new Entry[table.length << 1]; //移位比直接乘以2效率更高
for (int i = 0; i < table.length; i++) {
Entry p = table[i];
if(p != null){
//拆分链表,移动到新的数组
/*
拆分规律
* 一个链表最多拆成两个
* hash & table.length == 0 的一组
* hash & table.length != 1 的一组
*/
}
}
table = newTable;//扩容完成之后将新数组赋值给旧数组
threshold = threshold =(int) (loadFactor * table.length);
}讲到这里就需要科普一个知识了
0 (二进制: 0000) & (按位与) 8 (二进制: 1000) 结果08 (二进制: 1000) & (按位与) 8 (二进制: 1000) 结果8
16 (二进制: 10000) & (按位与) 8 (二进制: 1000) 结果0
24 (二进制: 11000) & (按位与) 8 (二进制: 01000) 结果8
可以看出如果最后四位的值相等的时候结果为8,否则结果为0

/**
* 扩容方法
*/
private void resize() {
// 创建新的Entry数组,长度为原数组的两倍(通过位运算效率更高)
Entry[] newTable = new Entry[table.length << 1];
// 遍历原数组
for (int i = 0; i < table.length; i++) {
Entry p = table[i];
// 如果当前位置有链表
if(p != null){
// 拆分链表,移动到新的数组
/*
拆分规律
* 一个链表最多拆成两个
* hash & table.length == 0 的一组
* hash & table.length != 1 的一组
*/
// 创建两个新的链表,一个是a,另一个是b
Entry a = null;
Entry b = null;
Entry aHead = null;
Entry bHead = null;
// 递归遍历链表
while (p != null){
// 如果当前节点的hash与数组的长度 == 0的时候添加到a,否则添加到b
if((p.hash & table.length) == 0){
if(a != null){
a.next = p;
}else{
aHead = p;
}
// 分配到a
a = p;
}else{
if(b != null){
b.next = p;
}else{
bHead = p;
}
// 分配到b
b = p;
}
// 进行递归遍历
p = p.next;
}
// 将链表a添加到新数组的原位置
if(a != null ){
a.next = null;
newTable[i] = aHead;
}
// 将链表b添加到新数组的原位置的后半部分
if(b != null ){
b.next = null;
newTable[i + table.length] = bHead;
}
}
}
// 扩容完成之后将新数组赋值给旧数组
table = newTable;
// 更新阈值
threshold = (int) (loadFactor * table.length);
}
哈希算法
概述
hash算法是将任意对象,分配一个编号的过程,其中编号是一个有限范围内的数字(如int范围内),hash算法是一种将任意长度的数据通过一个算法,变成固定长度数据的过程,这个固定长度的数据就是hash值。hash算法可以将任意大小的数据压缩到固定大小的值。常见的hash算法有MD5、SHA1、SHA256、SHA512、CRC32等。其中,MD5和SHA系列算法是最常用的hash算法。这些算法在计算hash值时,都考虑了原始数据的每一个字节,一旦改动原始数据的任何一个字节,所得到的hash值都会有明显的不同。因此,hash算法被广泛应用于数据完整性校验和加密等方面。
 文章来源:https://www.toymoban.com/news/detail-833514.html
文章来源:https://www.toymoban.com/news/detail-833514.html
在java里面可以调用对象的HashCode方法来进行获取文章来源地址https://www.toymoban.com/news/detail-833514.html
字符串生成hash的方法
public static void main(String[] args) {
String str = "abc";
System.out.println(str.hashCode());
System.out.println("==================");
int hash = 0;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
hash = hash * 31 +c;
}
System.out.println(hash);
}到了这里,关于Java实现数据结构哈希表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!