PostgreSQL
模式
物品具有唯一标识符、唯一图像标识符、名称和价格。


仓库具有唯一标识符、名称以及由街道、城市和国家定义的位置。


对于每个可用的物品,我们记录每个仓库中的库存数量。如果某个物品在仓库中不可用,则这对没有记录。数量总是等于或大于1。


PostgreSQL 内部
在印度尼西亚有多少单位的阿司匹林库存?

PostgreSQL架构包括以下组件。 SQL解析器和重写器接收SQL查询并将其转换为准备优化的解析树。 规划器/优化器生成查询执行计划。 执行引擎执行计划。 内存和存储管理系统管理主存储和辅助存储。

规划器/优化器生成查询执行计划。它使用目录和统计信息来设计候选计划并估算各自的成本。它选择估计成本最低的计划。
执行计划是一个有向无环图或物理代数运算符的树,如顺序扫描、索引扫描、排序和聚合运算符、嵌套循环、哈希和合并连接。

执行引擎执行计划,访问数据和索引并执行必要的运算符、函数和程序。
pgAdmin 4指示的总查询时间包括查询规划时间、查询执行时间、网络延迟和客户端开销。
Explain
EXPLAIN命令生成并显示PostgreSQL规划器为提供的语句生成的带注释的执行计划。
带(VERBOSE)选项的EXPLAIN命令显示带有更多细节的带注释的执行计划。
EXPLAIN命令仅支持以下SQL构造:SELECT, INSERT, UPDATE, DELETE, EXECUTE(预备语句的执行)、CREATE TABLE 和 DECLARE(游标的声明)
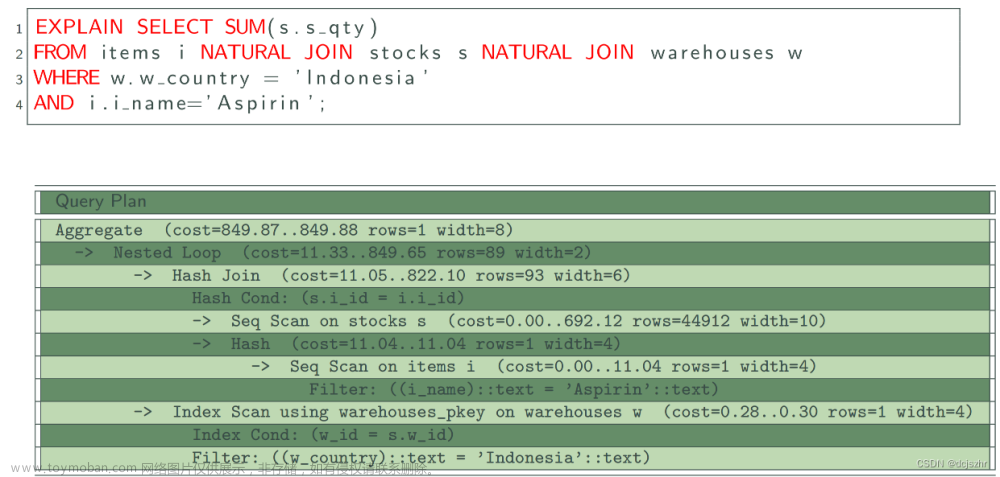

在计划的每个节点,EXPLAIN提供三个估算:成本、行数、宽度。
- 成本:成本属性是执行节点(及其子节点)在查询执行计划中的估计启动(在产生任何输出之前)成本和总成本。这两种成本用任意单位(大致与估计时间成比例)表示。成本越低通常表示计划更高效。成本包括估计的中央处理单元成本和与执行节点相关的估计的主要和次要输入输出成本。它们不包括传输到客户端的成本。
- 行数:行数属性是节点返回的估计行数。
- 宽度:宽度属性是节点产生的行的估计平均宽度(以字节为单位)。
行数和宽度的乘积估计了结果集的总数据量。
执行计划是由执行引擎执行的计划。规划器/优化器已使用估算来选择查询的执行计划。 估算可能不总是与实际运行时行为匹配。
通过考虑执行计划和估算,程序员获得了数据库引擎如何操作数据、使用索引和执行其他操作来执行语句的见解,关于估计的成本,以及规划器/优化器可用的信息。程序员可以查看不同查询的执行计划和估算,尝试了解如何在必要时调整SQL代码。
系统目录和统计数据
PostgreSQL查询规划器/优化器使用PostgreSQL构建(并维护)的目录和统计信息。 查看系统目录表和视图,如pg_tables、pg_attribute、pg_statistic和pg_stats。

例如,视图pg_stats记录Kota Kinabalu是w_city列的最常见值,估计频率为0.0059701493(在1005行的表中对应六次出现),其次是吉隆坡。 在其他统计信息中,它还记录了EXPLAIN的属性宽度中使用的列的平均宽度(9字节)。
ANALYZE
带(ANALYZE)的EXPLAIN命令执行查询并显示每一步的执行时间和行数。
这与ANALYZE命令不同。


在计划的每个节点,EXPLAIN (ANALYZE)提供四个测量值:实际时间、行数、循环次数和过滤器移除的行数。
- 成本:实际时间属性是节点的平均启动和总执行时间(以毫秒为单位)。
- 行数:行数属性是节点返回的行数。
- 宽度:循环是节点(子计划)执行的次数。
- 过滤器移除的行数:过滤器移除的行数是被条件过滤掉的行数。
- 将节点的总实际时间与循环次数相乘,得到节点的总时间。
EXPLAIN (ANALYZE)给总时间增加了开销。
执行时间从一次执行到另一次执行会有所不同。必须平均这些测量值。
成本和实际时间以不同的单位表示。如果估计良好,它们应该大致相当。

EXPLAIN (ANALYZE)还给出了规划和执行时间。执行时间包括执行启动、关闭时间以及处理结果行所花费的时间。
其他EXPLAIN选项包括COSTS, SETTINGS, GENERIC_PLAN, BUFFERS, WAL, TIMING, SUMMARY, 和 FORMAT { TEXT | XML | JSON | YAML }。 为了很好地理解性能,程序员应该多次运行查询并查看平均值。收集统计数据。页面被带到主内存缓冲区。VACUUM, ANALYZE, 和 VACCUM ANALYZE命令重新组织数据并收集统计信息。成本、时间和计划随之改变(得到改善)。
pgAdmin 4
pgAdmin 4的工具栏中的Explain和Explain Analyze按钮分别生成执行计划和生成并执行执行计划。可以切换解释选项。

图形化
“Explain > Graphical”标签显示执行计划的图形版本。可以以可伸缩矢量图形(.svg)格式下载。
统计
“Explain > Statistics”和“Explain > Statistics”标签显示分析和进一步的统计,特别是在分析模式下。
顺序扫描
找出新加坡市的仓库名称


Postgres默认页面大小为8KB。
如果统计数据表明需要检索的数据量大或分散,并且如果不可能或不值得尝试准备并使用顺序扫描以外的其他方法,则优化器会使用顺序扫描。


排序




为什么这是不良优化?
索引
索引是指导数据访问的数据结构。索引可能加速或不加速查询、删除和更新。它通常会减慢插入和更新的速度(因为必须更新数据和索引,并可能需要重新组织)。
- PostgreSQL支持B-tree(默认)、Hash、广义搜索树(GiST)、空间划分广义搜索树(SP-GiST)、广义倒排(GIN)和块范围(BRIN)索引。
- 在PostgreSQL中,索引是次要的,即它们独立于表存储。通常,在搜索索引时,必须从索引和表(堆)中获取数据。尽管满足某一条件的索引条目通常位于彼此附近,但相应的表行可能位于任何地方。
- PostgreSQL支持仅通过索引解答查询的索引仅扫描。当查询仅引用存储在索引中的列时,即当索引是覆盖索引时,索引仅扫描适用于B-tree索引(有时适用于其他索引)。
PostgreSQL自动为每个唯一和主键约束创建一个B-tree唯一索引。索引强制实施唯一性(对插入和更新额外成本)。
索引是唯一或主属性的覆盖索引。
- PostgreSQL不为外键约束创建索引。
设计者决定是否在引用列上创建索引以及创建什么索引。引用表的插入和更新需要扫描引用表。在引用列上创建索引可能是个好主意。然而,外键属性通常是(复合)键的组成部分,因此作为此类索引。
目录表和视图pg_index和pg_indexes存储数据库中索引的信息。 我们创建一个视图,从目录表和视图中收集有关索引的信息。


我们可以在items的i_price属性上创建一个索引。

我们在PostgreSQL的CREATE INDEX命令中突出显示了一些重要参数。

- UNIQUE检查重复值。
- method可以是btree(默认)、hash、gist和其他索引类型(见上文)。
- predicate定义了一个部分索引。
索引扫描
创建索引-查询
找出标识符为123的仓库的名称。


如果统计数据表明需要检索的数据量很小且可用索引提供直接访问,则优化器使用索引扫描。

位图堆扫描-创建索引
在warehouse的w_city属性上创建一个B-tree索引(默认)。


位图索引扫描
如果统计数据表明需要检索的数据量适中且可用索引,则基于索引构建的位图可能提供某种直接访问。优化器使用位图堆扫描。

位图索引扫描通过PostgreSQL中的位图索引扫描后跟位图堆扫描来实现。位图索引通常用于存在多个条件或处理低基数列时。
我们可以使用索引对表进行聚类。如果有更新,这需要定期进行。Postgres不会动态维护聚类表!

多列索引
多列索引可用于索引扫描。

即使只有部分条件,也可以使用多列索引进行索引扫描。

这只有在条件涉及多列索引的前缀(从左到右的属性)时才有效。

索引仅扫描
根据查询,扫描可能仅在索引内完成,而无需访问数据。这称为索引仅扫描。


同样,对于多列索引,这取决于前缀

可以通过在索引中包含更多列来促进索引仅扫描

何时发生?
找出物品和仓库,其中物品数量低于100。

1. 顺序扫描

2. 创建索引
在stocks的s_qty属性上创建一个B-tree索引。

有了索引和充分的统计数据,优化器可以选择使用从索引构造的位图。

即使有了索引和充分的统计数据,优化器也可以选择顺序扫描。

有了索引和充分的统计数据,优化器可以选择使用索引进行索引扫描,但它没有...

条件不具选择性
s.s_qty >= 100:估计有38222行中的44912行(85%)满足条件。 优化器选择顺序扫描。
条件适度选择性
s.s_qty < 100:估计有6690行中的44912行(15%)满足条件。 优化器选择位图堆扫描。
条件非常选择性
s.s_qty >= 1000:估计有37行中的44912行(不到0.1%)满足条件。优化器曾经选择索引扫描,但现在选择位图堆扫描。文章来源:https://www.toymoban.com/news/detail-833614.html


 文章来源地址https://www.toymoban.com/news/detail-833614.html
文章来源地址https://www.toymoban.com/news/detail-833614.html
到了这里,关于了解您的数据库管理系统及其优化器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!