1.背景介绍
人工智能(Artificial Intelligence, AI)是一门研究如何让机器具有智能行为的科学。在过去的几十年里,人工智能研究主要集中在规则-基于的系统、知识-基于的系统以及黑盒模型。然而,在过去的几年里,一种新的人工智能技术已经吸引了广泛的关注:神经网络。神经网络是一种模仿生物大脑结构和工作原理的计算模型,它已经证明在许多任务中具有超越传统方法的能力。
在本文中,我们将探讨神经网络的核心概念、算法原理、数学模型以及实际应用。我们还将讨论未来的发展趋势和挑战,并尝试回答一些常见问题。
1.1 神经网络的历史
神经网络的历史可以追溯到1940年代,当时的一些科学家试图用数学模型来描述生物神经元的行为。然而,直到1980年代,随着计算能力的提高,神经网络开始被广泛应用于计算机视觉、语音识别和自然语言处理等领域。
1986年,迈克尔·帕特尔(Geoffrey Hinton)、戴维·赫兹莱(David Rumelhart)和罗伯特·威廉姆斯(Ronald Williams)发表了一篇名为“并行散列机构:学习、表示和推理”的论文,这篇论文被认为是启动神经网络研究的关键。
1998年,帕特尔和他的团队在图像识别领域取得了一项重要的成功,他们的神经网络能够识别手写数字,错误率只有1%,这比人类更准确。这一成果吸引了大量的研究者和资金,从而推动了神经网络技术的快速发展。
2012年,Google的DeepMind团队开发了一种名为“深度Q学习”(Deep Q-Learning)的算法,这个算法让一种名为“阿尔法倾向”(AlphaGo)的神经网络在围棋游戏Go中击败了世界顶级玩家。这一事件被认为是人工智能历史上的一个重要里程碑,因为Go是一种非常复杂且需要深度 strategizing 的游戏。
1.2 神经网络的基本组成部分
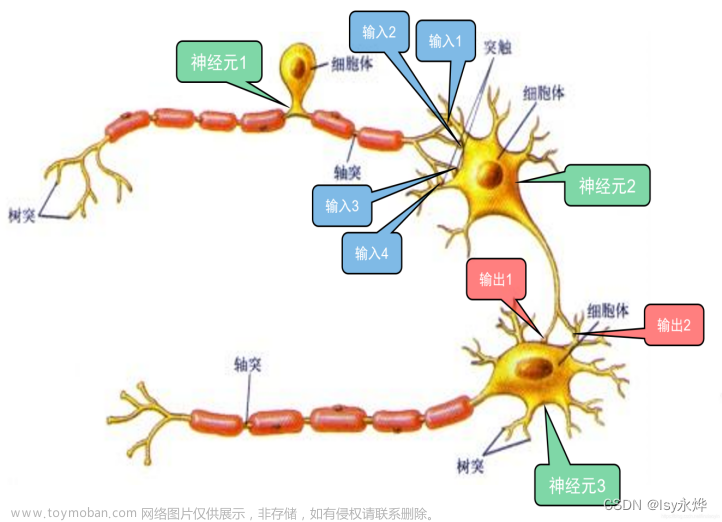
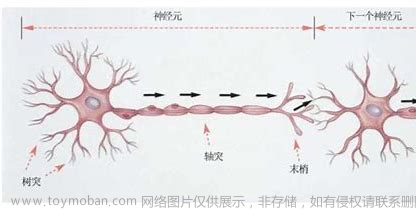
神经网络由多个相互连接的节点组成,这些节点被称为神经元(Neurons)或单元(Units)。这些神经元通过连接形成层(Layers),通常有输入层、隐藏层和输出层。神经网络通过接收输入、进行计算并输出结果来完成任务。
1.2.1 神经元
神经元是神经网络中的基本构建块。每个神经元接收来自其他神经元的输入信号,并根据其内部参数对这些信号进行处理,最终产生一个输出信号。
神经元的基本结构如下:
- 输入:来自其他神经元的信号。
- 权重:每个输入信号与神经元内部参数之间的相关性,通常用数字表示。
- 激活函数:对输入信号进行处理的函数,将线性的输入信号转换为非线性的输出信号。
- 输出:由激活函数处理后的输出信号。
1.2.2 层
神经网络中的层是一组相互连接的神经元。根据层与输入和输出之间的关系,神经网络可以分为三种类型的层:
- 输入层:接收输入信号的层,通常与输入数据的维度相同。
- 隐藏层:不直接与输出层连接的层,通常有多个。
- 输出层:产生最终输出的层,通常与输出数据的维度相同。
1.2.3 连接
连接是神经元之间的关系,它们通过权重来传递信号。连接的权重表示神经元之间的关系,通常用数字表示。在训练过程中,这些权重会根据损失函数的值进行调整,以便最小化损失并提高模型的准确性。
1.3 神经网络的学习过程
神经网络的学习过程通常被称为“训练”,它涉及到调整权重以便最小化损失函数。这个过程通常使用一种称为“梯度下降”(Gradient Descent)的优化算法。
1.3.1 损失函数
损失函数(Loss Function)是用于衡量神经网络预测与实际值之间差距的函数。损失函数的目标是最小化这个差距,以便提高模型的准确性。常见的损失函数包括均方误差(Mean Squared Error, MSE)、交叉熵损失(Cross-Entropy Loss)等。
1.3.2 梯度下降
梯度下降(Gradient Descent)是一种优化算法,用于最小化损失函数。它通过计算损失函数的梯度(Gradient),并根据这些梯度调整权重来逼近损失函数的最小值。梯度下降算法的一种变种是随机梯度下降(Stochastic Gradient Descent, SGD),它在每一次迭代中使用单个样本来计算梯度,这可以加速训练过程。
1.3.3 反向传播
反向传播(Backpropagation)是一种计算神经网络梯度的方法,它通过从输出层向输入层传播错误信息来计算每个权重的梯度。反向传播算法的核心是Chain Rule,它允许计算每个神经元的梯度,并通过链式法则将这些梯度传播回前面的层。
1.4 神经网络的应用
神经网络已经应用于许多领域,包括计算机视觉、自然语言处理、语音识别、医疗诊断、金融风险评估等。以下是一些具体的应用例子:
- 图像识别:神经网络可以用于识别图像中的物体、人脸、车辆等。例如,Google的DeepMind团队使用了深度学习技术来识别医学图像,以帮助诊断癌症。
- 语音识别:神经网络可以用于将语音转换为文本,例如Apple的Siri和Google的Google Assistant。
- 自然语言处理:神经网络可以用于机器翻译、情感分析、问答系统等。例如,Google的Neural Machine Translation(NMT)系统使用了深度学习技术来实现多语言翻译。
- 医疗诊断:神经网络可以用于诊断疾病、预测病人的生存率等。例如,Zebra Medical Vision使用深度学习技术来诊断癌症和其他疾病。
- 金融风险评估:神经网络可以用于预测股票价格、评估信用风险等。例如,Kensho使用深度学习技术来预测股票市场的波动。
1.5 神经网络的挑战
尽管神经网络在许多任务中表现出色,但它们仍然面临一些挑战:
- 解释性:神经网络的决策过程通常是不可解释的,这使得它们在某些场景下难以被接受。例如,在医疗诊断和金融风险评估等关键领域,解释性是至关重要的。
- 数据需求:神经网络需要大量的数据来进行训练,这可能限制了它们在某些领域的应用。例如,在医疗领域,数据收集和标注的过程可能非常昂贵。
- 计算资源:训练大型神经网络需要大量的计算资源,这可能限制了它们在某些场景下的应用。例如,在边缘计算环境中,计算资源可能有限。
- 鲁棒性:神经网络在面对未知或异常的输入时,可能会产生错误的预测。例如,在自动驾驶领域,神经网络需要具有高度的鲁棒性。
1.6 未来的前沿
尽管神经网络面临一些挑战,但它们在未来仍然具有巨大的潜力。以下是一些未来的前沿:
- 解释性:研究者正在努力开发一种名为“可解释性神经网络”(Explainable AI)的技术,这种技术旨在提高神经网络的解释性,使得人们可以更好地理解它们的决策过程。
- 数据不足:研究者正在开发一种名为“有限数据学习”(Few-Shot Learning)的技术,这种技术旨在使神经网络能够在数据不足的情况下进行有效的学习。
- 边缘计算:研究者正在开发一种名为“边缘神经网络”(Edge Neural Networks)的技术,这种技术旨在在边缘计算环境中进行有效的神经网络训练和推理。
- 强化学习:强化学习是一种学习通过与环境的互动来获取反馈的方法,它已经应用于游戏、机器人控制等领域。未来,强化学习可能会成为神经网络的一个重要组成部分,使其能够更好地适应不同的环境和任务。
2.核心概念与联系
在本节中,我们将讨论神经网络的核心概念,包括:
- 人工神经元与生物神经元的区别
- 神经网络与传统机器学习的区别
- 神经网络与深度学习的区别
2.1 人工神经元与生物神经元的区别
人工神经元和生物神经元都是信息处理单元,但它们之间存在一些关键的区别:
- 结构:生物神经元是细胞的扩展,它们具有输入端和输出端,通过细胞体内的复杂过程传递信号。人工神经元则是简化的模型,它们通过连接和激活函数处理信号。
- 计算能力:生物神经元具有复杂的计算能力,可以执行非线性运算。人工神经元通常使用简单的激活函数,如sigmoid、tanh等,来实现非线性。
- 学习能力:生物神经元通过修改连接强度来学习。人工神经元通过梯度下降等优化算法调整权重来学习。
2.2 神经网络与传统机器学习的区别
传统机器学习和神经网络都是用于解决机器学习问题的方法,但它们之间存在一些关键的区别:
- 模型复杂性:传统机器学习算法通常使用简单的模型,如线性回归、支持向量机等。神经网络则使用多层感知器(Multilayer Perceptrons, MLP)或卷积神经网络(Convolutional Neural Networks, CNN)等复杂的模型。
- 非线性处理:传统机器学习算法通常处理线性问题,而神经网络可以处理非线性问题,因为它们使用激活函数来实现非线性运算。
- 训练方法:传统机器学习算法通常使用最小化损失函数的方法进行训练,如梯度下降。神经网络使用梯度下降等优化算法进行训练,但训练过程通常更复杂和耗时。
2.3 神经网络与深度学习的区别
深度学习是一种使用多层神经网络进行自动特征学习的方法,它是神经网络的一种。深度学习与神经网络之间的区别如下:
- 模型层次:神经网络可以是多层的,但它们不一定具有深度。深度学习则使用多层感知器(MLP)或卷积神经网络(CNN)等深度模型。
- 自动特征学习:深度学习算法可以自动学习特征,而传统的神经网络需要手动提供特征。
- 应用范围:神经网络可以应用于各种机器学习任务,而深度学习则更适用于处理大规模、高维度数据的任务,如图像识别、自然语言处理等。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
在本节中,我们将详细讲解神经网络的核心算法原理、具体操作步骤以及数学模型公式。我们将讨论以下主题:
- 前向传播
- 损失函数
- 反向传播
- 梯度下降
3.1 前向传播
前向传播(Forward Propagation)是神经网络中的一种计算方法,它用于计算输入数据通过神经网络的输出。前向传播的过程如下:
- 对输入数据进行初始化,得到输入向量。
- 对输入向量进行通过神经网络的每个层的计算,直到得到输出向量。
在前向传播过程中,每个神经元的输出通过连接和激活函数得到计算。连接权重和偏置参数在训练过程中会被调整,以便最小化损失函数。
3.2 损失函数
损失函数(Loss Function)是用于衡量神经网络预测与实际值之间差距的函数。损失函数的目标是最小化这个差距,以便提高模型的准确性。常见的损失函数包括均方误差(Mean Squared Error, MSE)、交叉熵损失(Cross-Entropy Loss)等。
3.2.1 均方误差(Mean Squared Error, MSE)
均方误差是一种常用的损失函数,它用于回归任务。给定预测值$\hat{y}$和真实值$y$,均方误差可以表示为:
$$ MSE = \frac{1}{n} \sum{i=1}^{n} (\hat{y}i - y_i)^2 $$
3.2.2 交叉熵损失(Cross-Entropy Loss)
交叉熵损失是一种常用的损失函数,它用于分类任务。给定预测概率$\hat{y}$和真实概率$y$,交叉熵损失可以表示为:
$$ H(y, \hat{y}) = - \sum{c=1}^{C} yc \log(\hat{y}_c) $$
其中$C$是类别数量。
3.3 反向传播
反向传播(Backpropagation)是一种计算神经网络梯度的方法,它通过从输出层向输入层传播错误信息来计算每个权重的梯度。反向传播算法的核心是链式法则,它允许计算每个神经元的梯度,并通过链式法则将这些梯度传播回前面的层。
反向传播的过程如下:
- 对输入数据进行前向传播,得到输出向量。
- 对输出层的神经元计算梯度。
- 对隐藏层的神经元计算梯度。
- 反复应用链式法则,将梯度传播回前面的层。
3.4 梯度下降
梯度下降(Gradient Descent)是一种优化算法,用于最小化损失函数。在神经网络中,梯度下降算法用于调整权重,以便最小化损失函数。梯度下降算法的过程如下:
- 初始化权重。
- 计算损失函数的梯度。
- 根据梯度更新权重。
- 重复步骤2和步骤3,直到收敛。
3.4.1 学习率
学习率(Learning Rate)是梯度下降算法中的一个重要参数,它控制了权重更新的大小。学习率通常使用以下公式:
$$ w{t+1} = wt - \eta \nabla L(w_t) $$
其中$wt$是当前权重,$\eta$是学习率,$\nabla L(wt)$是损失函数的梯度。
3.4.2 随机梯度下降(Stochastic Gradient Descent, SGD)
随机梯度下降是一种变种梯度下降算法,它在每一次迭代中使用单个样本来计算梯度,这可以加速训练过程。随机梯度下降的过程如下:
- 随机选择一个样本。
- 使用该样本计算梯度。
- 根据梯度更新权重。
- 重复步骤1到步骤3,直到收敛。
4.核心代码实例
在本节中,我们将通过一个简单的例子来展示神经网络的核心代码实例。我们将使用Python的Keras库来构建一个简单的多层感知器(Multilayer Perceptron, MLP)来进行手写数字识别任务。
4.1 导入库
首先,我们需要导入所需的库:
python import numpy as np from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense from keras.utils import to_categorical
4.2 数据加载和预处理
接下来,我们需要加载和预处理数据:
```python
加载数据
(xtrain, ytrain), (xtest, ytest) = mnist.load_data()
数据预处理
xtrain = xtrain.reshape(-1, 28 * 28).astype('float32') / 255 xtest = xtest.reshape(-1, 28 * 28).astype('float32') / 255 xtrain = tocategorical(xtrain, numclasses=10) xtest = tocategorical(xtest, numclasses=10) ```
4.3 构建神经网络模型
然后,我们需要构建一个简单的多层感知器(MLP)模型:
```python
构建模型
model = Sequential() model.add(Dense(512, activation='relu', input_shape=(784,))) model.add(Dense(512, activation='relu')) model.add(Dense(10, activation='softmax'))
编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) ```
4.4 训练模型
接下来,我们需要训练模型:
```python
训练模型
model.fit(xtrain, ytrain, epochs=10, batch_size=128) ```
4.5 评估模型
最后,我们需要评估模型的性能:
```python
评估模型
score = model.evaluate(xtest, ytest, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) ```
5.未来前沿
在本节中,我们将讨论神经网络未来的前沿,包括:
- 硬件支持
- 算法创新
- 应用领域
5.1 硬件支持
硬件支持是神经网络未来发展的关键因素。随着人工智能技术的不断发展,硬件制造商正在投入大量资源来开发专门用于神经网络训练和推理的硬件。这些硬件包括:
- 图形处理单元(GPU):GPU已经成为神经网络训练的标配,由于其高性能和低成本,它已经广泛应用于各种机器学习任务。
- 特定于应用的积木(ASIC):这些硬件专门用于神经网络训练和推理,它们具有更高的性能和更低的能耗。例如,Google的Tensor Processing Unit(TPU)和NVIDIA的Volta架构。
- 边缘计算:随着互联网的普及,边缘计算已经成为神经网络的一个前沿,它将智能功能推向边缘设备,以实现低延迟和高效的计算。
5.2 算法创新
算法创新是神经网络未来发展的另一个关键因素。研究者正在开发各种新的神经网络算法,以解决现有算法的局限性。这些算法包括:
- 解释性AI:解释性AI旨在提供模型的解释性,以便人们能够更好地理解模型的决策过程。例如,LIME和SHAP等方法。
- 有限数据学习:有限数据学习旨在使神经网络在数据不足的情况下进行有效的学习。例如,一些生成对抗网络(GAN)和自监督学习方法。
- 强化学习:强化学习是一种学习通过与环境的互动来获取反馈的方法,它已经应用于游戏、机器人控制等领域。未来,强化学习可能会成为神经网络的一个重要组成部分,使其能够更好地适应不同的环境和任务。
5.3 应用领域
神经网络的应用领域将不断拓展,随着算法和硬件的不断发展。以下是一些未来的应用领域:
- 自动驾驶:自动驾驶需要高度的感知和决策能力,神经网络可以用于处理复杂的感知任务,如图像识别、目标跟踪等。
- 医疗:神经网络可以用于诊断疾病、预测病理结果、优化治疗方案等。例如,深度学习已经应用于肿瘤分类、心脏病预测等领域。
- 金融:神经网络可以用于风险评估、投资策略优化、信用评估等。例如,深度学习已经应用于股票价格预测、信用卡欺诈检测等领域。
- 能源:神经网络可以用于智能能源管理、预测能源需求、优化能源分配等。例如,深度学习已经应用于太阳能生成预测、能源消耗优化等领域。
6.附加问题
在本节中,我们将回答一些常见的问题,以帮助读者更好地理解神经网络。
6.1 神经网络的优缺点是什么?
优点:
- 能够处理非线性问题。
- 能够自动学习特征。
- 能够在大规模数据集上达到高性能。
缺点:
- 需要大量的计算资源。
- 难以解释模型决策过程。
- 需要大量的标签数据。
6.2 神经网络与传统机器学习的主要区别是什么?
主要区别在于:
- 模型复杂性:神经网络具有更高的模型复杂性,可以处理更复杂的问题。
- 特征学习:神经网络可以自动学习特征,而传统机器学习需要手动提供特征。
- 算法创新:神经网络已经取代了传统机器学习算法在许多任务上的领先地位。
6.3 神经网络与深度学习的主要区别是什么?
主要区别在于:
- 深度学习是一种使用多层神经网络的学习方法,它涉及到神经网络的层次结构。
- 神经网络是一种通用的计算模型,它可以用于实现各种机器学习任务。
6.4 神经网络的训练过程是什么?
神经网络的训练过程包括以下步骤:
- 初始化权重。
- 前向传播。
- 计算损失。
- 反向传播。
- 更新权重。
- 重复步骤2到步骤5,直到收敛。
6.5 神经网络的梯度下降是什么?
梯度下降是一种优化算法,用于最小化损失函数。在神经网络中,梯度下降算法用于调整权重,以便最小化损失函数。梯度下降算法的过程如下:
- 初始化权重。
- 计算损失函数的梯度。
- 根据梯度更新权重。
- 重复步骤2和步骤3,直到收敛。
6.6 神经网络的激活函数是什么?
激活函数是神经网络中的一个关键组件,它用于在神经元之间传递信息。激活函数的主要作用是将输入映射到输出,以实现非线性转换。常见的激活函数包括:
- sigmoid
- tanh
- ReLU
- Leaky ReLU
- ELU
6.7 神经网络的损失函数是什么?
损失函数是一个用于衡量神经网络预测与实际值之间差距的函数。损失函数的目标是最小化这个差距,以便提高模型的准确性。常见的损失函数包括:文章来源:https://www.toymoban.com/news/detail-833658.html
- 均方误差(Mean Squared Error, MSE)
- 交叉熵损失(Cross-Entropy Loss)
6.8 神经网络的梯度下降优化器是什么?
梯度下降优化器是一种用于优化神经网络训练过程的算法。优化器通过调整学习率来更新权重,以便最小化损文章来源地址https://www.toymoban.com/news/detail-833658.html
到了这里,关于神经网络与人工智能:未来的前沿的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!