一、前言
【中国乒乓和中国男足】
网上呢一直流传着这么两个说法,我国有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是男足。前者是“谁也赢不了!”,后者是“谁也赢不了!
- 相信了解的读者就可以看出来这两句话的不同含义了,虽然都叫做【谁也赢不了】,但是呢因为这个谁所指代的对象不一样也就造成了这两句话的意思不同
- 其实对于函数重载来说也具有相同的意味,虽然看上去一样,但因为某些内容不一样便造成了函数重载

【文言文一词多义】
自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了
- 相信你在上初高中的时候一定学习过文言文,里面有一种东西叫做 —— 一词多义,也就是对于一个词来说可以存在不同的含义,它所存在的语境不同就会导致它的意思有所不同
- 从编程语言的角度来说就可以说这个词被重载了,虽然都是一个词,但却具有不同的含义

通过上述两个生活小案例,相信你对函数重载一定有了一个基本的概念,接下去让我们正式来学习一下函数重载💻
二、函数重载概念引入
【函数重载】:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题
- 对于函数重载这个概念,我们在学习C语言的时候是没有听过的,因为在C语言中是不存在函数重载概念的。只有在
.cpp的文件中,我们才可以进行函数重载


对于C++中的函数重载来说,随着不同类型或者个数的实参传入,编译器会自动识别向对应的函数去进行一个调用
1、参数【类型】不同构成重载
- 首先第一种就是【类型】不同可以构成函数重载,这个类型值得不仅仅是返回值类型,更重要的是对于形参的类型
- 可以看到,下面的两个函数虽然函数名相同,但是因为形参的类型不同,所以可以处理的数据种类就不一样
int Add(int x, int y)
{
return x + y;
}
double Add(double x, double y)
{
return x + y;
}
int ret1 = Add(1, 2);
double ret2 = Add(1.1, 2.2);
- 运行结果就不展示了,我们可以通过调试去观察一下编译器是对于重载的函数是否真的可以做到一个自动识别

2、参数【个数】不同构成重载
- 第二种的话就是传入实参的个数不同也会可以构成重载。可以看到我写了一个三参的Add函数
int Add(int x, int y)
{
return x + y;
}
int Add(int x, int y, int z)
{
return x + y + z;
}
int ret1 = Add(1, 2);
int ret2 = Add(1, 2, 3);
- 同样,我们通过调试来观察程序的思维

3、参数【类型顺序】不同构成重载
- 最后一种的话可能你没有听说过,若是形参的两个类型顺序发生了改变,那也可以算是函数重载
void Print(int x, char c)
{
cout << x << " ";
cout << c << " ";
cout << endl;
}
void Print(char c, int x)
{
cout << c << " ";
cout << x << " ";
cout << endl;
}
Print(1, 'x');
Print('y', 2);
- 可以看出,编译器依旧会进行一个自动识别

三、函数重载的原理
1、前言
- 对于函数重载的原理就是 —— 采用了函数名修饰,所以编译器可以通过修饰后的不同的函数去找到对应的函数
可是呢我们知道在C语言中是不存在【函数重载】概念的,因此出现相同函数名的话就会直接
- 可以看到这里定义了两个
StackPush的函数体,放在一个.c的文件中出现了问题

- 若是将文件改成
.cpp为后缀的,去编译的时候就不会有问题了

Stack.h
#include <stdio.h>
#include <stdlib.h>
struct Stack {
int* a;
int top;
int capacity;
};
void StackInit(struct Stack* pst, int defaultCapccity);
void StackPush(struct Stack* pst, int x);
void StackPush(struct Stack* pst, double x);
Stack.cpp
#include "Stack.h"
void StackInit(struct Stack* pst, int defaultCapccity)
{
int* tmp = (int*)malloc(sizeof(int) * defaultCapccity);
if (NULL == tmp)
{
perror("fail malloc");
exit(-1);
}
pst->a = tmp;
pst->capacity = defaultCapccity;
}
void StackPush(struct Stack* pst, int x)
{
printf("StackPush(struct Stack* pst, int x)\n");
}
void StackPush(struct Stack* pst, double x)
{
printf("StackPush(struct Stack* pst, double x)\n");
}
test5.cpp
#include "Stack.h"
int main()
{
struct Stack st;
StackInit(&st, 4);
StackPush(&st, 1);
StackPush(&st, 1.1);
return 0;
}
2、回顾程序编译 + 链接的过程
在观察函数重载的原理之前,我们来浅浅回顾一下C语言中所介绍的程序编译+链接全过程
- 我们知道,要诞生一个可执行程序,就需要经过【翻译环境】和【运行环境】,我们主要讨论的是前者。而对于前者,又可以细分为【编译】+ 【链接】这两个过程,在经过编译器进行预编译、编译、汇编之后,之前的源文件
test.c就会形成一个目标文件test.o - 但是在一个目录下,可能存在多个源文件,一个文件又可能调用了另一个文件,那此时它们就都需要进行编译产生
.o的目标文件

- 但是对于目标文件来说是不可以直接被执行的,因此需要将当前目录下生成的多个目标文件经过链接器进行链接,若是在目标文件中还使用到了库中的函数,那么链接器就会到库中去寻找对应的库函数,一起进行链接
- 最终形成的才是一个可执行文件
.exe,在Linux下是a.out

现在我们要去思考的一个点是,假如
test.cpp中使用到了add.c中的函数Add,而且恰好这个函数还进行了函数重载,那编译器是怎么知道要去add.c中寻找这个重载函数的呢❓
首先你要清楚在编译阶段后的【链接】阶段,它的功能是什么
- 合并段表
- 符号表的合并和符号表的重定位
- 当链接器进行链接的时候,它看到
test.o中调用到了Add函数,此时它就会去其他目标文件中通过一定的方式识别找到它所匹配调用的这个重载函数,然后通过将两个目标文件的符号表进行合并也就形成了最后的可执行文件

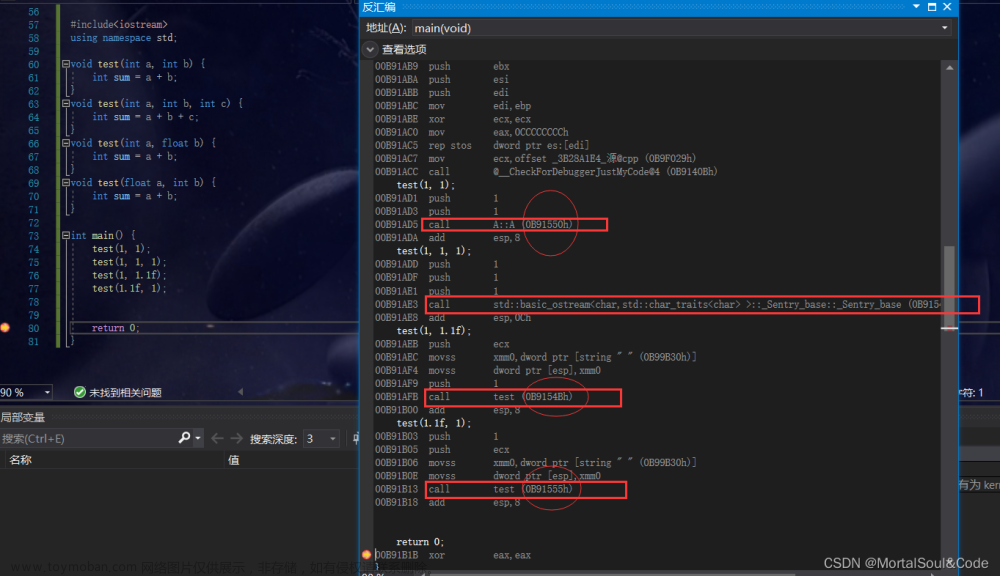
但是还有一点很困惑的是,编译器是怎样的方式去识别的呢?我们可以通过查看【反汇编】代码来观察一下
- 通过汇编代码可以看到,其实C++这里在调用函数的时候是通过不同的地址之间去进行跳转的,这个呢我们在反汇编观察函数栈帧的创建和销毁这一块有进行过细讲,首先记住当前这条
call指令的下一条指令,然后跳转到jmp指令处,jmp指令呢再通过地址跳转到对应的函数中

💬那我现在想问,这几个函数所需要跳转的地址是何时产生的?

- 这个跳转的地址应该是编译之后在生成
Stack.s这个文件后才会才会有,若是只经过了预处理后,当#include "Stack.h"这个头文件一展开,此时所包含的便是这三个函数的声明,但是没有定义,只有在编译之后生成了指令,然后构成一个【汇编文件】,此时才会在对应的call指令生成那一个需要跳转的地址,填充到括号中
但是呢即使那个时候没有地址依旧是可以编译通过的,为什么?这里我通过一个生活中的案例来形象地描述一下这个【声明】和【定义】的区别
- 你呢,背井离乡在二线城市当一个程序员💻,工作了几年也赚了不少钱,此时你就想把一直以来的出租屋换成一个崭新的房子,想要在你所处的城市买个房,虽然交不起所有的钱,但首付还是可以的,不过呢还差那么几万块钱,于是呢就想到了你大学时候的室友,也是个铁瓷很要好的朋友,想找他结点钱💴
- 于是就打电话过去说:“兄弟呀,我最近想买个房,交个首付,不过手头上还差个几万块钱,你看你有没有一些不急着用的先借我点,之后赚来了再还给你。”那听到昔日的好友这么一番话,便说:“可以可以,好兄弟开口,那必须帮忙!”于是呢他就这么答应你了,不过也只是口头答应,也就是一种承诺。这个口头答应其实指得就是【声明】,你只能知道会有这么一笔钱给到你,但是这笔钱还没真正到你的手里

- 那么慢慢下去,我们在经过预处理、编译、汇编之后就来到了链接,对于【链接】而言,其实就是去合成各种符号表,刚才我们的函数是只有声明但是没有定义,不过此刻当我们去执行链接的时候,就可以通过在【编译】期间生成的这一个地址去找到这个函数的定义,所以对于【链接】的本质而言其实就是找到定义

- 不过呢【链接】也有成功 / 失败的可能性,比方说我在
Stack.cpp中将这两个函数的实现给注释掉后,再去进行编译就会发现出现了很大的问题,此时这个问题就是在【链接】这一块出的问题,因为我们上面说过对于【链接】来说就是去找定义,但是这里却没有找到相关所需函数的定义,所以就报出了error LNK2019这样的错误,这一块便是链接出了问题

- 不过呢,在将具体的实现放出来后,就不会出现问题了,此时通过符号表中的地址去进行寻找的时候就可以发现具体的实现了

- 那么对应到我们上面所说到的这个和兄弟借钱的问题,刚才呢我们在打电话的时候兄弟很豪爽地说是可以借给我们的(声明),于是便立马付下了定金,就等着兄弟的这笔钱了(定义),那么这个时候就会出现两种情况Ⅱ
- 你的兄弟回道:“哦哦,不好意思,最后手头太忙可了,都给忘了,马上给你转过来。”此时就听到【支付宝到账5万元】的声音,那么这笔钱就真正地到你手里的,这是实实在在的,已经存在了的事,指的就是【定义】
- 你的兄弟回道:“啊呀,这个,真是不好意思啊,家里的钱都给媳妇管着呢😪,它不同意我也办法,对不住了兄弟,要不你再找找别人。”于是他便小心翼翼地挂掉了电话,你俩就没有再联系过,铁瓷也不铁了~
- 对于上面这第一种情况呢,就是《链接成功》的标志,不过对于这第二种情况呢,就是《链接失败》的标志,即只有声明没有定义的情况
- 其实还有一种特殊的情况,那就是在你打给你兄弟电话的时候,他承诺你了,并且在几分钟之后立马把钱打到了你的账户中,此时对于这种情况就是在编译的时候【声明】+【定义】直接就有了,那么我们便不需要在链接的时候去找这个函数的实现了,对于这一块而言很像我们学过的C++内联函数,一般对于内联函数而言会直接将函数的声明和定义都写在类内,这就是C++在使用内联函数的一个特点
💬上面我们主要讲述并回顾了我们在C语言中所学的编译链接,以此来对照在C++中我们在写函数重载的时候是如何去逐步实现【声明】+【定义】的,但是你是否有一个疑问,C++中到底是如何去准确地找到不同重载函数地址的呢?接下去我们就通过Linux来进行观察一下
2、Linux下【objdump】查看反汇编
首先我们来看下Linux平台下对于重载函数的反汇编指令是怎样的
- 首先生成一下这个可执行文件。然后我使用到的一个是查看目标文件或者可执行的目标文件的构成的gcc工具 ——
objdump。这个也是Linux下的一个指令,感兴趣的可以去了解一下 链接

- 此时我们就可以来看一下生成的反汇编指令是怎样的,直接拉到重载的两个Add函数这里
- 可以看到,原本的第一个函数定义变成了
<_Z3Addii>,第二个函数则变成了<_Z3Adddd>这是为什么呢?

- 为了进行对比,我也写了一份C语言的代码,并且使用gcc去进行了一个编译。同样我们也可以去查看它的反汇编指令
- 此时便观察到C语言对于函数名在编译 + 链接之后并没有做什么过多的修改,而是直接使用的原来的函数名【这里只有一个函数的原因是C不支持函数重载】

所以我们可以得出结论:对于C语言来说是不存在函数名修饰的,只有C++支持,会将函数参数类型信息添加到修改后的名字中

3、Windows下反汇编查看
Linux中查看完之后我们再来Windows中来看看,为什么要先看Linux呢?看下去你就知道了
- 在VS2019中因为屏蔽了过多细节,所以我使用VC6.0进行一个演示【此时你就就可以看出在Windows下的函数名修饰是相当得复杂】

- 一样,通过C和C++两个源程序进行运行,因为我处在VS这个集成开发环境中,所以不需要对源文件进行编译 + 链接,只需点击运行即可
- 可以看到,对于
.cpp的文件来说,函数名在修饰之后变得是异常复杂。可是对于.c的文件来说,使用的还是原先的Add函数名,没有发生变化

- 本来想观察一下Windows环境下的函数名修饰,但是如此复杂度的规则这可如何是好呢?那我们就稍微地来聊一聊有关Windows下的【函数名修饰规则】

看了上面这些我想应该也够了,如果你还想要再深度地进行了解的话可以看看这篇文章 —— 链接
4、函数名修饰规则总结
通过上面的观察我们就可以来总结一下有关函数名的修饰规则
-
在Linux环境下,C++的函数名修饰规则为
【_Z + 函数长度 + 函数名 + 类型首字母】- Linux下的编译器为gcc/g++,一个开源组织搞的项目
-
在Windows环境下,C++的函数名修饰规则为
【? + 函数名 + @@YA + 返回值 + 参数1 + 参数2 + @Z】,int类型对应的是字母H,void类型对应的是字母X,double类型对应的是字母N。扩展:float类型对应的是字母M(可以当做了解一下)- Windows下的编译器是cl.exe,集成在VS中,是由微软公司发布的
解答:为何而C语言不支持函数重载❓
在看了上面有关C++函数重载的原理之后,就可以回答为何C语言不支持函数重载
- 因为对于C语言来说,在经过编译后函数名修饰不会发生任何的改变,还是采用原先的函数名,若是想C++那样写重载函数的话就会别编译器认为是语法错误。因为编译器无法通过不同的函数名修饰去找到对应所调用的函数
- 所以就可以看出对于C++的函数重载而言是通过修饰后的函数名去进行比对的,无论是Windows还是会Linux都是一样,只是不同的平台拥有各自的编译器,每个编译器所规定的语法是不同的
错误案例分析🔍
通过研究了函数重载的原理之后,最后再来说说比较容易误解的写法,你认为下面的两个函数构成函数重载吗?
int Add(int x, int y)
{
return x + y;
}
double Add(int x, int y)
{
return x + y;
}
- 【答案揭晓】:No,这样不可以构成函数重载,仅仅是返回值的不同无法编译器认定为是函数重载,因为对于函数名和形参类型完完全全相同的两个函数在进行函数名修饰之后也是一样的


- 可以看到,无论是对于Windows还是Linux下,连编译都是通不过的,所以函数重载只有三种形式,不要搞混淆了
四、总结与提炼
最后我们来总结一下本文所学习的的内容📖
- 首先在文章的开始,我通过两个生活中的小案例先带读者了解了什么是函数重载的概念。然后讲述了有关函数重载的三种形式,分别是:【类型】不同、【个数】不同和【类型顺序】不同三种。对函数重载有了一个基本的认识
- 然后我们便通过双系统深入探究了对于C++而言对函数在编译之后会进行一个函数名修饰,Linux环境下易理解一些,Windows环境下的解析过于复杂,若是有兴趣的读者可以继续深入
以上就是本文要介绍的所有内容,感谢您的阅读🌹文章来源:https://www.toymoban.com/news/detail-834080.html
 文章来源地址https://www.toymoban.com/news/detail-834080.html
文章来源地址https://www.toymoban.com/news/detail-834080.html
到了这里,关于C++ | 探究函数重载的原理:函数名修饰【基于Windows + Linux双系统】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!