Kafka 消费者——从源码角度深入理解
![[AIGC ~ coze] Kafka 消费者——从源码角度深入理解,AI,AIGC,kafka,分布式](https://imgs.yssmx.com/Uploads/2024/02/834096-1.png)
一、引言
Kafka 是一个分布式的流处理平台,广泛应用于大规模数据处理和实时数据管道。在 Kafka 生态系统中,消费者扮演着至关重要的角色,它们从 Kafka 主题中读取数据并进行处理。本文将深入探讨 Kafka 消费者的工作原理,包括消费者的基本概念、消费者组、订阅主题、偏移量管理等。此外,我们还将对 Kafka 消费者的源代码进行简单分析,帮助读者更好地理解其内部机制。
二、Kafka 消费者的基本概念
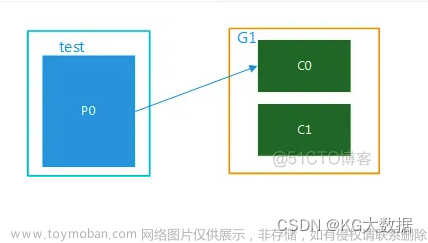
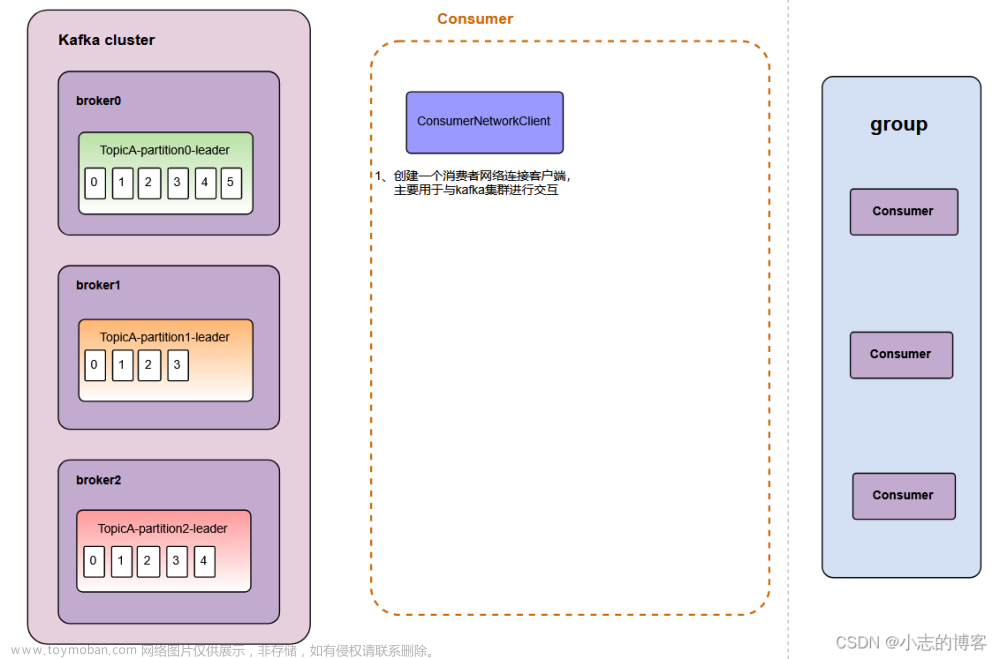
在 Kafka 中,消费者是从 Kafka 主题中读取数据并进行处理的组件。每个消费者都属于一个消费者组,消费者组中的多个消费者可以共同消费一个主题,实现分布式消费。每个消费者都会维护自己的偏移量,用于记录已经读取到的消息位置。
三、消费者组
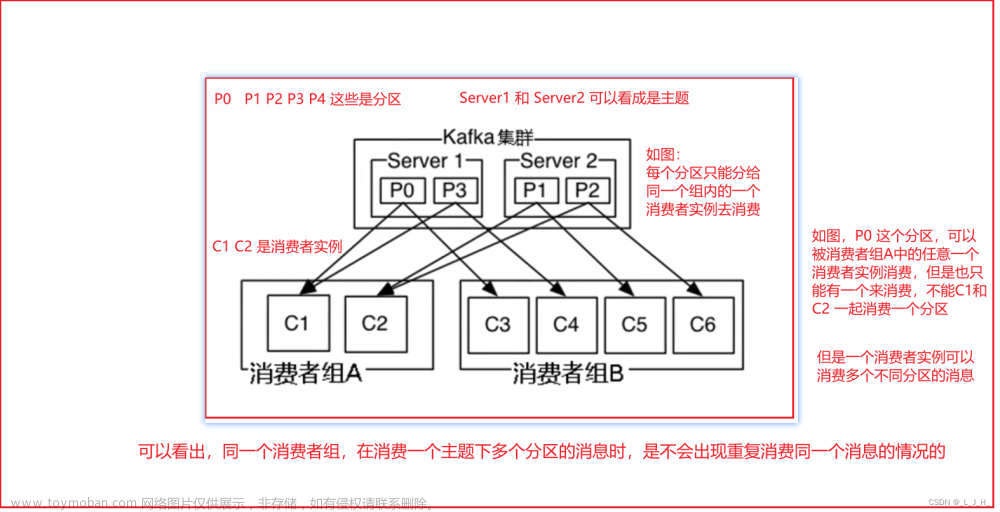
消费者组是 Kafka 中一个重要的概念,它允许多个消费者实例共同消费一个主题。每个消费者实例都属于一个消费者组,并且每个消费者组都会为其分配一个唯一的 Group ID。消费者组中的实例可以协同工作,共同消费主题中的消息,实现负载均衡和容错。
四、订阅主题
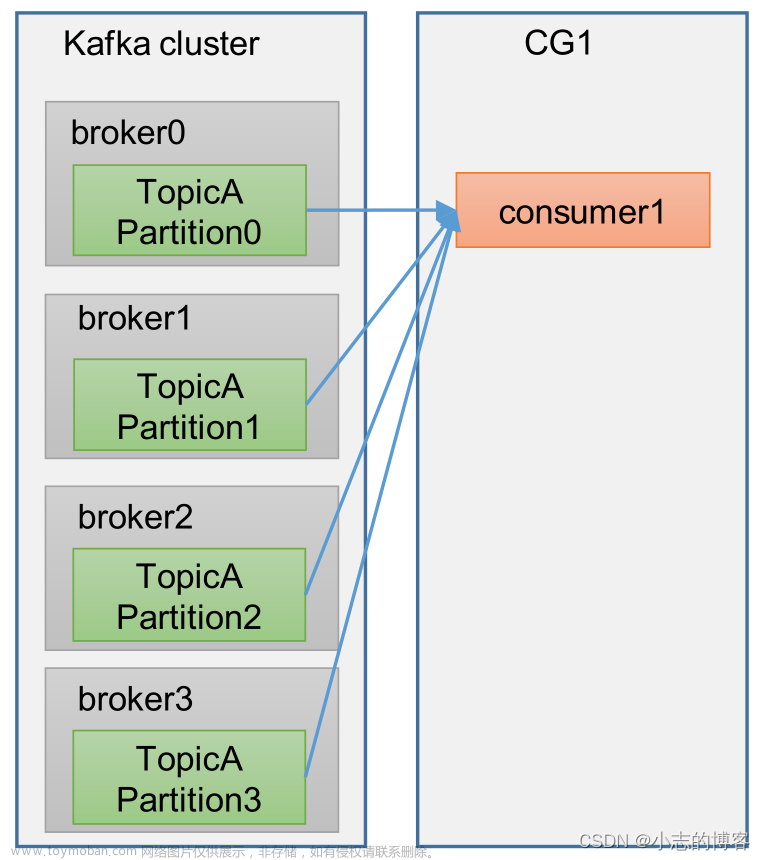
在 Kafka 中,消费者通过订阅主题来指定要消费的消息。消费者可以订阅一个或多个主题,并通过指定订阅的主题和分区来确定要消费的消息范围。每个主题都可以被多个消费者组订阅,而每个消费者组中的实例可以订阅不同的主题。
五、偏移量管理
在 Kafka 中,偏移量用于记录消费者已经读取到的消息位置。每个消费者实例都会维护自己的偏移量,用于跟踪已经读取的消息。偏移量由消费者组 ID、主题和分区号组成,每个消息在被消费者读取后,其偏移量会被更新。
六、消费者协调器
在 Kafka 中,消费者协调器负责管理消费者组的成员关系、分配分区给消费者实例、处理消费者实例的加入和退出等操作。消费者协调器是通过 Zookeeper 来实现的。每个消费者组在 Zookeeper 上维护一个协调器节点(Coordinator Node),用于存储消费者组的元数据。
七、消费者实例
在 Kafka 中,消费者实例负责从分配给它的分区中读取数据,并将数据处理后输出到应用程序。每个消费者实例都有一个消费者线程(Consumer Thread),用于执行拉取请求和处理数据。
八、拉取请求
当一个消费者实例启动时,它会向消费者协调器发送一个加入请求,并等待协调器返回分区分配信息。一旦收到分区分配信息,消费者实例会启动一个或多个消费者线程,每个线程负责从一个分区中读取数据。
九、数据处理
消费者线程会定期向 Kafka 服务器发送拉取请求,以获取分区的数据。拉取请求中包含一个偏移量,表示消费者希望从哪个位置开始读取数据。Kafka 服务器会根据拉取请求返回对应偏移量的数据,并将偏移量更新为已读取的最新位置。
十、偏移量提交
当消费者处理完一个分区中的消息后,它需要将自己的偏移量提交给消费者协调器。偏移量提交分为手动提交和自动提交两种方式。手动提交是指消费者在处理完消息后显式地调用 commit() 方法提交偏移量。自动提交是指消费者在处理完消息后自动提交偏移量,具体的提交间隔可以通过配置参数来指定。
十一、心跳请求
为了保持与消费者协调器的连接,消费者实例会定期向协调器发送心跳请求。心跳请求用于告诉协调器自己仍然存活,并更新消费者组的元数据。如果协调器在一定时间内没有收到某个实例的心跳请求,它会认为该实例已经死亡,并将其负责的分区重新分配给其他存活的实例。
十二、源码解析
在深入理解了 Kafka 消费者的工作原理之后,我们将通过分析 Kafka 消费者的源代码来进一步理解其内部机制。以下是对 Kafka 消费者源代码的简单分析:
-
ConsumerConfig:消费者配置类,包含了消费者的各种配置参数。 -
KafkaConsumer:消费者抽象类,定义了消费者的基本接口和方法。 -
SimpleConsumer:简单消费者实现类,用于从 Kafka 服务器中读取数据。 -
ConsumerCoordinator:消费者协调器实现类,负责管理消费者组的成员关系和分配分区。 -
PartitionAssignor:分区分配器接口,定义了分配分区的方法。 -
RangeAssignor:范围分区分配器实现类,用于按照一定的规则将分区分配给消费者实例。 -
OffsetCommitter:偏移量提交器接口,定义了提交偏移量的方法。
以上是对 Kafka 消费者源代码的简单分析,我们可以看到 Kafka 消费者的实现非常复杂,涉及到了网络通信、线程管理、数据处理等多个方面。通过深入理解其源代码,我们可以更好地掌握 Kafka 消费者的内部机制,从而更好地使用和优化它。
十三、总结
本文深入探讨了 Kafka 消费者的工作原理,包括消费者的基本概念、消费者组、订阅主题、偏移量管理等。此外,我们还对 Kafka 消费者的源代码进行了简单分析,帮助读者更好地理解其内部机制。通过本文的介绍,读者可以更好地理解和使用 Kafka 消费者,从而构建高效可靠的分布式数据处理系统。文章来源:https://www.toymoban.com/news/detail-834096.html
请注意,以上内容仅为一个简要的概述,具体的实现细节和其他高级主题可能需要进一步的研究和阅读 Kafka 的官方文档。希望这篇文章对你有所帮助!文章来源地址https://www.toymoban.com/news/detail-834096.html
到了这里,关于[AIGC ~ coze] Kafka 消费者——从源码角度深入理解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!