Windows下使用hadoop+hive+sparkSQL
一、Java安装
1.1 下载
在官网下载java8(Java Downloads | Oracle)
1.2 配置java环境
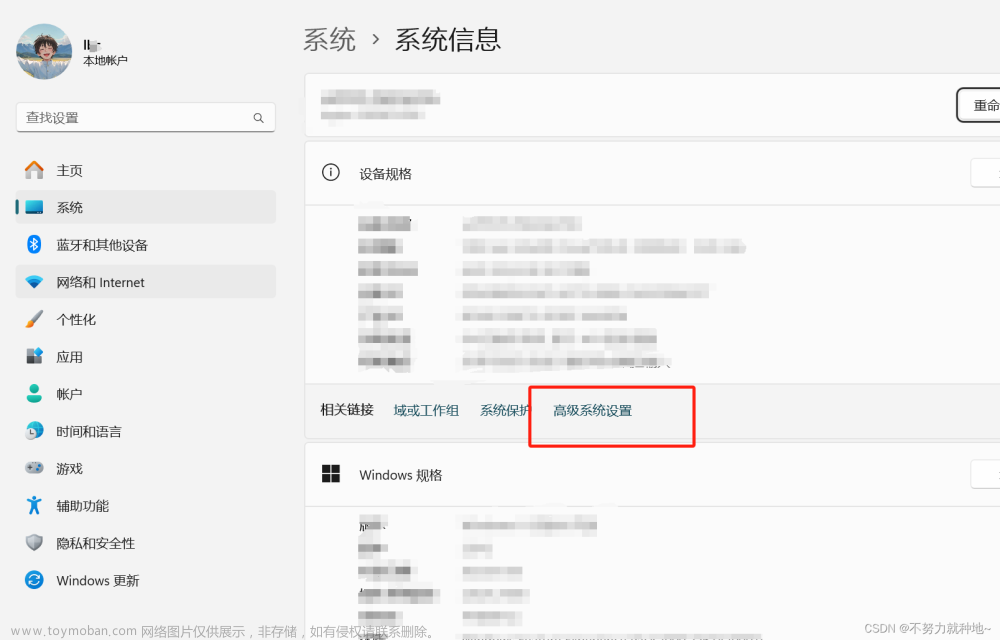
1.右击此电脑-属性
2.点击左侧高级系统设置,在出现的窗口点击环境变量接下来的窗口会出现两个框,一个是用户变量,一个系统变量,我们直接在系统变量修改。
JAVA_HOME,变量名:JAVA_HOME 值:安装路径

在变量中找到Path,点击编辑,添加以下两行
%JAVA_HOME%\bin
%JAVA_HOME%\jre\bin


二、Hadoop安装
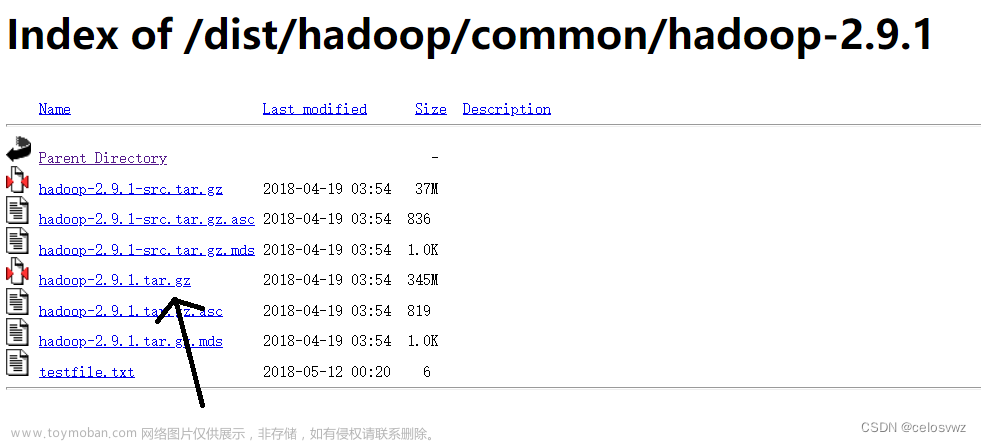
2.1 下载Hadoop安装包
下载后解压到自己喜欢的位置
本文下载的hadoop-3.3.3,其他版本请到官网下载
Apache Hadoop
hadoop-3.3.3
下载已经编译好的window平台的hadoop,版本为3.3.3,下载其他版本hadoop可能不能使用
链接:编译好的window平台的hadoop
提取码:0wza
下载微软驱动
链接:微软驱动
提取码:8dvm
2.2 配置环境变量
同上文安装Java配置环境变量
1.配置系统环境变量
HADOOP_HOME=hadoop解压路径
2.配置Path环境变量
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
2.3 安装微软驱动
下载等待安装完成即可
2.4 配置已经编译好的window平台的hadoop
将其解压到
%HADOOP_HOME%目录里面,覆盖原bin目录中的文件然后将
%HADOOP_HOME%\bin\hadoop.dll复制到C:\Windows\System32
2.5 修改hadoop配置
1.%HADOOP_HOME%\etc\hadoop\core-site.xml配置:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--设置hdfs可以被访问的ip,以及访问端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--hdfs数据文件的存放位置-->
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop/data</value>
</property>
<!--被删除的文件在垃圾箱的保留分钟数,为0表示禁用垃圾桶,被删除的文件会直接被删除-->
<!--
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
-->
<!--
hadoop.proxyuser.$superuser.hosts 配置该superUser允许通过代理访问的主机节点
hadoop.proxyuser.$superuser.groups 配置该superUser允许代理的用户所属组
hadoop.proxyuser.$superuser.users 配置该superUser允许代理的用户
下面配置了Administrator可以代理访问的主机节点和用户所属组为全部
-->
<property>
<name>hadoop.proxyuser.Administrator.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.Administrator.groups</name>
<value>*</value>
</property>
</configuration>
2.%HADOOP_HOME%\etc\hadoop\hdfs-site.xml配置:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--副本数量,只用于做本地测试,所以只用1个副本节省空间-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!---不进行权限检查-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
2.6 格式化NameNode
cmd中输入,出现
has been successfully formatted.表示格式化成功。
hdfs namenode -format
2.7 启动hadoop
cmd中输入,启动成功会弹出
namenode和datanode两个进程
start-dfs.cmd

2.8 进入UI界面
http://127.0.0.1:9870/

三、安装Scala
3.1 下载Scala安装包
下载并解压到自己喜欢的目录
本文安装的scala-2.12.11,其他版本自行在官网查找
All Available Versions | The Scala Programming Language (scala-lang.org)
https://downloads.lightbend.com/scala/2.12.11/scala-2.12.11.zip
3.2 配置环境变量
1.配置系统环境变量
SCALA_HOME=scala解压路径
2.配置Path环境变量
%SCALA_HOME%\bin
3.3 测试
cmd 输入scala,如下图则安装成功

四、Spark安装
4.1 下载Spark安装包
下载并解压到自己喜欢的目录
本文安装的Spark-3.5,其他版本自行在官网查找
Index of /spark (apache.org)
https://dlcdn.apache.org/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3.tgz
4.2 配置环境变量
1.配置系统环境变量
SPARK_HOME=spark解压路径
2.配置Path环境变量
%SPARK_HOME%\bin
4.3 测试
cmd输入spark-shell,如下图则安装成功

4.4 添加MySQL驱动
在%SPARK_HOME%\jars中放入mysql的驱动jar包,例如mysql-connector-java-5.1.34-bin.jar
链接:https://pan.baidu.com/s/1LqpBM5LV0Y46O8NXTibFTQ?pwd=79yy
提取码:79yy
五、MySQL安装
5.1 下载MySQL安装包
下载并解压到自己喜欢的目录
本文安装的MySQL-8.2.0,其他版本自行在官网查找
MySQL :: Download MySQL Community Server
https://cdn.mysql.com//Downloads/MySQL-8.2/mysql-8.2.0-winx64.zip
5.2 配置MySQL
进入解压后的目录,在bin同等级目录下新建my.ini,添加如下配置
需要注意的是basedir mysql的安装路径,要选择你自己mysql 的安装路径,datadir 选择数据存放的路径,basedir , datadir路径使用正斜杠/ 或双斜杠\ 否则起不来服务
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.6/en/server-configuration-defaults.html
# *** DO NOT EDIT THIS FILE. It's a template which will be copied to the
# *** default location during install, and will be replaced if you
# *** upgrade to a newer version of MySQL.
[mysqld]
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
# These are commonly set, remove the # and set as required.
# 设置mysql的安装目录
basedir = D:/mysql-8.0.33-winx64/mysql-8.0.33-winx64
# 设置mysql数据库的数据的存放目录
datadir = D:/mysql-8.0.33-winx64/mysql-8.0.33-winx64/data
# 设置3306端口
port = 3306
# server_id = .....
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
sql_mode = NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
# 允许最大连接数
max_connections = 200
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors = 10
# 服务端使用的字符集默认为UTF8
character-set-server = utf8mb4
# 创建新表时将使用的默认存储引擎
default-storage-engine = INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin = mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set = utf8mb4
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set = utf8mb4
5.3 配置环境变量
1.配置系统环境变量
MYSQL_HOME=mysql解压路径
2.配置Path环境变量
%MYSQL_HOME%\bin
5.4 获取初始密码
cmd输入如下命令,获取生成的初始密码,最好保存下,后期可能会用
mysqld --initialize --console
5.5 安装并启动MySQL服务
cmd输入如下命令,安装并启动MySQL服务
mysqld --install mysql
六、Hive安装
6.1 下载Hive安装包
下载并解压到自己喜欢的目录
本文安装的Hive-3.1.3,其他版本自行在官网查找
Index of /dist/hive (apache.org)
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
6.2 配置环境变量
1.配置系统环境变量
HIVE_HOME=hive解压路径
2.配置Path环境变量
%HIVE_HOME%\bin
6.3 配置Hive元数据库(以MySQL为例)
在
%HIVE_HOME%\bin\conf新建hive-site.xml如下前三项分别是你的mysql连接url,用户名和密码,按照实际情况修改即可。连接url中hive也可以修改为其他名字,表示hive存储元数据的数据库的名称
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<!--hive的数据存储目录,指定的位置在hdfs上的目录-->
<value>/tmp/hive/warehouse</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
6.4 初始化元数据库
1.使用Navicat连接元数据库的MySQL
2.创建hive数据库(指定字符集latin1和排序规则latin1_general_ci,SQL如下)文章来源:https://www.toymoban.com/news/detail-834229.html
CREATE DATABASE `hive` /*!40100 DEFAULT CHARACTER SET latin1 COLLATE latin1_general_ci */
3.执行%HIVE_HOME%\scripts\metastore\upgrade\mysql\hive-schema-3.1.0.mysql.sql(选择版本最新的一个脚本)的SQL脚本完成元数据库的初始化文章来源地址https://www.toymoban.com/news/detail-834229.html
七、Spark SQL测试
7.1 创建连接
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import *
spark = SparkSession.builder \
.appName("Remote Spark Connection") \
.master("local") \
.config("spark.sql.catalogImplementation","hive") \
.getOrCreate()
7.2 测试
spark.sql('show databases').show()
+---------+
|namespace|
+---------+
| default|
+---------+
spark.sql("CREATE database test")
spark.sql("show databases").show()
+---------+
|namespace|
+---------+
| default|
| test|
+---------+
spark.sql("CREATE table test.test(id int)")
spark.sql("show tables").show()
+---------+---------+-----------+
|namespace|tableName|isTemporary|
+---------+---------+-----------+
| test| test| false|
+---------+---------+-----------+
到了这里,关于Windows下使用hadoop+hive+sparkSQL的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!