记一次 Flink 作业启动缓慢
背景
应用发现,Hadoop集群的hdfs较之前更加缓慢,且离线ELT任务也以前晚半个多小时才能跑完。此前一直没有找到突破口所以没有管他,推测应该重启一下Hadoop集群就可以了。今天突然要重启一个Flink作业,发现有一个过程卡了五分钟。
现象
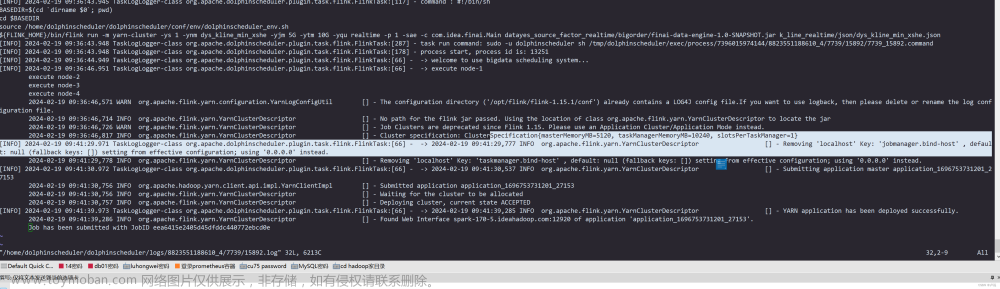
由上图可知09:36到09:41这两个过程中间花了五分钟,这两条都是Flink的日志,所以推测中间是Flink的某些过程卡住了。那Flink中间做了什么呢?
原因分析
可以看到这两条日志都是由flink同一个类所打印的:org.apache.flink.yarn.YarnClusterDescriptor ,所以去看下这个类的源码就知道了。
我们找到Flink源码的这个类org.apache.flink.yarn.YarnClusterDescriptor ,发现卡住之前的那条日志,也就是09:36那条日志,是由下面这条代码打印。

我们在看下 09:41 的那条日志是怎么打印的,我们找到了下面这个方法

看下在哪里调用了这个方法:
而正是startAppMaster这个方法调用了removeLocalhostBindHostSetting

现在我们再看下第一条日志代码位置

可以得出一个结论,卡住的代码是startAppMaster 方法从开始执行到调用 startAppMasterremoveLocalhostBindHostSetting 这个方法中间的那些代码,那我们可以看下这中间代码在做什么操作。
发现基本都是在调用YarnApplicationFileUploader 这个用于上传文件到YARN应用程序staging目录的工具类在往HDFS上传Flink作业所需的jar包或者配置文件。
final YarnApplicationFileUploader fileUploader =
YarnApplicationFileUploader.from(
stagingDirFs,
stagingDirPath,
providedLibDirs,
appContext.getApplicationId(),
getFileReplication());
// The files need to be shipped and added to classpath.
Set<Path> systemShipFiles = new HashSet<>(shipFiles)
所以基本可以断定,这个Flink作业在向HDFS写文件花了太多时间(5分钟)。那这个时间是正常的吗?我们找了一下此前启动这个任务的日志,发现当时这一步就快很多,一分多钟就完事了。

所以应该是HDFS变慢了,测试一下上传个文件看看:

发现传输一个23GB的文件需要10分钟左右。
再看下集群负载,都是正常范围以内,与此前持平,其他作业也无异常。
HDFS慢的原因可能和集群负载、集群小文件过多、网络、磁盘故障、namenode请求负载等等有关系。根据之前经验,太久没有重启集群HDFS也会变慢。因为排查集群各个方面都正常,所以计划使用重启大法 :)
再重启之后再尝试HDFS上传文件测试,发现明显快了很多了,同样一个23GB的文件现在只需要1分多钟。
 文章来源:https://www.toymoban.com/news/detail-834308.html
文章来源:https://www.toymoban.com/news/detail-834308.html
本文的重点主要在于如何判断Flink作业卡住原因,如有错误,欢迎指正。文章来源地址https://www.toymoban.com/news/detail-834308.html
到了这里,关于记一次 Flink 作业启动缓慢的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!