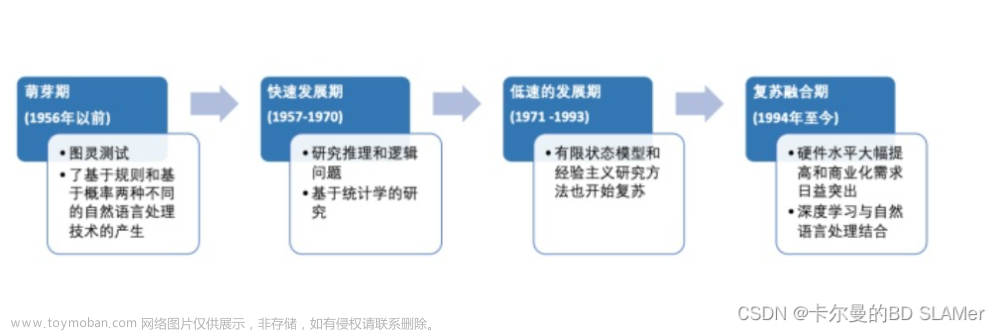
1.背景介绍
自然语言处理(NLP)是人工智能(AI)领域的一个重要分支,它涉及到计算机理解、生成和处理人类语言的能力。自从2010年左右,NLP技术在深度学习和大数据技术的推动下发生了巨大的变革,这使得许多之前只能由专业人士完成的任务现在可以由计算机自动完成。
在过去的几年里,我们已经看到了许多令人印象深刻的NLP应用,如语音助手(如Siri和Alexa)、机器翻译、情感分析和文本摘要等。然而,这些应用仍然只是NLP技术在人类语言理解和生成方面的初步探索。在未来,我们可以期待更多高级的NLP任务得到解决,例如自然语言对话系统、知识图谱构建和机器创作等。
在本文中,我们将讨论NLP的未来发展趋势和挑战,并深入探讨一些核心算法和技术。我们将从以下几个方面入手:
- 背景介绍
- 核心概念与联系
- 核心算法原理和具体操作步骤以及数学模型公式详细讲解
- 具体代码实例和详细解释说明
- 未来发展趋势与挑战
- 附录常见问题与解答
2. 核心概念与联系
在本节中,我们将介绍一些NLP的核心概念,包括语料库、词嵌入、序列到序列模型和自注意力机制等。这些概念将为我们的后续讨论奠定基础。
2.1 语料库
语料库是NLP任务中的一种数据集,包含了大量的人类语言数据,如文本、语音、视频等。这些数据可以用于训练和测试NLP模型,以便让模型学习人类语言的结构和语义。
常见的语料库包括:
- 新闻文本:如《纽约时报》、《华盛顿邮报》等。
- 社交媒体:如Twitter、Facebook、微博等。
- 语音数据:如Google Speech Commands Dataset、Common Voice Dataset等。
2.2 词嵌入
词嵌入是将词语映射到一个连续的高维向量空间的技术,这些向量可以捕捉到词语之间的语义关系。最早的词嵌入方法是Word2Vec,后来出现了GloVe、FastText等其他方法。
词嵌入有以下特点:
- 高维:通常使用100-300维的向量空间。
- 连续:向量空间中的点是连续的,可以通过线性插值得到新的词向量。
- 语义:相似的词语具有相似的向量。
2.3 序列到序列模型
序列到序列模型(Sequence-to-Sequence Models)是一种用于处理输入序列到输出序列的模型,这种模型通常用于机器翻译、文本摘要等任务。最早的序列到序列模型是基于循环神经网络(RNN)的,后来出现了基于Transformer的模型。
序列到序列模型的主要组件包括:
- 编码器:将输入序列编码为固定长度的隐藏表示。
- 解码器:将隐藏表示解码为输出序列。
2.4 自注意力机制
自注意力机制(Self-Attention)是一种用于关注序列中不同位置的元素的技术,这种技术可以在序列到序列模型中大大提高性能。自注意力机制的核心是计算一个位置的权重,以便将其与其他位置相关的元素相关联。
自注意力机制的主要组件包括:
- 查询(Query):用于表示当前位置的向量。
- 键(Key):用于表示序列中其他位置的向量。
- 值(Value):用于表示序列中其他位置的向量。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
在本节中,我们将详细讲解一些核心算法,包括词嵌入、序列到序列模型和自注意力机制等。
3.1 词嵌入
3.1.1 Word2Vec
Word2Vec是一种基于连续词嵌入的统计方法,它通过最大化词语在上下文中的相似度来学习词嵌入。Word2Vec的两种主要实现是Continuous Bag of Words(CBOW)和Skip-Gram。
3.1.1.1 Continuous Bag of Words(CBOW)
CBOW是一种基于上下文的词嵌入学习方法,它将一个词的上下文视为一个bag,然后将这个bag映射到目标词。具体操作步骤如下:
- 从语料库中随机选择一个中心词。
- 从中心词周围的一定范围内随机选择上下文词。
- 将上下文词表示为一个bag,即一个一维向量,其中每个元素表示词的出现次数。
- 使用一个多层感知器(MLP)模型将bag映射到目标词。
- 最大化目标词出现的概率,即最大化:$$ P(wi | wj) = \frac{exp(wi^T \cdot h(wj))}{\sum{wk \in V} exp(wk^T \cdot h(wj)))}$$,其中$wi$和$wj$分别表示中心词和目标词,$h(w_j)$表示对应的向量。
3.1.1.2 Skip-Gram
Skip-Gram是一种基于目标词的词嵌入学习方法,它将一个词的上下文视为一个bag,然后将这个bag映射到目标词。具体操作步骤如下:
- 从语料库中随机选择一个中心词。
- 从中心词周围的一定范围内随机选择上下文词。
- 将上下文词表示为一个bag,即一个一维向量,其中每个元素表示词的出现次数。
- 使用一个多层感知器(MLP)模型将bag映射到目标词。
- 最大化中心词出现的概率,即最大化:$$ P(wj | wi) = \frac{exp(wi^T \cdot h(wj))}{\sum{wk \in V} exp(wk^T \cdot h(wj)))}$$,其中$wi$和$wj$分别表示中心词和目标词,$h(w_j)$表示对应的向量。
3.1.2 GloVe
GloVe是一种基于统计的词嵌入学习方法,它通过最大化词语在上下文中的相似度来学习词嵌入。GloVe的主要区别在于它使用了一种特殊的统计模型,即词语在上下文中的相似度。
GloVe的具体操作步骤如下:
- 从语料库中构建一个词频矩阵,其中行表示词语,列表示上下文词语,元素表示词语出现次数。
- 使用奇异值分解(SVD)对词频矩阵进行降维,得到一个低维的词嵌入矩阵。
- 最大化词嵌入矩阵与原始词频矩阵之间的相关性,即最大化:$$ \sum{i,j} (wi^T \cdot h(wj)) \cdot c{i,j}$$,其中$wi$和$wj$分别表示词嵌入向量,$c_{i,j}$表示原始词频矩阵的元素。
3.1.3 FastText
FastText是一种基于统计的词嵌入学习方法,它通过最大化词语在上下文中的相似度来学习词嵌入。FastText的主要区别在于它使用了一种特殊的统计模型,即词语在上下文中的相似度。
FastText的具体操作步骤如下:
- 从语料库中构建一个词频矩阵,其中行表示词语,列表示上下文词语,元素表示词语出现次数。
- 使用奇异值分解(SVD)对词频矩阵进行降维,得到一个低维的词嵌入矩阵。
- 最大化词嵌入矩阵与原始词频矩阵之间的相关性,即最大化:$$ \sum{i,j} (wi^T \cdot h(wj)) \cdot c{i,j}$$,其中$wi$和$wj$分别表示词嵌入向量,$c_{i,j}$表示原始词频矩阵的元素。
3.2 序列到序列模型
3.2.1 RNN
递归神经网络(RNN)是一种用于处理序列数据的神经网络,它可以通过循环状的结构捕捉到序列中的长距离依赖关系。RNN的主要组件包括:
- 隐藏层:用于存储序列中的信息。
- 输入层:用于接收输入序列。
- 输出层:用于生成输出序列。
RNN的具体操作步骤如下:
- 初始化隐藏层状态。
- 对于每个时间步,执行以下操作:
- 将输入序列的当前元素传递到输入层。
- 通过输入层得到隐藏层的输出。
- 将隐藏层的输出传递到输出层。
- 更新隐藏层状态。
- 得到输出序列。
3.2.2 LSTM
长短期记忆(LSTM)是一种特殊的RNN,它使用了门机制来控制信息的流动,从而能够更好地捕捉到序列中的长距离依赖关系。LSTM的主要组件包括:
- 输入门:用于决定哪些信息应该被保留。
- 遗忘门:用于决定哪些信息应该被忘记。
- 更新门:用于决定哪些信息应该被更新。
LSTM的具体操作步骤如下:
- 初始化隐藏层状态。
- 对于每个时间步,执行以下操作:
- 将输入序列的当前元素传递到输入门。
- 通过输入门得到新的隐藏层状态。
- 将新的隐藏层状态传递到遗忘门。
- 通过遗忘门得到旧的隐藏层状态。
- 将旧的隐藏层状态传递到更新门。
- 通过更新门得到新的隐藏层状态。
- 将新的隐藏层状态传递到输出门。
- 通过输出门得到输出序列。
- 更新隐藏层状态。
- 得到输出序列。
3.2.3 GRU
门控递归单元(GRU)是一种简化的LSTM,它使用了一个门来替换输入门、遗忘门和更新门。GRU的主要组件包括:
- 更新门:用于决定哪些信息应该被更新。
- 合并门:用于决定哪些信息应该被合并。
GRU的具体操作步骤如下:
- 初始化隐藏层状态。
- 对于每个时间步,执行以下操作:
- 将输入序列的当前元素传递到更新门。
- 通过更新门得到新的隐藏层状态。
- 将新的隐藏层状态传递到合并门。
- 通过合并门得到旧的隐藏层状态。
- 将旧的隐藏层状态与新的隐藏层状态相加。
- 得到输出序列。
- 更新隐藏层状态。
- 得到输出序列。
3.3 自注意力机制
自注意力机制是一种用于关注序列中不同位置的元素的技术,它可以在序列到序列模型中大大提高性能。自注意力机制的核心是计算一个位置的权重,以便将其与其他位置相关的元素相关联。
自注意力机制的具体操作步骤如下:
- 对于每个位置,计算其与其他位置相关的元素的权重。
- 将权重与相关元素相乘,得到一个新的序列。
- 将新的序列传递到解码器。
- 重复步骤1-3,直到生成完整的输出序列。
4. 具体代码实例和详细解释说明
在本节中,我们将通过一个简单的例子来演示NLP任务的实现。我们将使用Python的NLTK库来实现一个文本分类任务。
```python import nltk from nltk.classify import NaiveBayesClassifier from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
加载数据集
data = open("reviews.txt", "r").read().split("\n") labels = [label.split("-")[0] for label in data] reviews = [label.split("-")[1] for label in data]
预处理
stopwords = set(stopwords.words("english")) reviews = [wordtokenize(review.lower()) for review in reviews] reviews = [[word for word in review if word not in stop_words] for review in reviews]
特征提取
featuresets = [({word: (word in review) for word in vocabulary}, label) for label in labels for review in reviews for vocabulary in [set(word_tokenize(review.lower()))]}
训练分类器
classifier = NaiveBayesClassifier.train(featuresets)
测试分类器
testreview = "This is an amazing product!" testfeatures = ({word: (word in review) for word in vocabulary}, label) probabilities = classifier.probclassify(testfeatures) print("Predicted label: %s" % probabilities.max()) ```
在上述代码中,我们首先导入了NLTK库,并加载了一个文本分类任务的数据集。接着,我们对数据集进行了预处理,包括将文本转换为小写、分词、去除停用词等。然后,我们将文本转换为特征集,并使用朴素贝叶斯分类器进行训练。最后,我们使用一个测试句子来测试分类器的性能。
5. 未来发展趋势与挑战
在本节中,我们将讨论NLP的未来发展趋势和挑战,包括数据问题、模型问题和应用问题等。
5.1 数据问题
NLP的数据问题主要包括数据质量、数据量和数据多样性等方面。这些问题限制了NLP模型的性能和泛化能力。为了解决这些问题,我们需要:
- 提高数据质量:通过数据清洗、噪声去除、缺失值处理等方法来提高数据质量。
- 增加数据量:通过数据扩充、生成等方法来增加数据量。
- 增加数据多样性:通过收集来自不同来源、语言、文化等的数据来增加数据多样性。
5.2 模型问题
NLP的模型问题主要包括模型复杂度、模型解释性和模型鲁棒性等方面。这些问题限制了NLP模型的性能和可靠性。为了解决这些问题,我们需要:
- 优化模型结构:通过模型压缩、剪枝等方法来减少模型复杂度。
- 提高模型解释性:通过使用可解释性模型、输出解释性等方法来提高模型解释性。
- 增强模型鲁棒性:通过使用鲁棒性分析、稳定性分析等方法来增强模型鲁棒性。
5.3 应用问题
NLP的应用问题主要包括应用场景、应用难度和应用效果等方面。这些问题限制了NLP技术在实际应用中的效果。为了解决这些问题,我们需要:
- 拓展应用场景:通过研究新的应用场景、创新的应用方法等方法来拓展应用场景。
- 降低应用难度:通过自动化、标准化、开源等方法来降低应用难度。
- 提高应用效果:通过优化模型性能、提高模型效果、评估模型效果等方法来提高应用效果。
6. 附录
在本附录中,我们将回答一些常见问题。
6.1 自然语言处理与人工智能的关系
自然语言处理(NLP)是人工智能(AI)的一个子领域,它涉及到人类语言和机器之间的交互。NLP的目标是使计算机能够理解、生成和翻译人类语言。NLP的应用范围广泛,包括语音识别、机器翻译、文本摘要、情感分析等。
6.2 自然语言处理与深度学习的关系
深度学习是一种人工智能技术,它旨在模拟人类大脑中的神经网络。深度学习的主要优点是它能够自动学习特征,无需人工手动提取。自然语言处理(NLP)与深度学习的关系主要表现在以下几个方面:
- 深度学习在自然语言处理中的应用:深度学习已经成功应用于自然语言处理中的许多任务,如文本分类、情感分析、机器翻译等。
- 深度学习在自然语言处理中的挑战:深度学习在自然语言处理中面临的挑战包括数据问题、模型问题等。
- 深度学习在自然语言处理中的发展趋势:未来,深度学习将继续在自然语言处理中发展,尤其是在语音识别、机器翻译、文本摘要等领域。
6.3 自然语言处理与知识图谱的关系
知识图谱是一种用于表示实体、关系和事实的数据结构。知识图谱的主要优点是它能够捕捉到实体之间的关系,从而实现语义理解。自然语言处理(NLP)与知识图谱的关系主要表现在以下几个方面:
- 知识图谱在自然语言处理中的应用:知识图谱已经成功应用于自然语言处理中的许多任务,如问答系统、推荐系统、情感分析等。
- 知识图谱在自然语言处理中的挑战:知识图谱在自然语言处理中面临的挑战包括数据问题、模型问题等。
- 知识图谱在自然语言处理中的发展趋势:未来,知识图谱将继续在自然语言处理中发展,尤其是在语义理解、情感分析、问答系统等领域。
6.4 自然语言处理与语音识别的关系
语音识别是自然语言处理(NLP)的一个重要子领域,它涉及到将人类语音信号转换为文本的过程。语音识别的主要优点是它能够实现语音输入,从而提高用户体验。自然语言处理与语音识别的关系主要表现在以下几个方面:
- 语音识别在自然语言处理中的应用:语音识别已经成功应用于自然语言处理中的许多任务,如语音搜索、语音助手、语音摘要等。
- 语音识别在自然语言处理中的挑战:语音识别在自然语言处理中面临的挑战包括数据问题、模型问题等。
- 语音识别在自然语言处理中的发展趋势:未来,语音识别将继续在自然语言处理中发展,尤其是在语音搜索、语音助手、语音摘要等领域。
6.5 自然语言处理与机器翻译的关系
机器翻译是自然语言处理(NLP)的一个重要子领域,它涉及到将一种自然语言翻译成另一种自然语言的过程。机器翻译的主要优点是它能够实现跨语言沟通,从而扩大应用范围。自然语言处理与机器翻译的关系主要表现在以下几个方面:
- 机器翻译在自然语言处理中的应用:机器翻译已经成功应用于自然语言处理中的许多任务,如文本摘要、文本翻译、机器翻译等。
- 机器翻译在自然语言处理中的挑战:机器翻译在自然语言处理中面临的挑战包括数据问题、模型问题等。
- 机器翻译在自然语言处理中的发展趋势:未来,机器翻译将继续在自然语言处理中发展,尤其是在文本摘要、文本翻译、机器翻译等领域。
7. 参考文献
[1] Mikolov, T., Chen, K., & Kurata, G. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781.
[2] Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. arXiv preprint arXiv:1406.1078.
[3] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[4] Vaswani, A., Shazeer, N., Parmar, N., & Jones, L. (2017). Attention is all you need. arXiv preprint arXiv:1706.03762.
[5] Bengio, Y., Courville, A., & Vincent, P. (2012). Deep Learning. MIT Press.
[6] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
[7] LeCun, Y., Bengio, Y., & Hinton, G. E. (2015). Deep learning. Nature, 521(7553), 436-444.
[8] Goldberg, Y., & Huang, X. (2017). Neural Machine Translation of Long Sentences with Convolutional Kernels. arXiv preprint arXiv:1703.03151.
[9] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. arXiv preprint arXiv:1409.3215.
[10] Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv preprint arXiv:1406.1078.
[11] Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv preprint arXiv:1412.3555.
[12] Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
[13] Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv preprint arXiv:1406.1078.
[14] Bahdanau, D., Bahdanau, K., & Chung, J. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv preprint arXiv:1409.0942.
[15] Vaswani, A., Shazeer, N., Parmar, N., & Jones, L. (2017). Attention is all you need. arXiv preprint arXiv:1706.03762.
[16] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[17] Radford, A., Vaswani, S., & Yu, J. (2018). Improving language understanding through self-supervised learning with transformer models. arXiv preprint arXiv:1810.04805.
[18] Liu, Y., Dong, H., Qi, X., & Li, L. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
[19] Brown, M., & Mercer, R. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
[20] Radford, A., Kharitonov, I., & Hughes, J. (2021). Language Models Are Now Our Masters?? arXiv preprint arXiv:2102.02847.
[21] Liu, Y., Dong, H., Qi, X., & Li, L. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
[22] Radford, A., Kharitonov, I., & Hughes, J. (2021). Language Models Are Now Our Masters?? arXiv preprint arXiv:2102.02847.
[23] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.文章来源:https://www.toymoban.com/news/detail-834422.html
[24] Radford,文章来源地址https://www.toymoban.com/news/detail-834422.html
到了这里,关于自然语言处理的未来:从语音助手到人工智能的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!