目录
unordered_map
1. pair类型
2. 关联式容器额外的类型别名
3. 哈希桶
4. 无序容器对关键字类型的要求
5. Member functions
5.1 constructor、destructor、operator=
5.1.1 constructor
5.1.2 destructor
5.1.3 operator=
5.2 Capacity
5.2.1 empty
5.2.2 size
5.2.3 max_size
5.3 Iterators
5.4 Element access
5.4.1 operator[]
5.4.2 at
5.5 Element lookup
5.5.1 find
5.5.2 count
5.5.3 equal_range
5.6 Modifiers
5.6.1 emplace
5.6.2 emplace_hint
5.6.3 insert
5.6.4 erase
5.6.5 clear
5.6.6 swap
5.7 Buckets
5.7.1 bucket_count
5.7.2 max_bucket_count
5.7.3 bucket_size
5.7.4 bucket
5.8 Hash policy
5.8.1 load_factor
5.8.2 max_load_factor
5.8.3 rehash
5.8.4 reserve
5.9 Observers
5.9.1 hash_function
5.9.2 key_eq
5.9.3 get_allocator
6. Non-member function overloads
6.1 operators
6.2 swap
7. unordered_map对象的插入方法
8. unordered_map对象的遍历方法
8.1 迭代器
8.2 范围for
unordered_map
template < class Key, // unordered_map::key_type
class T, // unordered_map::mapped_type
class Hash = hash<Key>, // unordered_map::hasher
class Pred = equal_to<Key>, // unordered_map::key_equal
class Alloc = allocator< pair<const Key, T> > // unordered_map::allocator_type
> class unordered_map;unordered_map是一种关联式容器,存储由键值和映射值组合而成的元素,允许根据键快速检索单个元素。
在unordered_map中,键值通常用于唯一标识元素,而映射值是与该键相关联的内容的对象。键和映射值的类型可能不同。
在内部,unordered_map中的元素并没有按照键或映射值的任何特定顺序排序,而是根据它们的哈希值组织成桶,以允许直接通过键值快速访问各个元素(平均时间复杂度是常数)。
在通过键访问单个元素时,unordered_map容器比map容器更快,尽管在通过其元素子集进行范围迭代时通常效率较低。
unordered_map实现了直接访问操作符(operator[]),允许使用其键值作为参数直接访问映射值。
容器中的迭代器至少是前向迭代器。
unordered_map定义在头文件unordered_map和命名空间std中。

1. pair类型
pair定义在头文件utility和命名空间std中。
一个pair保存两个数据成员。类似容器,pair是一个用来生成特定类型的模板。当创建一个pair时,我们必须提供两个类型名,pair的数据成员将具有对应的类型。两个类型不要求一样:
pair<string, string> anon; // 保存两个string
pair<string, size_t> word_count; // 保存一个string和一个size_t
pair<string, vector<int>> line; // 保存string和vector<int>pair的默认构造函数对数据成员进行值初始化。因此,anon是一个包含两个空string的pair,line保存一个空string和一个空vector。word_count中的size_t成员值为0,而string成员被初始化为空。
我们也可以为每个成员提供初始化器:
pair<string, string> author{ "James","Joyce" };这条语句创建一个名为author的pair,两个成员被初始化为"James"和"Joyce"。
与其他标准库类型不同,pair的数据成员是public的。两个成员分别命名为first和second。我们用普通的成员访问符号来访问它们。
| pair<T1, T2> p; | p是一个pair,两个类型分别为T1和T2的成员都进行了值初始化 |
| pair<T1, T2> p(v1, v2); | p是一个成员类型为T1和T2的pair first和second成员分别用v1和v2进行初始化 |
| pair<T1, T2> p = { v1,v2 }; | 等价于pair<T1, T2> p(v1, v2); |
| make_pair(v1, v2) | 返回一个用v1和v2初始化的pair pair的类型从v1和v2的类型推断出来 |
| p.first | 返回p的名为first的(公有)数据成员 |
| p.second | 返回p的名为second的(公有)数据成员 |
| p1 relop p2 | 关系运算符(<、>、<=、>=)按字典序定义 |
| p1 == p2 p1 != p2 |
当first和second成员分别相等时,两个pair相等 相等性判断利用元素的==运算符实现 |
创建pair对象的函数:
想象有一个函数需要返回一个pair。在新标准下,我们可以对返回值进行列表初始化:
pair<string, int> process(vector<string>& v)
{
// 处理v
if (!v.empty())
return { v.back(), v.back().size() }; // 列表初始化
else
return pair<string, int>(); // 隐式构造返回值
}若v不为空,我们返回一个由v中最后一个string及其大小组成的pair。否则,隐式构造一个空pair,并返回它。
在较早的C++版本中,不允许用花括号包围的初始化器来返回pair这种类型的对象,必须显式构造返回值:
if (!v.empty())
return pair<string, int>(v.back(), v.back().size());我们还可以用make_pair来生成pair对象,pair的两个类型来自于make_pair的参数:
if (!v.empty())
return make_pair(v.back(), v.back().size());2. 关联式容器额外的类型别名
| key_type | 此容器类型的关键字类型 |
| mapped_type | 每个关键字关联的类型;只适用于map |
| value_type | 对于set,与key_type相同 对于map,为pair<const key_type, mapped_type> |
对于set类型,key_type和value_type是一样的:set中保存的值就是关键字。在一个map中,元素是键值对。即,每个元素是一个pair对象,包含一个关键字和一个关联的值。由于我们不能改变一个元素的关键字,因此这些pair的关键字部分是const的:
set<string>::value_type vl; // v1是一个string
set<string>::key_type v2; // v2是一个string
map<string, int>::value_type v3; // v3是一个pair<const string, int>
map<string, int>::key_type v4; // v4是一个string
map<string, int>::mapped_type v5; // v5是一个int与序列式容器一样,我们使用作用域运算符来提取一个类型的成员——例如,map<string, int>::key_type。
只有map类型(unordered_map、unordered_multimap、multimap和map)才定义了mapped_type。
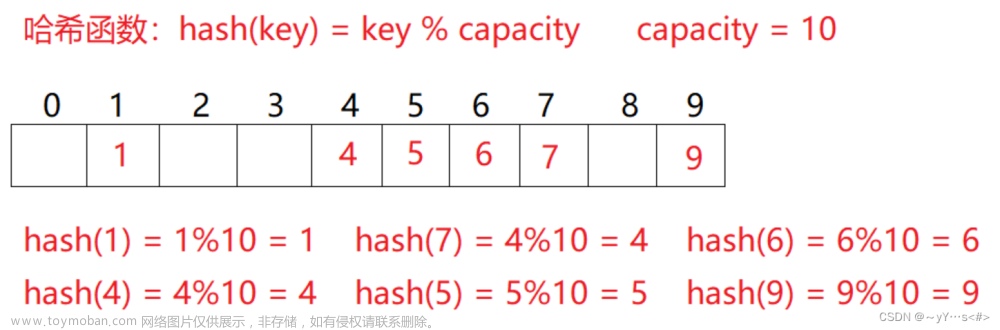
3. 哈希桶
无序容器在存储上组织为一组桶,每个桶保存零个或多个元素。无序容器使用一个哈希函数将元素映射到桶。为了访问一个元素,容器首先计算元素的哈希值,它指出应该搜索哪个桶。容器将具有一个特定哈希值的所有元素都保存在相同的桶中。如果容器允许重复关键字,所有具有相同关键字的元素也都会在同一个桶中。因此,无序容器的性能依赖于哈希函数的质量和桶的数量和大小。
对于相同的参数,哈希函数必须总是产生相同的结果。理想情况下,哈希函数还能将每个特定的值映射到唯一的桶。但是,将不同关键字的元素映射到相同的桶也是允许的。当一个桶保存多个元素时,需要顺序搜索这些元素来查找我们想要的那个。计算一个元素的哈希值和在桶中搜索通常都是很快的操作。但是,如果一个桶中保存了很多元素,那么查找一个特定元素就需要大量比较操作。
4. 无序容器对关键字类型的要求
默认情况下,无序容器使用关键字类型的==运算符来比较元素,它们还使用一个hash<key_type>类型的对象来生成每个元素的哈希值。标准库为内置类型(包括指针)提供了hash模板。还为一些标准库类型,包括string和智能指针类型定义了hash。因此,我们可以直接定义关键字是内置类型(包括指针类型)、string还有智能指针类型的无序容器。
但是,我们不能直接定义关键字类型为自定义类类型的无序容器。与容器不同,不能直接使用哈希模板,而必须提供我们自己的hash模板版本。
5. Member functions
5.1 constructor、destructor、operator=
5.1.1 constructor
// empty (1)
explicit unordered_map(size_type n,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type());
explicit unordered_map(const allocator_type& alloc);
// range (2)
template <class InputIterator>
unordered_map(InputIterator first, InputIterator last,
size_type n,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type());
// copy (3)
unordered_map(const unordered_map& ump);
unordered_map(const unordered_map& ump, const allocator_type& alloc);
// move (4)
unordered_map(unordered_map&& ump);
unordered_map(unordered_map&& ump, const allocator_type& alloc);
// initializer list (5)
unordered_map(initializer_list<value_type> il,
size_type n,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type());
// n表示初始桶的最小数量,不是容器中元素的数量5.1.2 destructor
~unordered_map();5.1.3 operator=
// copy (1)
unordered_map& operator=(const unordered_map& ump);
// move (2)
unordered_map& operator=(unordered_map&& ump);
// initializer list (3)
unordered_map& operator=(intitializer_list<value_type> il);5.2 Capacity
5.2.1 empty
bool empty() const noexcept;
// 检测unordered_map是否为空,是返回true,否则返回false5.2.2 size
size_type size() const noexcept;
// 返回unordered_map中元素的个数5.2.3 max_size
size_type max_size() const noexcept;
// 返回unordered_map能够容纳的最大元素个数5.3 Iterators
// begin
// container iterator (1)
iterator begin() noexcept;
const_iterator begin() const noexcept;
// bucket iterator (2)
local_iterator begin(size_type n);
const_local_iterator begin(size_type n) const;
// end
// container iterator (1)
iterator end() noexcept;
const_iterator end() const noexcept;
// bucket iterator (2)
local_iterator end(size_type n);
const_local_iterator end(size_type n) const;
// cbegin
// container iterator (1)
const_iterator cbegin() const noexcept;
// bucket iterator (2)
const_local_iterator cbegin(size_type n) const;
// cend
// container iterator (1)
const_iterator cend() const noexcept;
// bucket iterator (2)
const_local_iterator cend(size_type n) const;| 函数 | 功能 |
|---|---|
| begin & end |
(1)版本begin返回一个迭代器,指向unordered_map中第一个元素 (2)版本begin返回一个迭代器,指向unordered_map中桶n的第一个元素 (1)版本end返回一个迭代器,指向unordered_map中最后一个元素的下一个位置 (2)版本end返回一个迭代器,指向unordered_map中桶n的最后一个元素的下一个位置 |
| cbegin & cend |
(1)版本cbegin返回一个const迭代器,指向unordered_map中第一个元素 (2)版本cbegin返回一个const迭代器,指向unordered_map中桶n的第一个元素 (1)版本cend返回一个const迭代器,指向unordered_map中最后一个元素的下一个位置 (2)版本cend返回一个const迭代器,指向unordered_map中桶n的最后一个元素的下一个位置文章来源:https://www.toymoban.com/news/detail-834673.html |
#include <unordered_map>
#include <iostream>
using namespace std;
int main()
{
unordered_map<string, string> ump{ {"iterator","迭代器"},{"begin","开始"},{"end","结束"} };
cout << "ump contains:" << endl;
unordered_map<string, string>::iterator it = ump.begin();
while (it != ump.end())
{
cout << it->first << " " << it->second << endl;
// 等价于cout << (*it).first << " " << (*it).second << endl;
++it;
}
// ump contains :
// iterator 迭代器
// begin 开始
// end 结束
cout << "ump's buckets contain:" << endl;
for (int i = 0; i < ump.bucket_count(); ++i)
{
cout << "bucket #" << i << " contains:";
unordered_map<string, string>::local_iterator lit = ump.begin(i);
while (lit != ump.end(i))
{
cout << " " << lit->first << " " << lit->second;
// 等价于cout << " " << (*lit).first << " " << (*lit).second;
++lit;
}
cout << endl;
}
// ump's buckets contain:
// bucket #0 contains:
// bucket #1 contains:
// bucket #2 contains: end 结束
// bucket #3 contains:
// bucket #4 contains:
// bucket #5 contains:
// bucket #6 contains: begin 开始
// bucket #7 contains: iterator 迭代器
return 0;
}5.4 Element access
5.4.1 operator[]
mapped_type& operator[](const key_type& k);
mapped_type& operator[](key_type&& k);
// 如果k与某个元素的关键字相匹配,返回对其映射值的引用
// 如果k与任何元素的关键字不匹配,插入一个关键字为k的新元素,并返回对其映射值的引用5.4.2 at
mapped_type& at(const key_type& k);
const mapped_type& at(const key_type& k) const;
// 如果k与某个元素的关键字相匹配,返回对其映射值的引用
// 如果k与任何元素的关键字不匹配,抛异常Element access系列函数使用示例:文章来源地址https://www.toymoban.com/news/detail-834673.html
#include <unordered_map>
#include <iostream>
using namespace std;
int main()
{
unordered_map<char, int> ump;
ump['b']; // 插入一个关键字为'b'的元素,但没有对映射值进行初始化
ump['d'] = 20; // 插入一个关键字为'd'的元素,并将映射值初始化为20
cout << "ump['b'] = " << ump['b'] << endl; // ump['b'] = 0
cout << "ump['d'] = " << ump['d'] << endl; // ump['d'] = 20
ump['b'] = 50; // 修改关键字为'b'的元素的映射值为50
cout << "ump['b'] = " << ump.at('b') << endl; // ump['b'] = 50
cout << "ump['d'] = " << ump.at('d') << endl; // ump['d'] = 20
return 0;
}5.5 Element lookup
5.5.1 find
iterator find(const key_type& k);
const_iterator find(const key_type& k) const;
// 返回一个迭代器,指向第一个关键字为k的元素,若k不在容器中,则返回end迭代器5.5.2 count
size_type count(const key_type& k) const;
// 返回关键字等于k的元素的数量
// 对于不允许重复关键字的容器,返回值永远是0或1#include <unordered_map>
#include <iostream>
using namespace std;
int main()
{
unordered_map<char, int> ump;
ump.insert({ 'g',30 });
ump.insert(make_pair('a', 10));
ump.insert(pair<char, int>('f', 50));
ump['b'];
ump['d'] = 20;
auto it = ump.find('f');
if (it != ump.end())
{
cout << "f在unordered_map中" << endl;
}
else
{
cout << "f不在unordered_map中" << endl;
}
// f在unordered_map中
it = ump.find('h');
if (it != ump.end())
{
cout << "h在unordered_map中" << endl;
}
else
{
cout << "h不在unordered_map中" << endl;
}
// h不在unordered_map中
if (ump.count('a'))
{
cout << "a在unordered_map中" << endl;
}
else
{
cout << "a不在unordered_map中" << endl;
}
// a在unordered_map中
if (ump.count('c'))
{
cout << "c在unordered_map中" << endl;
}
else
{
cout << "c不在unordered_map中" << endl;
}
// c不在unordered_map中
return 0;
}5.5.3 equal_range
pair<iterator, iterator> equal_range(const key_type& k);
pair<const_iterator, const_iterator> equal_range(const key_type& k) const;
// 返回一个迭代器pair,表示关键字等于k的元素的范围(左闭右开的区间)
// 若k不存在,pair的两个成员均为end迭代器
// 对于不允许重复关键字的容器,返回的范围最多只包含一个元素5.6 Modifiers
5.6.1 emplace
template <class... Args> pair<iterator, bool> emplace(Args&&... args);
// 对应insert,区别是:
// 当调用insert时,我们将元素类型的对象传递给它们,这些对象被拷贝到容器中
// 当调用emplace时,则是将参数传递给元素类型的构造函数,然后使用这些参数在容器管理的内存空间中直接构造元素5.6.2 emplace_hint
template <class... Args> iterator emplace_hint(const_iterator position, Args&&... args);
// 对应insert的(3)和(4),区别是:
// 当调用insert时,我们将元素类型的对象传递给它们,这些对象被拷贝到容器中
// 当调用emplace时,则是将参数传递给元素类型的构造函数,然后使用这些参数在容器管理的内存空间中直接构造元素5.6.3 insert
// (1) 成功返回pair<插入位置, true>,失败返回pair<插入位置, false>
pair<iterator, bool> insert(const value_type& val);
// (2)
template <class P> pair<iterator, bool> insert(P&& val);
// (3)
iterator insert(const_iterator hint, const value_type& val);
// (4)
template <class P> iterator insert(const_iterator hint, P&& val);
// (5)
template <class InputIterator> void insert(InputIterator first, InputIterator last);
// (6)
void insert(initializer_list<value_type> il);
// 插入5.6.4 erase
// by position(1)
iterator erase(const_iterator position);
// by key(2)
size_type erase(const key_type& k);
// range(3)
iterator erase(const_iterator first, const_iterator last);
// 删除5.6.5 clear
void clear() noexcept;
// 清空5.6.6 swap
void swap(unordered_map& ump);
// 交换5.7 Buckets
5.7.1 bucket_count
size_type bucket_count() const noexcept;
// 返回unordered_map中桶的个数5.7.2 max_bucket_count
size_type max_bucket_count() const noexcept;
// 返回unordered_map能够容纳的最大桶个数5.7.3 bucket_size
size_type bucket_size(size_type n) const;
// 返回桶n中元素的个数5.7.4 bucket
size_type bucket(const key_type& k) const;
// 返回关键字为k的元素所在的桶号5.8 Hash policy
5.8.1 load_factor
float load_factor() const noexcept;
// 返回负载因子(每个桶平均元素的数量,元素的数量/桶的数量)5.8.2 max_load_factor
// get(1)
float max_load_factor() const noexcept;
// set(2)
void max_load_factor(float z);
// 获取或设置最大负载因子5.8.3 rehash
void rehash(size_type n);
// 设置桶的数量5.8.4 reserve
void reserve(size_type n);
// 将桶数设置为最适合包含至少n个元素的桶数5.9 Observers
5.9.1 hash_function
hasher hash_function() const;
// 返回哈希函数5.9.2 key_eq
key_equal key_eq() const;
// 返回关键字等价比较谓词5.9.3 get_allocator
allocator_type get_allocator() const noexcept;
// 返回空间配置器6. Non-member function overloads
6.1 operators
// equality (1)
template <class Key, class T, class Hash, class Pred, class Alloc>
bool operator==(const unordered_map<Key, T, Hash, Pred, Alloc>& lhs, const unordered_map<Key, T, Hash, Pred, Alloc>& rhs);
// inequality (2)
template <class Key, class T, class Hash, class Pred, class Alloc>
bool operator!=(const unordered_map<Key, T, Hash, Pred, Alloc>& lhs, const unordered_map<Key, T, Hash, Pred, Alloc>& rhs);6.2 swap
template <class Key, class T, class Hash, class Pred, class Alloc>
void swap(unordered_map<Key, T, Hash, Pred, Alloc>& lhs, unordered_map<Key, T, Hash, Pred, Alloc>& rhs);7. unordered_map对象的插入方法
#include <unordered_map>
#include <iostream>
using namespace std;
int main()
{
unordered_map<char, int> ump;
// 插入
ump.insert({ 'g',30 });
ump.insert(make_pair('a', 10));
ump.insert(pair<char, int>('f', 50));
ump.insert(unordered_map<char, int>::value_type('h', 70));
ump['b'];
ump['d'] = 20;
for (auto& e : ump)
{
cout << e.first << " " << e.second << endl;
}
// g 30
// a 10
// f 50
// h 70
// b 0
// d 20
return 0;
}8. unordered_map对象的遍历方法
8.1 迭代器
#include <unordered_map>
#include <iostream>
using namespace std;
int main()
{
unordered_map<char, int> ump;
// 插入
ump.insert({ 'g',30 });
ump.insert(make_pair('a', 10));
ump.insert(pair<char, int>('f', 50));
ump.insert(unordered_map<char, int>::value_type('h', 70));
ump['b'];
ump['d'] = 20;
unordered_map<char, int>::iterator it = ump.begin();
while (it != ump.end())
{
cout << it->first << " " << it->second << endl;
++it;
}
// g 30
// a 10
// f 50
// h 70
// b 0
// d 20
return 0;
}8.2 范围for
#include <unordered_map>
#include <iostream>
using namespace std;
int main()
{
unordered_map<char, int> ump;
// 插入
ump.insert({ 'g',30 });
ump.insert(make_pair('a', 10));
ump.insert(pair<char, int>('f', 50));
ump.insert(unordered_map<char, int>::value_type('h', 70));
ump['b'];
ump['d'] = 20;
for (auto& e : ump)
{
cout << e.first << " " << e.second << endl;
}
// g 30
// a 10
// f 50
// h 70
// b 0
// d 20
return 0;
}#include <unordered_map>
#include <iostream>
using namespace std;
int main()
{
unordered_map<char, int> ump;
// 插入
ump.insert({ 'g',30 });
ump.insert(make_pair('a', 10));
ump.insert(pair<char, int>('f', 50));
ump.insert(unordered_map<char, int>::value_type('h', 70));
ump['b'];
ump['d'] = 20;
for (auto& [x, y] : ump) // C++17 结构化绑定
{
cout << x << " " << y << endl;
}
// g 30
// a 10
// f 50
// h 70
// b 0
// d 20
return 0;
}到了这里,关于【C++关联式容器】unordered_map的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![【C++入门到精通】哈希 (STL) _ unordered_map _ unordered_set [ C++入门 ]](https://imgs.yssmx.com/Uploads/2024/02/714971-1.jpeg)



